
Taboola is responsible for billions of daily recommendations, and we are doing everything we can to make those recommendations fit each viewer’s personal taste and interests. We do so by updating our Deep-Learning based models, increasing our computational resources, improving our exploration techniques and many more. All those things though, have one thing in common – we need to understand if a change is for the better or not, and we need to do so while allowing many tests to run in parallel. We can think of many KPI’s for new algorithmic modifications – system latency, diversity of recommendations or user-interaction to name a few – but at the end of the day, the one metric that matters most for us in Taboola is RPM (revenue per mill, or revenue per 1,000 recommendations), which indicates how much money and value we create for our customers on both sides – the […]

This post is not about K8S – nor is it about AWS. It is not about containers – nor is it about some new, “cool” technology for managing large-scale applications. Rather, this post is about how we deploy a highly sophisticated Java service, a heavy service that is very actively developed on a daily basis, to 1000s of servers across our 7 data centers around the world. So what’s the problem? Isn’t it enough to take a list of servers, get the version to deploy and run it with an automation tool like ansible? Well, it’s not as simple as it might seem. This service serves Taboola’s recommendations and responds to hundreds of thousands requests per second. The service has to be fast – so fast that its p95 should be below 500 milliseconds per request. Which means we can’t have any downtime at all, or even afford slower […]

Optimizing Spark Executor Utilization: Harnessing Dynamic Allocation and Resource Management for Efficient Workload Processing.

Optimized MySQL slave replication for faster WAN connections. Explore key strategies and configurations for enhanced MySQL replication performance.

In Taboola, we deal with scale, huge scale. A small issue might turn into a disaster in a matter of hours. Re-writing and replacing an existing service with a new one is a real challenge, moreover doing it without causing downtime is SCARY. Reading logs is not an option. Logs are gigantic, unwieldy and span over many machines. It would take hours to combine and analyze them. In this post I will share with you three graphs in Grafana that I think are a must for observing new code. Let’s start… Did I break production? You write your shiny code, you (even) test it, but, how would you verify that you didn’t break the production environment? Luckily, we use Grafana, and this actually makes a big difference. My plan was to compare old code vs. new in Grafana, but, where to start? You have Grafana… let’s use it! Frankly, I […]

To facilitate flexibility and technological hype, you want to work with people who know how to learn. This is much better than having someone who knows a specific programing language, because a person ‘ who knows how to learn’ can learn any new language! This agility is crucial, because technology is always changing and learning is endless: My story begins two and a half years ago in Taboola Engineering, where I arrived with dozens of new employees. In fact, 50 percent of the developers were new (less than one year)! Taboola was growing, and with great growth comes a great need to learn. My goal was to create learning programs, but along the way I realized that it was far beyond this – learning brings personal development, curiosity, doubt, and insights into the organization’s working methods. The past years has been an exciting journey of many collaborations, trial and error, […]

At Taboola, we work daily on improving our Deep-Learning-based content-recommendation model. We use it to suggest personalized news articles and ads to hundreds of millions users a day, so naturally we must stick to state-of-the-art deep learning modeling methods. But our job doesn’t end there – analyzing our results is a must too, and then we sometimes return to our data science roots and apply some very basic techniques. Let’s lay such a problem out. We are investigating a deep model that behaves rather strangely: it wins over our default model for what looks like a random group of advertisers, and loses for another group. This behavior is stable in the day to day, so it looks like there might be some inherent advertisers qualities (what we’ll call – campaign features) to blame for this. You can see a typical model behavior for 4 campaigns below. So we hypothesize that […]
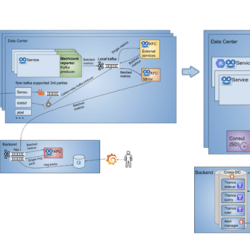
In this blogpost I will describe how we, at Taboola, changed our metrics infrastructure twice as a result of continuous scaling in metrics volume. In the past two years, we moved from supporting 20 million metrics/min with Graphite, to 80 million metrics/min using Metrictank, and finally to a framework that will enable us to grow to over 100 million metrics/min, with Prometheus and Thanos. The journey to scale begins Taboola is constantly growing. Our publishers and advertisers increase exponentially, thus our data increases, leading to a constant growth in metrics volume. We started with a basic metrics configuration of Graphite servers. We used a Graphite Reporter component to get a snapshot of metrics from MetricRegistry (a 3rd party collection of metrics belonging to dropwizard that we used) every minute, and sent them in batches to RabbitMq for the carbon-relays to consume. The carbons are part of Graphite’s backend, and are […]

Sometimes we need to test urgent features fast. It has to be within a very short timeframe, when there is not enough time to run a full test plan for that feature. This might occur on different occasions. When not having enough manpower in QA to cover a full test plan for a feature. New special demands from an important client right before the release deadline. Product management needs new adjustments before the developer deploying a new product version. It can also happen when a client, team lead or PM wants a new feature and it should have been done YESTERDAY! It can also happen actively. Running every once in a while a wide post-production test, or dedicating limited time for a bug hunt. We at the Taboola Video Solution department call it “Search for a Bug Thursday”. This unplanned development might end up launching a “half baked” product. It […]

Our core business at Taboola is to provide the surfers-of-the-web with personalized content recommendations wherever they might surf. We do so using state of the art Deep Learning methods, which learn what to display to each user from our growing pool of articles and advertisements. But as we challenge ourselves manifesting better models and better predictions, we also find ourselves constantly facing another issue – how do we not listen to our models. Or in other words: how do we explore better? As I’ve just mentioned, our pool of articles is growing, meaning more and more items are added each minute – and from an AI perspective, this is a major issue we must tackle, because by the time we finish training a new model and push it to production, it will already have to deal with items that never existed in its training data. In a previous post, I’ve […]