
We announced our plans to acquire Connexity, bringing eCommerce recommendations to the open web. And this is just the beginning.

The world is not flat, it’s highly nested With over 4 billion page views per day and over 100TB of data collected daily, scale at Taboola is no joke. Our primary data pipe deals with masses of data and endless read paths. Could we optimize our schema for all these read paths? Guess not… Our schema is HUGE and highly nested. After digesting the data, we keep it in hourly Parquet files on HDFS, where each hour consists of about 1-1.5TB of compressed data. Our schema roughly looks like this: root |– userSession: struct | |– maskedIp: long | |– geo: struct | | |– country: string | | |– region: string | | |– city: string | |– pageViews: array | | |– element: struct | | | |– url: string | | | |– referrer: string | | | |– widgets: array | | | | |– element: […]

You wrote your code. You even tested it. And now, you are eager to git push it. But how can you verify that it really works? In Taboola, we test our code in production! In this article, you will see how every software engineer, even on the first day in the company, can test in production – all thanks to a dedicated Jenkins pipeline job and lots of metrics. How hard is it to test in production? Quite hard. You probably already knew that. Everybody fears that moment when they need to test changes in production. The main reason is that not everyone has the required IT skills. Moreover, people have to repeat error-prone, manual tasks – which might result in downtime and revenue loss. For our release engineers, it was also an unmanageable headache – a “thundering herd” of developers eager to test their features in production. […]

Have you ever tried building an infrastructure to upload 150TB a day? Have you ever tried querying over 13PB without going bankrupt? These are some of Taboola’s PV2Google (pageviews to Google) service scale challenges that we deal with in our day to day. In this blog series, we’ll share how we do it, and the challenges we face. In this article (part 1) we’ll focus on the architecture. Part 2 covers the lessons we’ve learned over the years. Hello, Pageviews! Taboola’s goal is to power recommendations for publishers and advertisers. Our platform serves over 360 billion content recommendations and processes over two billion pageviews a day. Pageview is a record describing recommendations, user activity (such as a click), and much more on a user’s visit to a webpage. Currently, the pageview record has about 1,000 fields. Two billion pageviews generate a huge amount of data. This data is processed […]
In part 1 of the series we shared the architecture of Taboola’s PV2Google service which uploads over 150TB/day to BigQuery. In this article (part 2), we’ll share the challenges and lessons we’ve learned over the course of a few years. Lesson 1: queries might be (extremely) expensive We continuously upload pageviews to BigQuery and keep them for six months. This translates to over 13PB of pageviews in BigQuery. Querying the entire dataset would be extremely expensive, about $65K/query (assuming $5/TB). We apply a few methods and guidelines to substantially reduce this cost: Never use `SELECT *`: BigQuery’s query cost is based on the size of the data scanned. Most queries actually need only a few fields. Hence, selecting only the relevant fields will dramatically reduce the cost of the query. Cluster tables: clustering is a neat BigQuery feature that reduces the scanned row count. With clustering, BigQuery optimizes the data […]

By Ariel Pisetzky and Tarek Shama Taken for Granted Taken for granted. That’s the way most users and even techies think of DNS. Or more precisely, they just don’t think of it at all. DNS is one of those things that for most users is a solved problem. You have a server with very reliable and stable software that can run for a very long time with little maintenance. The resolvers even have a nice built in failover mechanism for a secondary server. So, what more is there to say about this subject? Performance. Performance with DNS services has been seen as a geographical issue for years now. Yes, there have been paid DNS services that are faster at the DNS search level itself, especially if you are talking about complex records that have logic attached to them. Yet, the popular discussion is mostly around the global DNS providers. In […]
If you fall, fall right – a tale of SRE critical incident management By Yehuda Levi, Tal Valani, Ariel Pisetzky & Eli Azulai Imagine this scenario – your data center is down. 1500 servers are down. Each server needs to be handled and monitored and the responsibility for each should be divided between all teammates. Each team is looking after the status of their services. Client facing services are impacted. New information keeps flowing in from different channels and the status of the outage and servers keep changing. How to get the list of the server affected? How to put it all in one place? How to assign responsibility for each? What is the status of each server? How can the internal clients receive ongoing status updates? What happens if a server was intentionally down before the incident? What happens if a more complex issue occurs and the time to […]
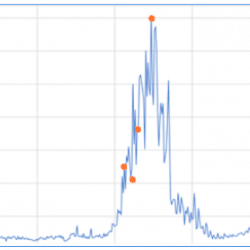
Optimize Data Center Health: Taboola employs LSTM Autoencoder for precise anomaly detection, enhancing system performance.

Failure. I need to talk about failure, and not any failure, my failure. I need to share it with everyone in the production group, everyone in R&D. My team, my peers, my managers. The meeting will start in just a few minutes and I am under fire to explain what went wrong, how I failed the organization and how we need to be better. General George S. Patton Jr. said “The test of success is not what you do when you are on top. Success is how high you bounce when you hit the bottom.” There is a lot to learn from that saying, and not only for people. Successful systems need to bounce back from a failure and do it well. IT systems need to be able to endure a catastrophic event and just dust it off. This is what we expect of our production systems in Taboola, […]

So, the firefighters are in your data center, there is no electricity, and the pager is more like a DDoS attack on your phone than anything informative. You look at your watch, multiple thoughts running through your head. Why me? Why now? What was the last DR test result? How do you pull the team out and through this IT catastrophe and survive to write about it? This is my story, my personal fight with the IT “Murphy laws” and how we can all benefit from it. It was a Friday, one you know you need to be extra careful with. It’s always the end of the work week or smack in the middle of the night. (No IT catastrophe ever happens when it’s convenient to you, now does it? They always cluster and bunch around the most difficult times.) Anyway, it’s the end of the day Friday and multiple […]