MySQL Slave Replication Optimization
Written by Yossi Kalif & Ariel Pisetzky

MySQL in Taboola
So you love MySQL – what do you know, so do we here at Taboola. We spend a lot of our time with MySQL building our infrastructure to provide over 30 billion recommendations a day on over 3 billion web pages. In this blog post we would like to share how we optimized our MySQL to replicate faster over WAN connections so that we would not need to wake up at night and fix things. Oh, and it also helped us speed things up, so when we do have issues, they resolve faster. So, if your infrastructure has MySQL and you have replication, this blog post is for you.
TL;DR – at the bottom of the post
Taboola operates in multiple data centers around the world, and at the time of the post, we have 9 data centers. We have our MySQLs in each of them and the Taboola network depends on the data in these MySQLs reaching all the data centers in a timely manner. Each data center (of the 9) has at least 10 MySQLs that are acting as slaves to our “Master” database (for the sake of simplicity, let’s call it “Master-MySQL”). The daily replication volume to each of the globally distributed nodes is about 200Gb, while the local storage of one of our MySQLs is about 7TB. The use case for the MySQLs has evolved over the years. For the last 6 years the front end MySQLs are used to store configurations for the applications, publisher settings and campaign data, all of which change frequently.
Problem statement deepdive
So, what was the problem we tried to find a solution for within the world of replication? The Taboola services are sessionless, so each time a user connects to our service, the connection can (and will) go to a different app server. The app servers in turn will connect to different MySQLs slave for information on the transactions and this information needs to be replicated quickly to the data centers. When the Master-MySQL sends out updates, not all data centers have the same quality of WAN connections and the physical distance plays a role in the latency. When we set up the replication years ago, the changes were lighter and the size of the infrastructure was much smaller. The larger they both got, the larger the problem of replication interferences became. Worst of all, when something causes the replication to break (and you know this will happen at night) we need to fix it and wait for the replication to catch up. So we set out to (a) improve the replication resilience. (b) reduce the time it takes to replicate something and (c) improve the reliability of the replication, so we don’t need to wake up at night and fix it. One important thing to note – this was all based on MySQL 5.5.
First stab at it – 2015
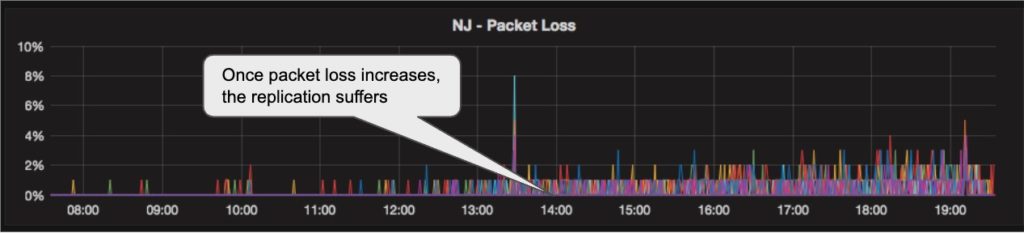
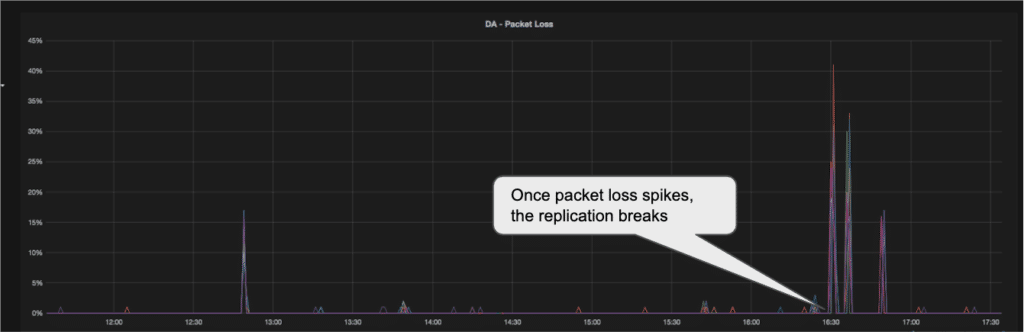
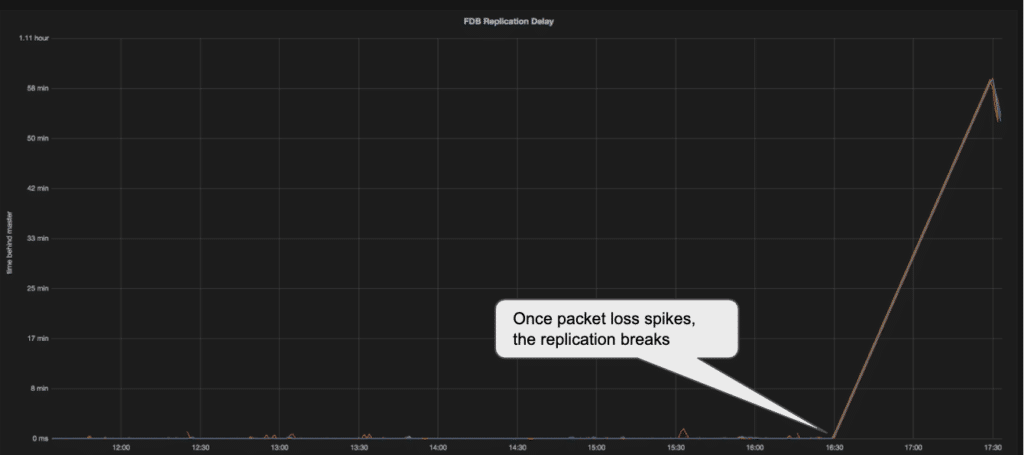
Our first attempt at fixing the replication problem revolved around the slave replications settings, of retry and timeouts. Most of our issues were caused by packet loss or disconnections on the WAN lines (think VPNs, ISPs, routing and other networking issues Data Engineers don’t want to care about). With any issue on the long connections our replication suffered. We would see the replication slow down and in severe cases break. Once it broke, a manual restart of the replication slave was needed. Even a small degradation in the network service, such as a 2% packet loss caused the replication on multiple MySQLs to slow down and eventually break. (see graphs below). The first thing we changed was the default retry value, this would seem like a small thing, almost trivial, but network conditions do tend to change and that actually helped with the broken replication == manual restart condition. Now, the MySQL replication slave would retry more times and when the network recovered, so would the replication. There are actually two settings here “slave_net_timeout” and “MASTER_CONNECT_RETRY”. We wanted to reduce the amount of time the servers wait to declare the connection broken, then significantly increase the retries to establish a new connection
Network quality degradation causing increased replication delays:

Almost full disconnection of network (high packet loss) causing a break in the replication:
Second improvement – the network level
Basking in our initial success, we let things be for some time and enjoyed the improved stability. During that well-earned quiet time, the size of our replication continued growing and our need to move data faster came to light. This made us look at the networking side of things and check how we could improve the network performance.
There are multiple ways to accelerate the networking output an application sees, most of them are hard to implement (move to UDP, compression, dedup and so on). When we came across BBR, it was clear it would be the simplest network tweak to implement and deploy in our network and servers. For further reading about Google BBR.
We have implemented BBR on our binlog-servers, since the slaves of these machines are located on remote DC’s ( and affected by the WAN lines) , afterwards the MySQL replication was less sensitive to the events of packet loss. We have upgraded our linux kernel to 4.19.12 , and set the following kernel tunables:
- net.core.default_qdisc = fq
- net.ipv4.tcp_congestion_control = bbr
Taking it to the next level
The next phase in our quest to improve MySQL slave replication was aimed at improving the replication time. This new goal came out of necessity. The size of our data has been growing constantly so the following needed to be addressed:
- Every break in the replication took longer to recover from.
- Creating a new replication slave became a long process. Each frontend mysql has 5TB of data that needs to be restored from backup.
- Maintenance of the replication slaves (patches, minor and major upgrades, hardware issues) became more expensive as the time to run them was compounded by the replication catchup time.
- DML changes at the MySQL master cause mass changes at the slave and send a large chunk of data downstream from the master.
Now at this point in our quest we were already using MySQL 5.7 and the replication slave clients were accessing the servers via ProxySQL. We use ProxySQL to manage read connections in such a way that the replication delay was a factor in the server selection process (the ProxySQL would send the query to the available servers taking into account replication delay). It was time to push 5.7 into the world of parallel replication.
In order to run the test we had to build an identical environment for the test. We chose two nodes which have the same hardware & software, both worked with the same master MySQL. To complete the test environment and to remove external noise, we removed all the client connections from the two servers, so that the load on the servers would be identical. Once all traffic was removed from the servers, the replication was stopped for one hour, this way both servers have one hour of delay. When we turned the replication back on, we compared the two servers to see how this setting impacted the replication. The changes and test results are on the following table.
Spec for test environment
| Spec | Server 1 | Server 2 |
| cpu | Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz | Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz |
| cores | 40 | 40 |
| memory | 128GB | 128GB |
| Disk | Samsung NVMe | Samsung NVMe |
| Master | Master-4[binlog server] | Master-4[binlog server] |
| sync-binlog | 2 | 2 |
| innodb_flush_log_at_trx_commit | 2 | 2 |
| slave_parallel_type | database | database |
| slave_parallel_workers | 0 | 0 |
Test scenarios
| # | Test | Results |
| 1 | Checked that our test servers are the same. Stopped the replication for one hour , and then let the replication lag finish. (running with slave_parallel_workers=0) |
Both servers finished the lag at the same time |
| 2 | slave_parallel_workers=4 slave_parallel_type=DATABASE(most of our data is in one database, so we didn’t expect any improvements here) |
Both servers finished the lag at the same time |
| 3 | In MySQL 5.7 a new replication parameter was announced
|
We observed little improvement in the parallel replication (but it was only about 10%)
Not what we had hoped for |
| 4 | In MySQL 5.7.22 a new parameters was announced
Binlog-transaction-dependency-tracking transaction_write_set_extraction
Those parameters were applied on binlog-server/slave
Parameters of Master-4[binlog server]
binlog_format=’ROW’ transaction_write_set_extraction=’XXHASH64′ binlog_transaction_dependency_tracking = WRITESET On the slave we used Slave_parallel_workers=8 slave_parallel_type=LOGICAL_CLOCK binlog_format=’ROW’ transaction_write_set_extraction=’XXHASH64′ binlog_transaction_dependency_tracking = WRITESET |
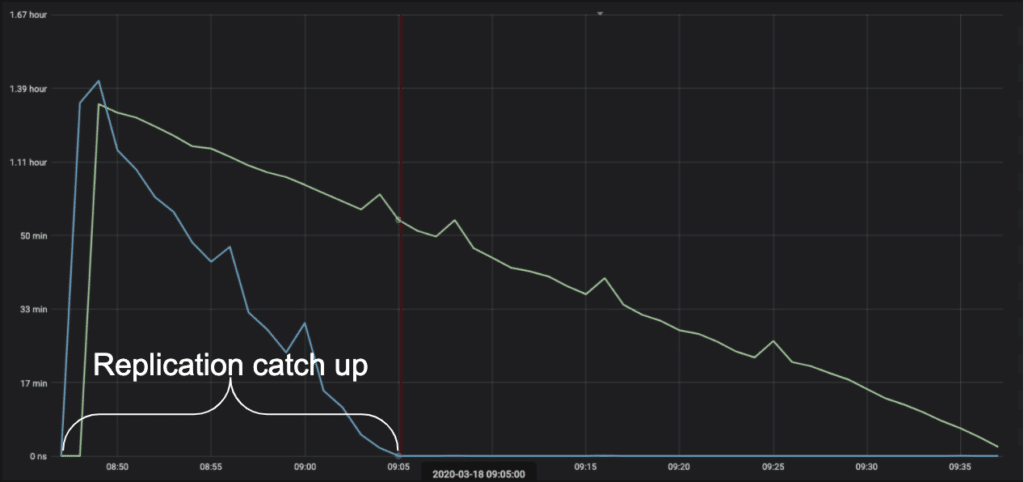
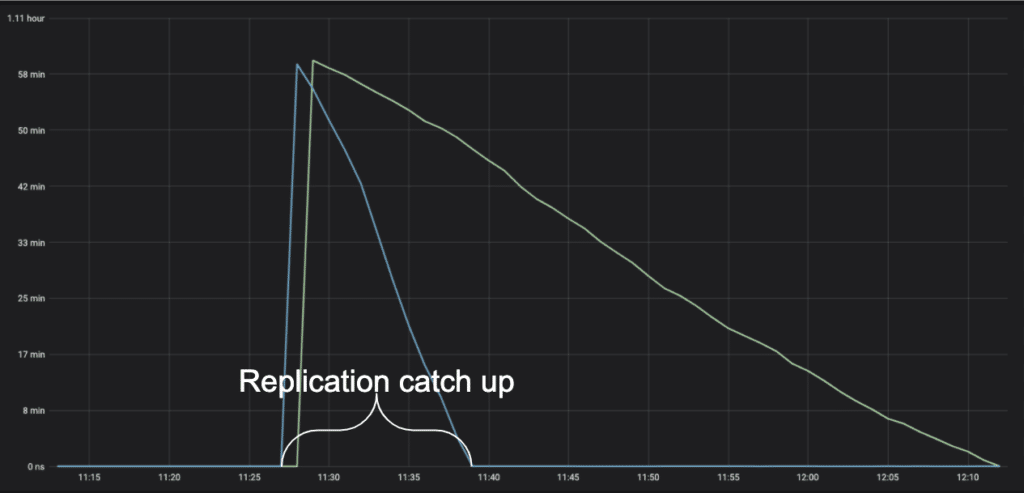
Replication delay catchup on Server2 finished in 17min compared to 50min on server1. |
| 5 | Since we saw an improvement when working with
Slave_parallel_workers=8, we tested it with 16 parallel workers. |
Replication delay catchup on Server2 finished in 11 min, compared to 43min on Server1. |
Results
Test 4 graph (you can see the improved time it takes to close the replication gap)
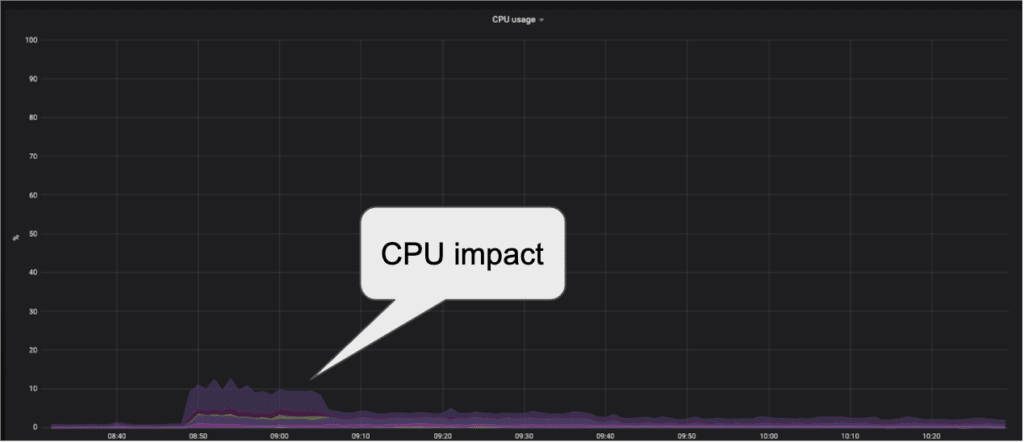
The replication improvement might have cost on the CPU, so we also checked the CPU metrics to make sure that the impact on the server will not be too high and we could not run this configuration under production load. The CPU graph showed that the CPU increase for the replication work is about 7%.
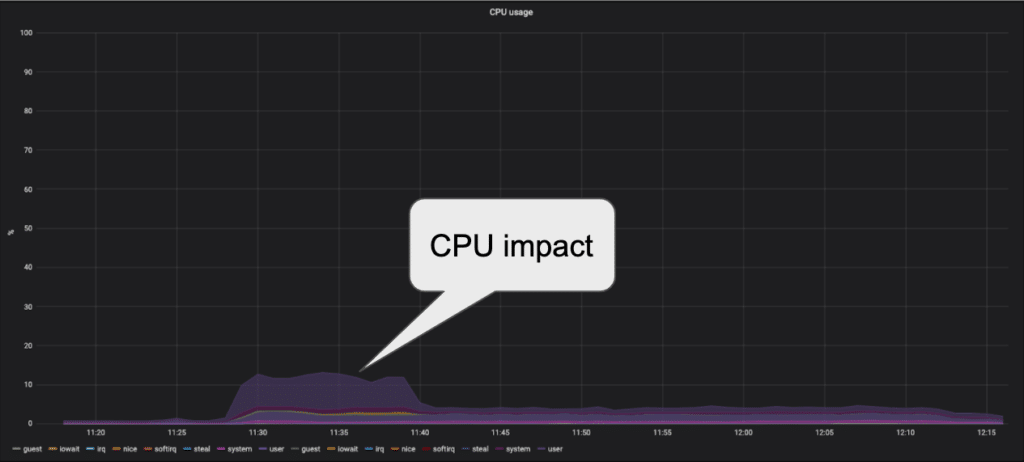
Test 5 replication catchup time showed the best result and CPU impact was within acceptable levels to go into production.
The CPU consumption
Bottom line
Now with the improved configuration we can manage our 100 slaves with far more ease, as the cost of production operations is lower. The ability to perform patches, run hardware maintenance and overcome WAN issues is an important part of our MySQL routine.
TL;DR
Here is a short version of all the steps we took in order to sleep better (not in the order of implementation)
- Implement google BBR on binlog servers (blackhole engines)
- Kernel version 4.19.12
- net.core.default_qdisc = fq
- net.ipv4.tcp_congestion_control = bbr
- For parallel slave replication
- Upgrade master and slaves to 5.7.22 or higher
- Change the following parameters on the master/slave
- slave_parallel_type=LOGICAL_CLOCK
- binlog_format=’ROW’
- transaction_write_set_extraction=’XXHASH64′
- Slave_parallel_workers=8/16
- binlog_transaction_dependency_tracking = WRITESET
- Configure network recover parameters:
- slave_net_timeout=60
- MASTER_CONNECT_RETRY=60