Our core business at Taboola is to provide the surfers-of-the-web with personalized content recommendations wherever they might surf. We do so using state of the art Deep Learning methods, which learn what to display to each user from our growing pool of articles and advertisements. But as we challenge ourselves manifesting better models and better predictions, we also find ourselves constantly facing another issue – how do we not listen to our models. Or in other words: how do we explore better?
As I’ve just mentioned, our pool of articles is growing, meaning more and more items are added each minute – and from an AI perspective, this is a major issue we must tackle, because by the time we finish training a new model and push it to production, it will already have to deal with items that never existed in its training data. In a previous post, I’ve discussed how we use weighted sampling to allow more exploration of items with low CTR (Click-Through Rate) while attempting not to harm the traffic of high CTR items. In this post, I’ll extend this dilemma even further, and discuss how we can allow meaningful exploration of items which our models have never seen before.

Understanding Embeddings and OOV
Understanding the use of embeddings – and what they represent – is the key to understanding the discussed exploration method, so let’s briefly review how they work. An embedding is a set of weights (or more simply, a vector) learned by the model to represent the characteristics of an input feature. Let’s say that we have two items in our pool, where item A is super-successful among gamers of age 20 to 30 living in the US and Canada, and item B is very popular among cooking-lovers of ages 30 to 40 living in German-speaking countries in Europe. Where should the model store this learned information? In each item’s embeddings, of course! So embeddings are value-specific vectors the model has learned, and it allows it to distinguish one from another, and estimate their performance more accurately. For each of our items, the model learns a new vector. If our model is training correctly, another item which is successful with item A’s crowd will have an embedding vector which will be close to him in our vector space.
But let’s say that our training data has another item, item C, which is so new it appeared on the training data only once. Is this single appearance sufficient for the model to learn anything about this item? Of course not. So there’s no point in creating an embedding for it – as it will obviously just be noise. Yet, we still need an embedding for it, so what should we do?
Whenever we build embeddings to a feature, we decide on a threshold of minimum appearances each value must have in order to have its own embedding. All the values which have less appearances than the required threshold are then aggregated and are used to construct a single embedding which will be used for all of them. This embedding is named the Out Of Vocabulary embedding (OOV), as it is used for all the values that didn’t make it into the list (or vocabulary) of values which have their own embedding. Even more, the OOV embedding is also used for all the completely new items which the model never seen before.
It’s easy to see why having an OOV embedding is really bad for any value. It is constructed of many many completely different values, which rarely have anything to do with one another. This means that OOVs are usually noisy and have very low CTR estimates – even though there’s nothing wrong with these items, they simply weren’t displayed enough when the model was trained.
But there’s a vicious cycle here – if a new item received an OOV embedding due to lack of appearances, it will receive very low CTR estimates by the model – which again won’t allow it to receive many appearances. This can make the model stick to the same items it always displays, and this isn’t good for us. So… it’s time for us to head over to Sherwood forest!

The Robin Hood Exploration
One of our most important goals at Taboola is to predict whether our users will click on an item we’ve shown them or not. Therefore, our training data is constructed of all the items we’ve shown (also known as impressions), and the user’s response (clicked or not). As there’s an obvious positive correlation between the number of times we show a certain item to the number of clicks it receives, it’s easy to see that our best-selling items are also the ones with the most appearances in our training data. This means these are also the items with the most powerful and well-trained embeddings.
So the trick we did here is quite simple – just like there’s a minimal threshold of appearances to the embeddings, which below it a value becomes an OOV, we’ve added a maximal threshold to the appearances, which above it a value also becomes an OOV. We tuned it so only the very top of items will fall above this threshold and will be added to the OOV bucket. This provides us with an OOV made by a combination of the most profitable items we have – so now all new items receive a super-powerful embedding, which makes the model give them higher CTR estimates. We named this method Robin Hood Exploration, as we “steal” data from our best items and move it to our OOVs.
And, yes – it works:
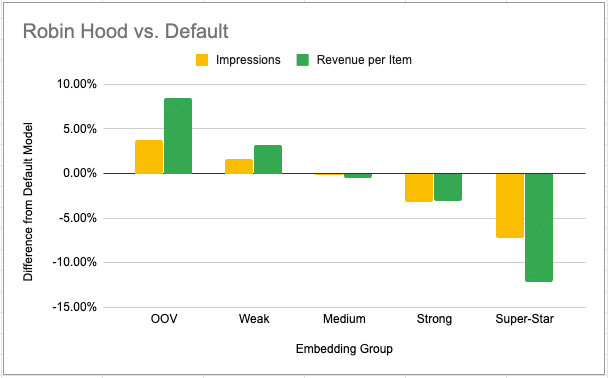
The Robin Hood method is performing as expected – our OOVs and Weak embedding groups receive more traffic and also yield more revenue, but on the expense of our top-sellers. Medium-strength embeddings are left with almost no change. Reducing traffic of top sellers is something we can deal with when affecting a limited amount of traffic – our purpose here is to perform exploration, a.k.a: give traffic to new items, and there’s no need to perform exploration over our best sellers – we already know they’re our best-sellers. And there is even more good news: when it comes to our overall revenue – this method showed absolutely no negative impact over it.

To conclude, our Robin-Hood approach, which transfers data from top items to OOVs, has proved itself to be a valuable method for performing meaningful exploration with minimal technical effort. We hope it will prove itself worthy for our readers too. Safe ride!