
My first date with my company – or – how onboarding looks from a freshman’s eye According to LinkedIn, one in three employees decide to quit their job within the first 6 months(!) I’ve been managing people for over 20 years and I’ve spent a long time trying to crack the code of successful onboarding. It was only recently, when I started working for a new company, that my eyes were opened – I actually felt what it’s like to be a new employee. The lessons I’ve learned surprised me so much. So, I took it upon myself to build an onboarding plan addressing exactly what a new employee needs. We started to run this program in Taboola and I’m happy to say it gets great feedback. In this blog post, I’ll shed some light on the psychology of a new employee, give practical ways to deal with it […]

Every candidate we recruit goes through a long process of evaluation. Near the end of the process, after we decided they fit our culture and have the skills we need, we have a reference check. Sometimes we take it as a formal phase in the process just to make sure they’re not a serial killer. Actually a reference check is one of the more important stages in the process, let me explain why. Think for a second of a recruiter that is going to recruit someone who worked with you. You know more about this person than any process. If they could peek inside your head – they will get all the knowledge they need – much more knowledge than they got from their process. Now, while you’re still in the place of the referee, think about how will you actually answer to a reference check. Most of the time, […]

A joint post with Ofri Mann We went to ICLR to present our work on debugging ML models using uncertainty and attention. Between cocktail parties and jazz shows in the wonderful New Orleans (can we do all conferences in NOLA please?) we also saw a lot of interesting talks and posters. Below are our main takeaways from the conference. Main themes A good summary of the themes was in Ian Goodfellow’s talk, in which he said that until around 2013 the ML community was focused on making ML work. Now that it’s working on many different applications given enough data, the focus has shifted towards adding more capabilities to our models: we want them to comply to some fairness, accountability and transparency constraints, to be robust, use labels efficiently, adapt to different domains and so on. A slide on ML topics, from Ian Goodfellow’s talk We noticed a […]
Explore the challenges from testing with Mockito. Misled by IntelliJ’s suggestions, NPE was caused by a missing ‘public’ keyword in a method declaration.

Intro At Taboola we use Spark extensively throughout the pipeline. Regularly faced with Spark-related scalability challenges, we look for optimisations in order to squeeze the most out of the library. Often, the problems we encounter are related to shuffles. In this post we will present a technique we discovered which gave us up to 8x boost in performance for jobs with huge data shuffles. Shuffles Shuffling is a process of redistributing data across partitions (aka repartitioning) that may or may not cause moving data across JVM processes or even over the wire (between executors on separate machines).Shuffles, despite their drawbacks, are sometimes inevitable. In our case, here are some of the problems we faced: Performance hit – Jobs run longer because shuffles use network and IO resources intensively. Cluster stability – Heavy shuffles fill scratch disks of cluster machines. This affects other jobs on the same cluster , since […]
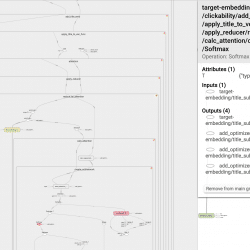
How to structure your TensorFlow graph like a software engineer So you’ve finished training your model, and it’s time to get some insights as to what it has learned. You decide which tensor should be interesting, and go look for it in your code – to find out what its name is. Then it hits you – you forgot to give it a name. You also forgot to wrap the logical code block with a named scope. It means you’ll have a hard time getting a reference to the tensor. It holds for python scripts as well as TensorBoard: Can you see that small red circle lost in the sea of tensors? Finding it is hard… That’s a bummer! It would have been much better if it looked more like this: That’s more like it! Each set of tensors which form a logical unit is wrapped inside […]

“Any fool can write code that a computer can understand. Good programmers write code that humans can understand.” Martin Fowler, 2008. Names, they are everywhere in our software. Just think of the things we name, we name our packages, classes, methods, variables, in fact us programmers do so much of it, we should probably know how to do it well. In my opinion, making the code readable is just as important as making your code work. In this post I will give you 5 tips and guidelines to choose your names in order to make your code more readable. 1. Reveal your intent: The name you choose should answer as many questions as possible for the reader, questions like, why it exists, what it does, and how it is used. Choosing good names takes time but saves more than it takes when the going gets tough, so […]

Some of the problems we tackle using machine learning involve categorical features that represent real world objects, such as words, items and categories. So what happens when at inference time we get new object values that have never been seen before? How can we prepare ourselves in advance so we can still make sense out of the input? Unseen values, also called OOV (Out of Vocabulary) values, must be handled properly. Different algorithms have different methods to deal with OOV values. Different assumptions on the categorical features should be treated differently as well. In this post, I’ll focus on the case of deep learning applied to dynamic data, where new values appear all the time. I’ll use Taboola’s recommender system as an example. Some of the inputs the model gets at inference time contain unseen values – this is common in recommender systems. Examples include: Item id: each recommendable item gets […]

If you are using web cookies to operate your online business you probably know already that just like in real life, cookies do not last long. This is an especially known fact to whoever uses online cookies to store unique user IDs. Most online marketing companies rely on cookies for that purpose, but when cookies disappear – it makes it harder for them get persistent user data. Interested to know for how long does a cookie really last? in this post I’ll try to provide some answers. Who is eating web cookies? Cookies can disappear for various reasons, such as: Clearing the browser historical data by the user Setting the browser to reject third-party cookies Using tools that clean up your device and free up storage space Use of VPNs, Ad Blockers and more. One very common reason cookies disappear is the use of private browsing modes such as Incognito […]
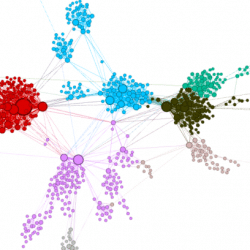
In the last couple of years deep learning (DL) has become a main enabler for applications in many domains such as vision, NLP, audio, click stream data etc. Recently researchers started to successfully apply deep learning methods to graph datasets in domains like social networks, recommender systems and biology, where data is inherently structured in a graphical way. So how do Graph Neural Networks work? Why do we need them? The Premise of Deep Learning In machine learning tasks involving graphical data, we usually want to describe each node in the graph in a way that allows us to feed it into some machine learning algorithm. Without DL, one would have to manually extract features, such as the number of neighbors a node has. But this is a laborious job. This is where DL shines. It automatically exploits the structure of the graph in order to extract features for […]