If you fall, fall right – a tale of SRE critical incident management
By Yehuda Levi, Tal Valani, Ariel Pisetzky & Eli Azulai
Imagine this scenario – your data center is down. 1500 servers are down. Each server needs to be handled and monitored and the responsibility for each should be divided between all teammates.
Each team is looking after the status of their services. Client facing services are impacted. New information keeps flowing in from different channels and the status of the outage and servers keep changing.
How to get the list of the server affected?
How to put it all in one place?
How to assign responsibility for each?
What is the status of each server?
How can the internal clients receive ongoing status updates?
What happens if a server was intentionally down before the incident?
What happens if a more complex issue occurs and the time to handle it takes longer than the outage itself?
Jeannette Walls said “Most important thing in life is learning how to fall” and to be honest, during coronatimes we all need to get an extra lesson
Handling critical incidents is always a hard thing to do. Working together in the same space (offices, remember that?) made it a bit easier to communicate. The physicality, the fact we are all in the same place and can just see or talk to each other easily, this all made a huge difference. In COVID time we found ourselves struggling to manage such easy communications, this directly inhibits our ability to manage an incident even more. We had to step up our game.
Our journey started a few months ago, we had an incident involving multiple servers and the importance of working with a central task management system designed for IT incident management was crystallized. Not a console, not the central alerting system. This needed to be a crisis management tool that augmented our abilities in real time.
Our first trial by fire was, well, just that! Firefighters raided one of our data centers. 1500 physical servers went down that incident (you can read about it here). During that day we were able to mobilize faster, respond in a much more coordinated fashion and bring back the services faster than ever.
PART 1: Tell everybody something really bad happened
The first challenge is to make sure that when something bad is happening, everyone who needs to know – will know (and fast).
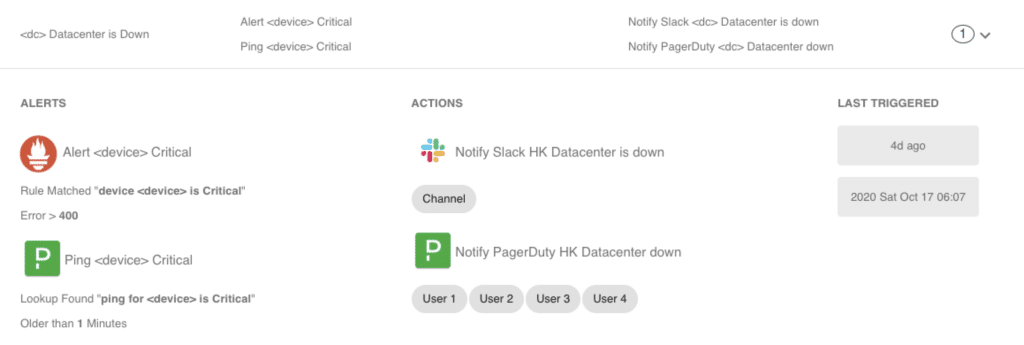
Yes, We have oncall engineers and multiple alerting systems. We have logs, metrics, dashboards, pagers, you name it, we’ve got it. On top of that we created an aggregated rule base service that monitors all kinds of sources. When a rule is matched – a set of actions can be triggered.
For example:
- paging multiple users.
- sending notifications to various channels.
- starting a conference call.
- Initiating the “critical incident flow”
PART 2: To the War Room
Alarm!
Alarm!
All hands on deck!
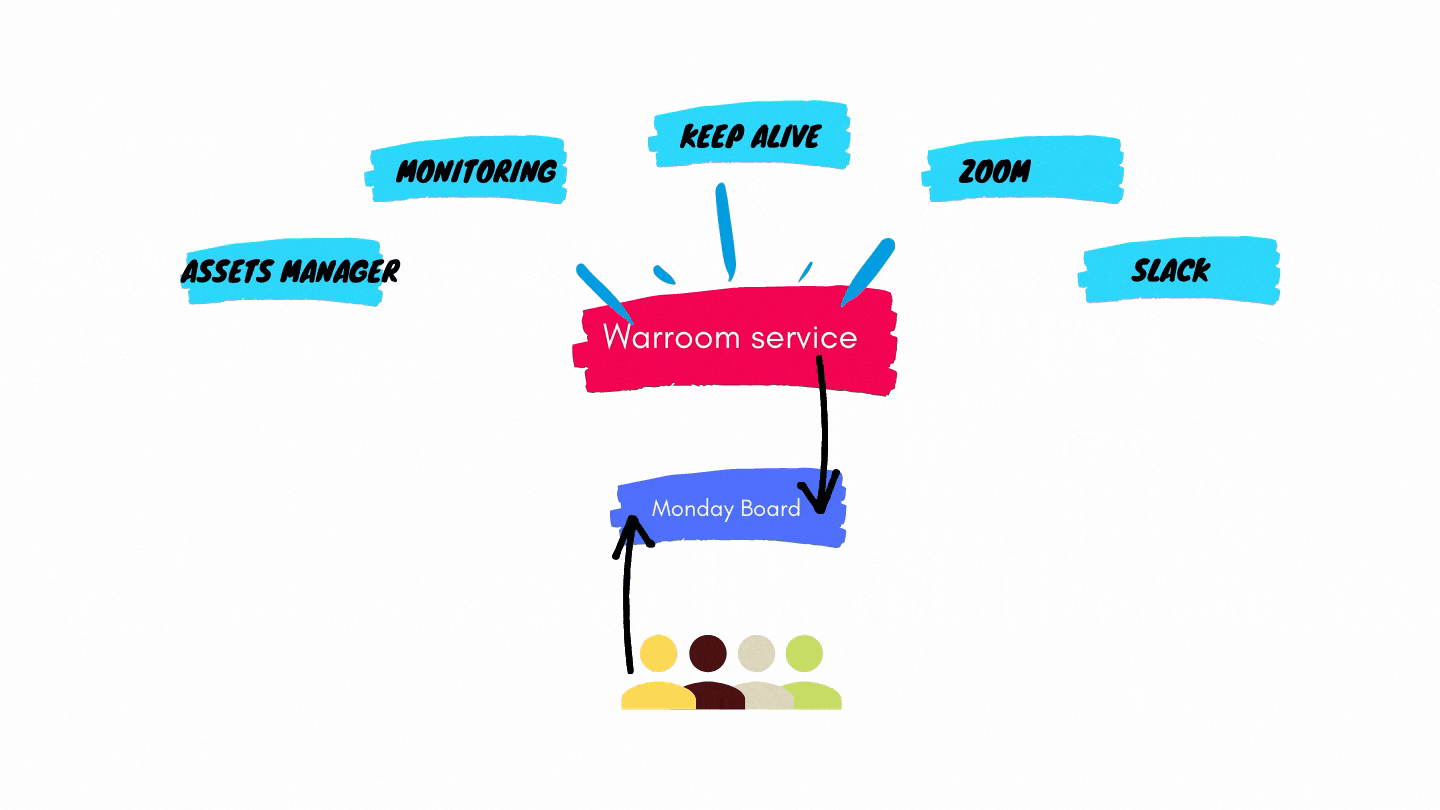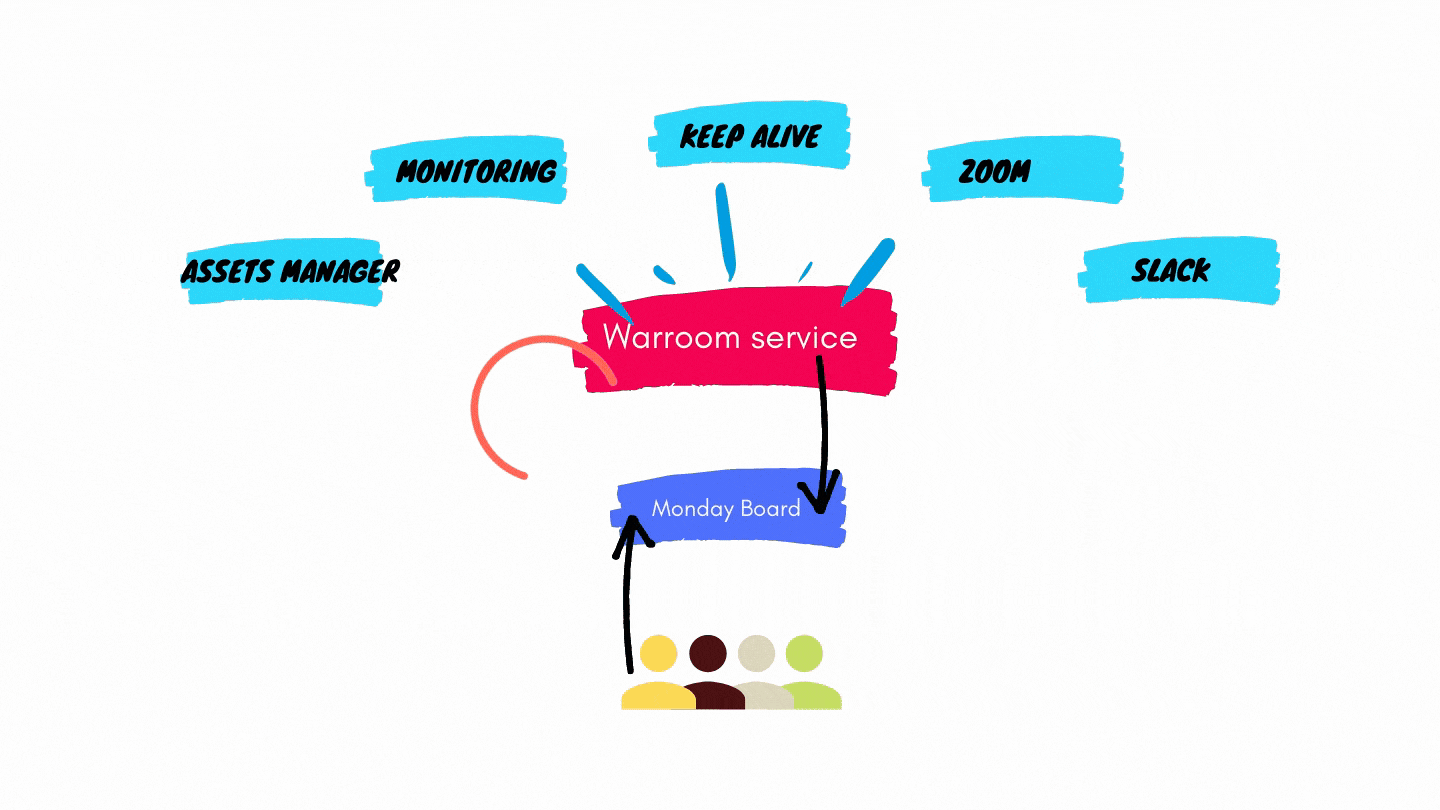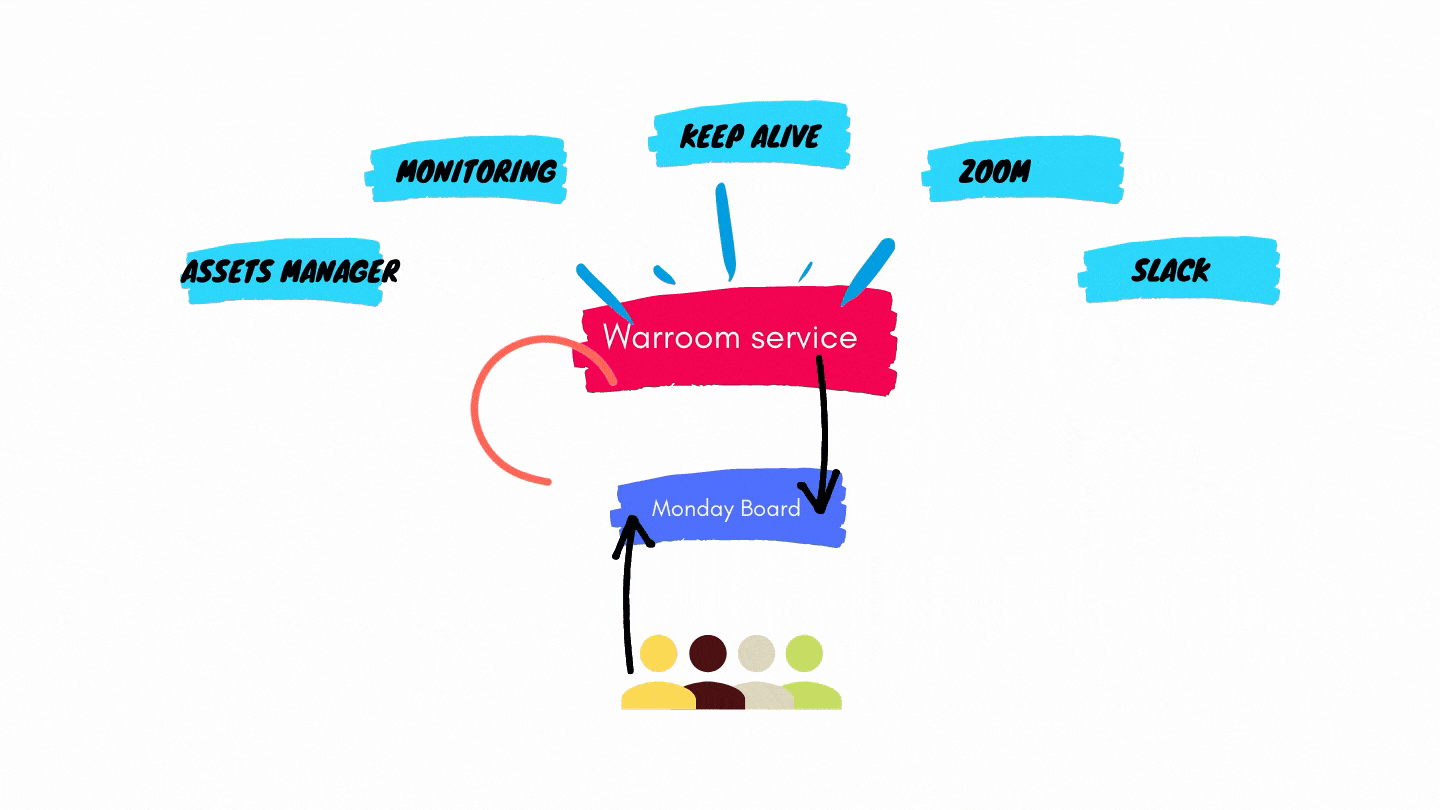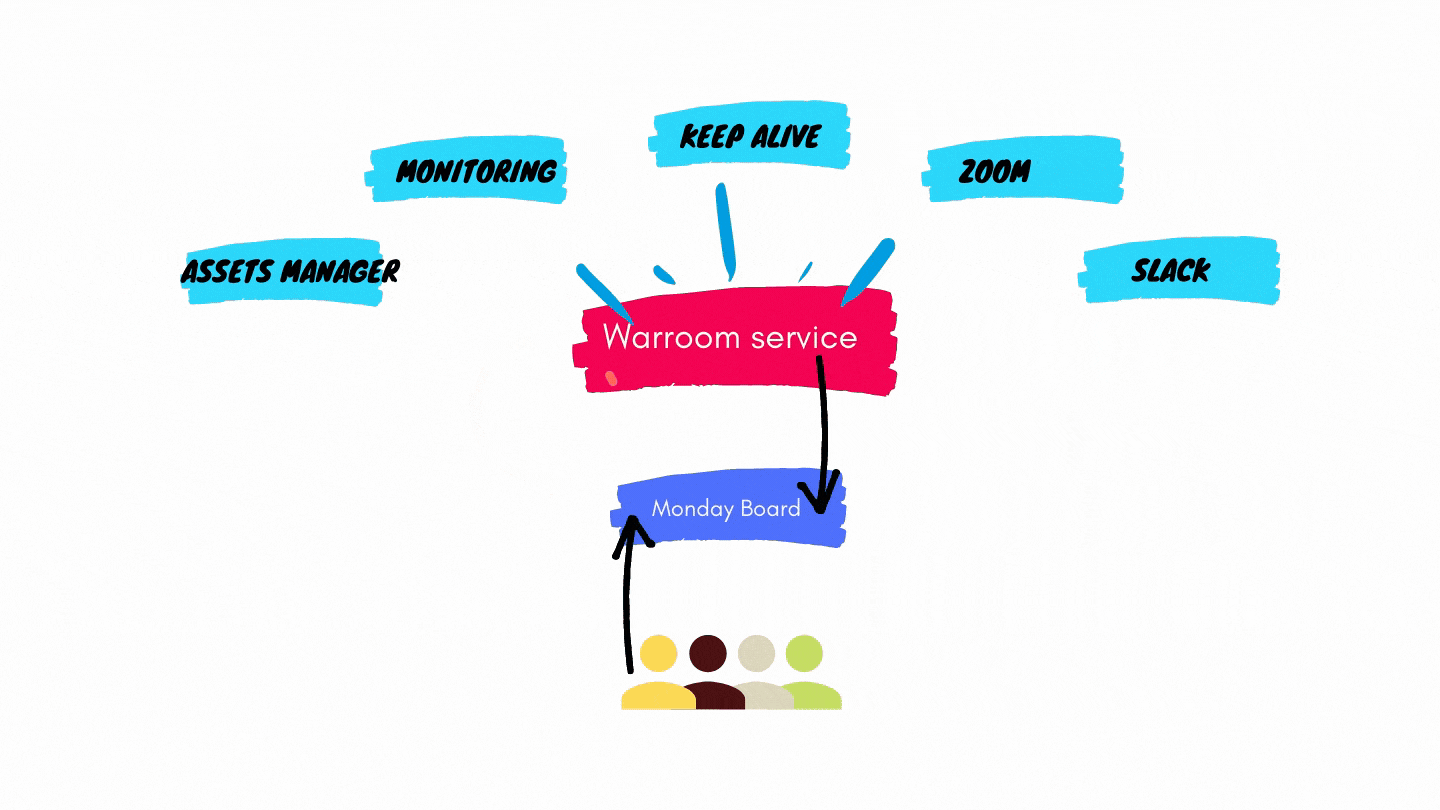
The system automatically opens the “War Room”, the incident board, where items can be assigned to engineers, priority can be set, and status can be updated.
When we thought about this service, we wanted the following:
It needs to connect multiple sources and generate actionable items.
The UI has to provide a clear view of the incident.
The different parts of the system should incorporate existing tools such as #Slack, PagerDurty, Zoom, Hashicorp Consul (to name a few).
We decided to go with Monday.com as our dashboard and lineitem state engine.
The system should be easy to build, maintain and ready to use in a short period of time.
The War Room service is triggered and generates a list of items, builds a custom Monday dashboard and pushes the items into the board – along with status, priority and other properties. The War Room service updates the board items continuously until the incident is resolved.
Simple yet not simplistic.
Key features
Multiple sources
Collecting data from multiple sources – asset management systems, alerting systems etc. and creating a detailed list of items that contain physical and virtual devices, deployments, keepalive data and more.
The service determines the priority of each item and sets it accordingly.
Pre incident existing issues can be filtered out.
Monday board
For this task we created a Python library for Monday to assist us.
We implemented some methods like:
- Boards (create and archive).
- Columns ( create, set values).
- Groups (create, fetch, archive).
- Items (fetch, create, update).
- Subitems (create).
We generate the right board for the incident
Item population
Once the items list is generated we push it into Monday and we keep managing the item’s state so we can update it in case of any change.
Keep things up-to-date
We really like our data up-to-date. So we make sure to keep updating each item every time we detect a change, so our incident manager can get the right calls
Notifications
Notifications are an important component of our service, we really need to make sure we can communicate when we need. Messages are pushed via various channels automatically to help facilitate streamlined communications with various other internal clients.
Notifications are sent when the incident starts or finishes and we invite people to the boards and to a conference call. Status changes trigger notification for owners and subscribers.
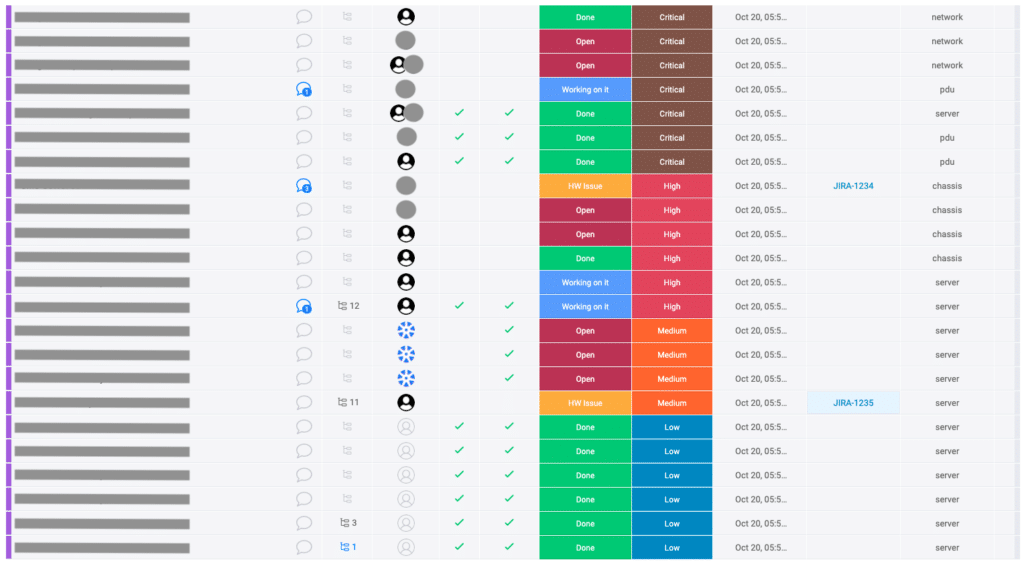
PART 3: Manage the incident
The board is created and we can get right to work.
Shift priority to where it is needed
Assign / reassign the right engineer to the right task
Get a clear status of the incident
PART 4: After the storm
A lesson should be learned
Most critical incidents require a lesson learning process so we can improve. To assist this phase we can get a clear timeline based on the board log. So this simplifies the timeline discovery process, we know exactly what has been done, when and who did it.
The ripple effect – Follow up on items
Many times once the main event is over, we all just want to continue with the less urgent problems when the sun is out. This is a natural response when you get yanked into a crisis situation. Facilitating this need, open items will remain open after the incident is resolved. This keeps us on top of the lesser issues and assures the ripple effect ends well for all involved.
Conclusions and what you take from this
Once the system was online, there was no need to convince people to use it, it was just so clear how much value this brings to everyone using it. Within weeks from the launch and after the first inciendet, the “buy-in” from the organization was impressive. The system is now used by all production facing teams, SRE, R&D and more.
Automation in SRE is the only path. There is no other way to manage the levels of tasks and the need to perform tasks on vast amounts of servers (or instances) if you do not have automation. This is the same for incident management.
Reliability when breached is always a chaotic event. On or off the cloud you always need to find a way to bring order when multiple services or servers fail and fall out of production. You need a way to bring in more SRE resources to fix the problem. The ability to multitask the team members on the different tasks within a high pressure situation is a huge win. The War room automation was our way of pulling it off.
Improving communications is always a good practice, when it helps reduce incident timelines that’s even better.