By Ariel Pisetzky and Tarek Shama
Taken for Granted
Taken for granted. That’s the way most users and even techies think of DNS. Or more precisely, they just don’t think of it at all. DNS is one of those things that for most users is a solved problem. You have a server with very reliable and stable software that can run for a very long time with little maintenance. The resolvers even have a nice built in failover mechanism for a secondary server. So, what more is there to say about this subject? Performance.
Performance with DNS services has been seen as a geographical issue for years now. Yes, there have been paid DNS services that are faster at the DNS search level itself, especially if you are talking about complex records that have logic attached to them. Yet, the popular discussion is mostly around the global DNS providers. In this blog post, we would like to examine the performance gains to be had in HPC and data center environments.
The New Way
Over the past few months, the Taboola SRE team has moved away from stand alone DNS servers (and secondary as backup) in the different data centers and towards server clusters running under Anycast. The reasoning behind this is simple and straightforward, when the primary DNS server has an issue, while the resolver has a secondary backup, the failover time introduces latency. It’s that simple. The resolver failover time to the secondary DNS, while short, is still too long in the world of high performance computing.
Moving from one DNS server to another causes the application to wait extra time that can be avoided. Yes, there is the option to set this timeout in the resolver.conf file (here is how), that is one path to take that can reduce the timeout issue. Even with reduced timeouts, you still have all the servers waiting that additional timeout period for an answer. That seems wasteful. On top of that, we wanted more bang for our resolver buck, so to speak. We wanted more servers in each data center. After all, this is a “downtime inducing” service when it goes dark.
Building the Solution
Our goto DNS solution for years was BIND. It works, it’s very well documented, and there is a large body of knowledge easily available for most of the cases one might run into. For us, after a short check of what other options are out there, we chose to continue with BIND and add anycast (and servers). This would allow us to continue with our existing automation tools for DNS and work on the load balancing aspect of the solution only.
Choosing the clustering and load balancing mechanism for the DNS was the next step. While we already operate a few load balancing solutions, none were relevant in this case. DNS is a sessionless service, as such, introducing a network based anycast solution made the most sense for us. This choice means we don’t need additional software or hosts running as load balancers, we could use our existing network infrastructure.
In our production environment (that is every data center) we have two DNS servers which share the same ip address, and the routing infrastructure does all the rest, it directs any packet to the topologically nearest instance of the service. Each DNS server is connected with two 10G links and each link goes to a different switch, both links are configured with bonding for redundancy. The IP address of the DNS service is the loopback address which is configured on each server. This IP is advertised via BGP from the servers to the switches, which in turn learn the route and allow the connectivity. There are multiple solutions for BGP but we have picked FRR (https://frrouting.org/). FRR is easy to deploy and manage, making it an easy choice (you should notice a theme by now). Adding the support of multiple routing protocols like BGP, IS-IS, OSPF, and the configurationmanagement via puppet, is an added dose of gravy.
Monitoring
Making sure the servers are actually working and the network isn’t sending traffic to a malfunctioning server is an important part of the puzzle.Both health checks and monitoring need to be ready for production before the rollout. Our health checks include the service check itself and additional checks such as resolving, error rate and low successful resolving rate. We also check that the BGP routing is operational. There are a few more, and the idea is that some checks will kick the server out of the cluster and others will alert the team before taking action.
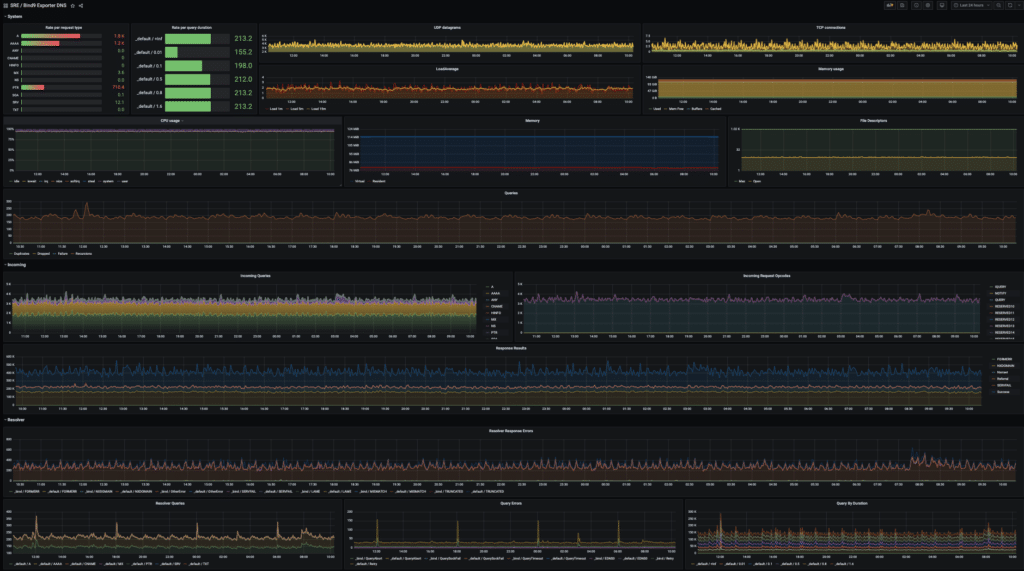
Observability for the DNS is solved with the Prometheus exporter sending the metrics out and allowing us to view the DNS activity via the Grafana dashboard. The ability to graphically view different metrics of the DNS operations allows for easy troubleshooting and when introducing DNSSEC or other configurations into the mix, this is something that you want to keep your eye on.
Into Production
The rollout to production was based on our compartmentalized network. We operate 9 global data centers in an N+1 configuration. This allows us to deploy a critical infrastructure change such as this within a limited part of our global infrastructure and observe the behavior. While a change in DNS tech (on in this case stack) is scarry, the change was unobservable to anyone outside the SRE team. Once the first data center was operational under full load for a week, the other data centers came into play in rapid succession.
Performance was also a boon when moving to the new configuration. In our production environment the resolving time was cut in half on average and in the 99.9 percentile by 16%. This improved performance is transferred to faster performance in the data center itself, as clustered applications gain from faster response times. Performance and stress testing was done using Flamethrower (by NSONE) that can be found here.
Conclusion
Investing time and engineering effort in any of the data center infrastructure services will always pay back. When that performance gain kicks in and your operations stay steady or when you have a DNS maintenance cycle and no one’s the wiser. Keeping DNS running in the data center should be taken for granted. When a host asks for resolving, that A record should come flying back blazing fast. When the primary or secondary DNS fail, no one needs to know. No service should resolve slower.
Treat yourself to an anycast DNS today.