
At Taboola, we work daily on improving our Deep-Learning-based content-recommendation model. We use it to suggest personalized news articles and ads to hundreds of millions users a day, so naturally we must stick to state-of-the-art deep learning modeling methods. But our job doesn’t end there – analyzing our results is a must too, and then we sometimes return to our data science roots and apply some very basic techniques. Let’s lay such a problem out. We are investigating a deep model that behaves rather strangely: it wins over our default model for what looks like a random group of advertisers, and loses for another group. This behavior is stable in the day to day, so it looks like there might be some inherent advertisers qualities (what we’ll call – campaign features) to blame for this. You can see a typical model behavior for 4 campaigns below. So we hypothesize that […]

Sometimes we need to test urgent features fast. It has to be within a very short timeframe, when there is not enough time to run a full test plan for that feature. This might occur on different occasions. When not having enough manpower in QA to cover a full test plan for a feature. New special demands from an important client right before the release deadline. Product management needs new adjustments before the developer deploying a new product version. It can also happen when a client, team lead or PM wants a new feature and it should have been done YESTERDAY! It can also happen actively. Running every once in a while a wide post-production test, or dedicating limited time for a bug hunt. We at the Taboola Video Solution department call it “Search for a Bug Thursday”. This unplanned development might end up launching a “half baked” product. It […]

At Taboola, our goal is to predict whether users will click on the ads we present to them. Our models use all kinds of features, yet the most interesting ones tend to be related to the users’ history. Understanding how to use these features well can have a huge impact on the model’s personalization capabilities, due to the user-specific knowledge they hold. User history features vary strongly between different users; for example, one popular feature is user categories – the topics a user had previously read. An example for such a list might look like this – {“sports”, “business”, “news”}. Each value in these lists is categorical and they have multiple entries, so we name them Multi-Categorical features. Multi-Categorical lists can have any number of values per user – which means our model must handle both very long lists and completely empty lists (for new users). Supplying inputs of unknown length […]

Discover the journey of creating synchronized analog clocks using microcontrollers. Learn about power-efficient design, NTP synchronization, and more.

A few years ago, one of my friends suggested me to become a cybersecurity teacher in high school once a week as part of a program called Gvahim. I have not planned that it will contribute to my professional career, but I find a lot of analogies to my day to day role. I hope you will enjoy a different angle of management 101 guidelines. Program overview The program’s goals were to increase the knowledge of high school students in cybersecurity and increase the number of girls who study computer science. For three years in the program, students studied about Assembly, networks and operating systems, with an emphasis on security. Unlike traditional materials learned in high school, the lessons in the program put an emphasis on self-learning. The first two semesters were dedicated to learning the theoretical background using self-reading and small coding exercises. The last semester of the […]

In the following article, I describe how we came up with a way to improve the chances that our SDK library gets smoothly integrated in our customers’ Applications and reduce issues when going to production. The main idea is to take a number of significant clients’ applications and replace your existing SDK code with a new code, allowing you to see how the apps perform before you release a new SDK version. Why releasing a reliable SDK is so important Developing an SDK for mobile apps is very different from developing a standalone app. You can think of an SDK as a guest in someone else’s house. You need to behave, you can’t put your legs on the table or wipe your hands on the sofa (well, in most countries you can’t). So what I mean is that you can’t interfere with the app’s normal behavior, break some flows or […]

Delivering good product to live environment requires big effort from R&D. Under the software development life cycle, we can find 6 basic phases: Understanding the requirements, design, coding, testing, deployment (incl. A/B test, if necessary) and maintenance. But how can we measure product quality? By its stability? Scalability? Easy to maintain? Bug free code? There are probably many definitions for what is a good product, but in my opinion, the two foundation stones are product behavior & functionality as defined (be aligned with the product manager’s requirements), and zero critical bugs. The product can serve many goals, but if it doesn’t achieve the main one, it might not have a reason to exist. Naturally, customers are always expecting high quality from the product, so before releasing it to production QA should make sure that indeed critical bugs don’t exist. In order to respect these two, both R&D and QA should […]
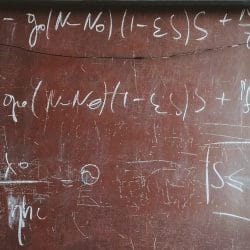
If you happen to write code for a living, there’s a pretty good chance you’ve found yourself explaining another interviewer again how to reverse a linked list or how to tell if a string contains only digits. Usually, the necessity of this B.Sc. material ends once a contract is signed, as most of these low-level questions are dealt with for us under-the-hood of modern coding languages and external libraries. Still, not long ago we found ourselves facing one such question in real-life: find an efficient algorithm for real-time weighted sampling. As naive as it might seem at first sight, we’d like to show you why it’s actually not – and then walk you through how we solved it, just in case you’ll run into something similar. So buckle up, we’ve got some statistics and integrals coming up next! Why We Need Weighted Sampling in Production? At Taboola, our core business is to personalize […]

Intro At Taboola we use Spark extensively throughout the pipeline. Regularly faced with Spark-related scalability challenges, we look for optimisations in order to squeeze the most out of the library. Often, the problems we encounter are related to shuffles. In this post we will present a technique we discovered which gave us up to 8x boost in performance for jobs with huge data shuffles. Shuffles Shuffling is a process of redistributing data across partitions (aka repartitioning) that may or may not cause moving data across JVM processes or even over the wire (between executors on separate machines).Shuffles, despite their drawbacks, are sometimes inevitable. In our case, here are some of the problems we faced: Performance hit – Jobs run longer because shuffles use network and IO resources intensively. Cluster stability – Heavy shuffles fill scratch disks of cluster machines. This affects other jobs on the same cluster , since […]
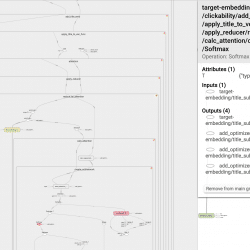
How to structure your TensorFlow graph like a software engineer So you’ve finished training your model, and it’s time to get some insights as to what it has learned. You decide which tensor should be interesting, and go look for it in your code – to find out what its name is. Then it hits you – you forgot to give it a name. You also forgot to wrap the logical code block with a named scope. It means you’ll have a hard time getting a reference to the tensor. It holds for python scripts as well as TensorBoard: Can you see that small red circle lost in the sea of tensors? Finding it is hard… That’s a bummer! It would have been much better if it looked more like this: That’s more like it! Each set of tensors which form a logical unit is wrapped inside […]