The story starts with metrics. Every mature software company needs to have a metric system to monitor resource utilisation. At some point, we noticed under-utilization of spark executors and thier CPUs. Usually, dynamic allocation is used instead of static resource allocation in order to improve CPU utilisation through sharing. In this blog post, we’ll define the problem, share the goals we worked towards and highlight many technical peculiarities regarding dynamic allocation usage along the way.
At Taboola, we use Grafana, Prometheus with a Kafka-based pipeline to collect metrics from several data-centers around the world. Metrics at scale is a very interesting topic and involves multiple problems in itself and we have previously covered these in our blog and meetup presentations.
Our data platform comprises several services that compute data projections and, importantly, those are long-running processes with long-living spark context. Periodically, when triggered, these services process new chunks of data, however, they block until the following occasion leaving the resources unused while no other framework can use them due to static resource allocation of cores.
Here is a Grafana dashboard that shows the problem:
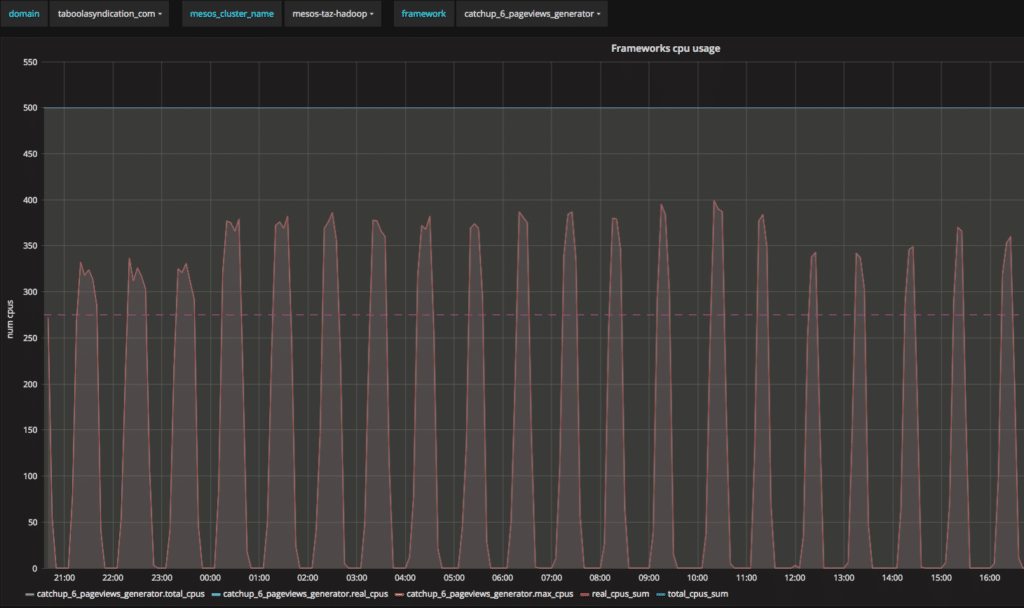
The total number of cores taken from the Mesos cluster is invariably 500 while actual usage peaks at 400 occasionally leaving the cores idle a lot of the time.
We can define our goals as:
- Make better use of available resources
- Improve end-to-end processing time
One way to release unused resources in the static cluster (we are running on-premise, with a static number of Mesos-worker nodes) is to start using a dynamic allocation feature.
What is dynamic allocation?
- Spark provides a mechanism to dynamically adjust the resources your application occupies based on the workload
- Your application may give resources back to the cluster if they are no longer used and request them again later when there is demand
- It is particularly useful if multiple applications share your Spark cluster resources
So what is happening under the hood?
Spark driver monitors the number of pending tasks. When there is no such task or there are enough executors, a timeout timer is installed. If it expires, the driver turns off executors of the application on Mesos-worker nodes. Other executors might still want to access some of the data on the executor that completed all its tasks so we need an external shuffle service to provide them with a way to continue accessing shuffle data.
How to start
- Enable External shuffle service: spark.shuffle.service.enabled = true and, optionally, configure spark.shuffle.service.port
- Enable dynamic allocation feature flag: spark.dynamicAllocation.enabled = true
- Provision external shuffle service on every node in your cluster that will listen to spark.shuffle.service.port
How to make sure external shuffle service is running on every mesos-worker node
The natural approach is to use Marathon. You can think about it as “init.d” for Mesos cluster frameworks. By default Marathon can decide to distribute the service instances across the cluster so that some machines will host more than one shuffle service instance or none at all. This is undesirable as we would like to have strictly one instance per host machine.
To ensure at most one service is instantiated we will use service constraints that allow us to specify max instances per machine explicitly. For example, we can add an entry to our config:
"constraints": [["hostname", "UNIQUE"]]
Equally, to ensure at least one service can be placed on a machine we will simply reserve resources designated to this service.
Static resource reservation for the “shuffle” role
- The needs of the external shuffle service will be fulfilled by the “shuffle” role in Marathon terminology.
- We configure the mesos-agents on each node to report resources to the cluster taking the shuffle needs into account. The following launch params are used for the agent:
--resources=cpus:10;mem:16000;ports:[31000-32000];cpus(shuffle):2;mem(shuffle):2048;ports(shuffle):[7337-7339]
Let’s break down these parameters one by one:
- The default port range for the mesos agents is 31000-32000.
- We are allocating 2Gb of RAM for the external shuffle service.
- We are allocating 3 ports (7337 to 7339) for external shuffle services (for green-blue deployments, different spark versions etc)
- The resources might be over-provisioned (the 2 cpus dedicated to the shuffle role are not included in the total count of 10 even though there are actually only 10 cpus in total on the machine).
To set-up Marathon masters to use resources correctly, we need to add the same role (shuffle) to the –mesos_role parameter when launching.
Now we made sure that the external shuffle service will get its own resources to run exactly once on each node regardless of the resource utilisation.
During testing in the staging environment we discovered that after 20 minutes, the tasks started to fail due to missing shuffle files. It seemed that spark management of shuffle files has its corner cases.
External Shuffle Service and Shuffle files management
As mentioned before, external shuffle service registers all shuffle files produced by executors on the same node and is responsible to serve as a proxy to the already dead executors. It is responsible for cleaning those files at some point. However, a spark job can fail or try to recompute files that were cleaned prematurely.
- There are some traces of the problem out there, e.g. SPARK-12583 – solves the problem of removing shuffles files too early by sending heartbeats to every external shuffle service from application.
- Driver must register to all external shuffle services running on mesos-worker nodes it have executors at
- Despite the complete refactoring of this mechanism, it still doesn’t always work. We opened SPARK-23286
- At the end (even if fixed) it’s not good for our use-case of long running spark services, since our application “never” ends, so it’s not clear when to remove shuffle files
- We have disabled cleanup by external shuffle service by -Dspark.shuffle.cleaner.interval=31557600
- We installed a simple cron job on every spark worker that cleans shuffle files that weren’t touched more than X hours. This requires pretty big disks in order to work to have a buffer.
So, we adjusted our external shuffle service parameters. Here are details on how to install this service on marathon.
Defining External shuffle service to run as marathon service
- Marathon supports REST API, so you can deploy service by posting service descriptor as follows
curl -v localhost:8080/v2/apps -XPOST -H "Content-Type: application/json" -d'{...}’
- We commit json descriptors to source control repository to maintain history
- The Marathon leader in quorum runs periodic task to update if necessary the service descriptor through REST-API
- Following is Marathon service json descriptor for shuffle service that runs on port 7337:
- instances are dynamically configured
- Using Mesos REST-API to find out active workers
- Using Marathon REST-API to find out number of running tasks (instances) of the given service
{
"id": "/shuffle-service-7337",
"cmd": "spark-2.2.0-bin-hadoop2.7/sbin/start-mesos-shuffle-service.sh",
"cpus": 0.5,
"mem": 1024,
"instances": 20,
"constraints": [["hostname", "UNIQUE"]],
"acceptedResourceRoles": ["shuffle"],
"uris": ["http://my-repo-endpoint/spark-2.2.0-bin-hadoop2.7.tgz"],
"env": {
"SPARK_NO_DAEMONIZE":"true",
"SPARK_SHUFFLE_OPTS" : "-Dspark.shuffle.cleaner.interval=31557600 -Dspark.shuffle.service.port=7337 -Dspark.shuffle.service.enabled=true -Dspark.shuffle.io.connectionTimeout=300s",
"SPARK_DAEMON_MEMORY": "1g",
"SPARK_IDENT_STRING": "7337",
"SPARK_PID_DIR": "/var/run",
"SPARK_LOG_DIR": "/var/log/taboola",
"PATH": "/usr/bin:/bin"
},
"portDefinitions": [{"protocol": "tcp", "port": 7337}],
"requirePorts": true
}
As mentioned before, we need to configure spark application appropriately:
Spark application settings:
- spark.shuffle.service.enabled = true
- spark.dynamicAllocation.enabled = true
- spark.dynamicAllocation.executorIdleTimeout = 120s
- spark.dynamicAllocation.cachedExecutorIdleTimeout = 120s
- infinite by default and may prevent scaling down
- it seems that broadcasted data falls into “cached” category so if you have broadcasts it might also prevent you from releasing resources
- spark.shuffle.service.port = 7337
- spark.dynamicAllocation.minExecutors = 1 – the default is 0
- spark.scheduler.listenerbus.eventqueue.size = 500000 – for details see SPARK-21460
By now, we are running services with dynamic allocation enabled in production. For the first half of the day everything was great. After a while, however, we started to notice degradation in those services. Despite the fact that Mesos master was reporting available resources, the frameworks started to get less and less cpus from Mesos master.
We enabled spark debug logs, investigated and found that frameworks that were using dynamic allocation, rejected resource “offers” from Mesos master. There were two reasons for this:
- We were running spark executors that were binding to jmx port so while using dynamic allocation, the same framework in some cases got an additional offer from the same mesos-worker and tried to start the executor on it and failed (due to port collision)
- Driver started to blacklist mesos-workers after only 2 such failures without any timeout of blacklisting. Since in dynamic allocation mode the executors are constantly started and turned off, those failures were more frequent and after 6 hours of the service running, approximately 1/3 of mesos-workers became blacklisted for the service.
Blacklisting mesos-workers nodes
- Spark has a blacklisting mechanism that is turned off by default.
- Spark-Mesos integration has a custom blacklisting mechanism which is always on with max number of failures == 2.
- We have implemented a custom patch, so that this blacklisting will expire after a configured timeout and so Mesos-worker node will return to the pool of valid nodes.
- We’ve removed jmx configuration and all other port bindings from executors’ configuration to reduce the number of failures.
We still have to discover external shuffle service tuning
Some params are only available with spark 2.3 or above : SPARK-20640
- spark.shuffle.io.serverThreads
- spark.shuffle.io.backLog
- spark.shuffle.service.index.cache.entries
What we achieved
- We are using dynamic allocation in production where it makes sense (e.g. services with some idle times)
- We have better resources utilisation: instead of four services we are able to run five services on the same cluster
- We were able to provide more cores to every service (800 vs 500) which reduced end-to-end running times.
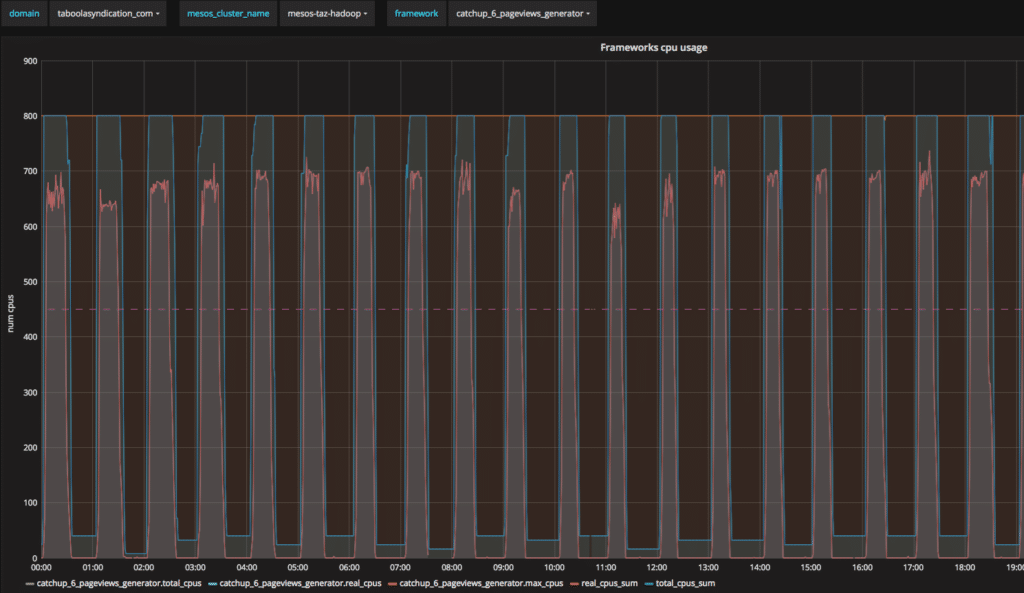
Notice how total_cpus_sum (the allocation from the cluster) follows real_cpus_sum (the actual usage of all workers for the framework)
Overall we can say that:
- Dynamic allocation is useful for better resource utilisation.
- There are still some corner cases, especially on Mesos clusters.