At Taboola, our goal is to predict whether users will click on the ads we present to them. Our models use all kinds of features, yet the most interesting ones tend to be related to the users’ history. Understanding how to use these features well can have a huge impact on the model’s personalization capabilities, due to the user-specific knowledge they hold.
User history features vary strongly between different users; for example, one popular feature is user categories – the topics a user had previously read. An example for such a list might look like this – {“sports”, “business”, “news”}. Each value in these lists is categorical and they have multiple entries, so we name them Multi-Categorical features. Multi-Categorical lists can have any number of values per user – which means our model must handle both very long lists and completely empty lists (for new users).
Supplying inputs of unknown length to machine learning models is an issue which needs to be addressed wisely. This post will walk you through how to integrate these varied length features in your neural network, from the most basic approach all the way to “Deep Interest”, the current state of the art.

Being average
Let’s continue with user categories. How can we turn a list of unknown length to a fixed-length feature which we can use? The most naive, yet very popular approach, is to simply average. Let’s assume we have a separate embedding of length d for each category – so that each value of the list is mapped to an Rd vector. We can use average pooling – average all of the user’s categories and receive a vector of length d every time. More formally, if emb(wj) is the embedding of the jth word of overall N words, then a user’s average pooling can be written as:

But this is far from perfect. Averaging might work well, but when the list is very long the 1/N factor creates a small final result; summing different pointing vectors may cause them to cancel each other out, and division by N makes this substantially worse (If you come from a physics/EE background this should ring a bell, since this is much like what happens in non-coherent integration). This is bad, since it hurts users with longer history vectors, which are the ones we have the most information about and can give better predictions for. Because of this, we (and the folks from Alibaba research) remove the 1/N factor and use sum-pooling on the user-histories, to ensure predictable customers don’t have negligible impact on the network.
Weight-lifting, naively
Averaging automatically assigns the same weight to all elements. Is this what we want? Let’s consider a user with this list: {‘football’, ‘tennis’, ‘basketball’, ‘fashion’}. Averaging them naively will put an emphasis on the sporting categories, and neglect “fashion”. For some, this would be accurate – people who are more interested in sports than in fashion; for others, it might not. What could we do to give the different categories different weights to better depict users?
A better solution will be to use some other information, for example: the number of past views (impressions) the user had for each category. Since the number of times a user read an article correlates with his personal taste, we can use these counts as weights and do weighted average pooling. This will help us differentiate, for example, between the following two very different users:
User 1 = {‘football’: 2, ‘tennis’:2, ‘basketball’:2, ‘fashion’:200}
User 2 = {‘football’: 2, ‘tennis’:2, ‘basketball’:2, ‘fashion’:2}
Are you paying attention?
Can we stack even more information? Say we not only have the number of each user’s views per category, but also things like the last time the user read an article of this category, or this category CTR (click-through-rate) per user (meaning, how many times the user read an article from this category out of all the times this category was presented). What would be the best way to combine these features without endless algorithm A/B testing? The answer, of course, is to harness the power of machine learning, and apply an additional layer whose job is to output a weight for each value. This is sometimes called an “attention layer”. This layer has all the relevant data available as input, and learns the ideal weights to average the values. Let’s look at an attention subnet example for a single category value – “tennis”. Assuming the embedding for “tennis” is {5,0.3,5,1,4.2}, and the user was recommended 10 tennis articles but only clicked once, the flow can be illustrated as:
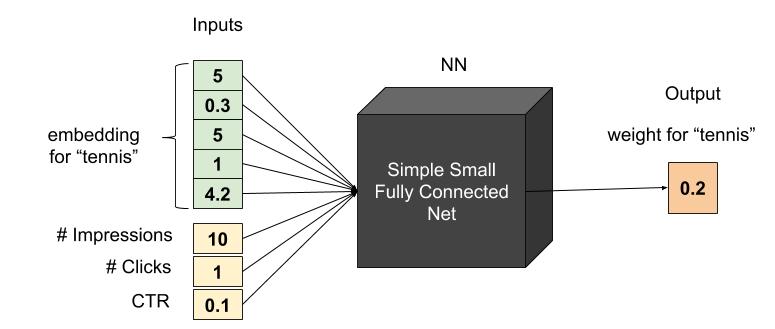
The attention layer calculates the weight for each category embedding. In the above example the calculated weight is 0.2. Say this user was also interested in “fashion” and the attention layer output the 0.5 for this category, the final calculation for this user’s history embedding would be 0.2*emb(tennis) + 0.5*emb(fashion). These attention layers learn how to utilize all the information we have about this user’s history for calculating weights for each category.
Great! But can we make this even better?
Introducing: Deep Interest architecture
Remember, we are trying to predict whether a certain user might click on a certain ad, so why not plugging-in some information about the current suggested ad? Say we have a user whose history is {“tennis-equipment”, “kids-clothes”}, and our current ad is for a tennis racket. Surely we would want more weight on the tennis-equipment and neglect the kids part for this specific case. Our previous attention layer is only designed for modeling the user’s interests, and does not consider interactions between the user’s personal taste with the ad suggested to him during the pooling stage. We would like to intertwine this user-ad interaction before the pooling occurs in order to calculate a weight which is more specific to the current ad presented to the user.
For this purpose we can use the Deep Interest architecture, a work that was presented at the KDD2018 conference by a group from the Alibaba research. If we go back to our previous illustration, we can now add an embedding for the specific ad suggested to the user:
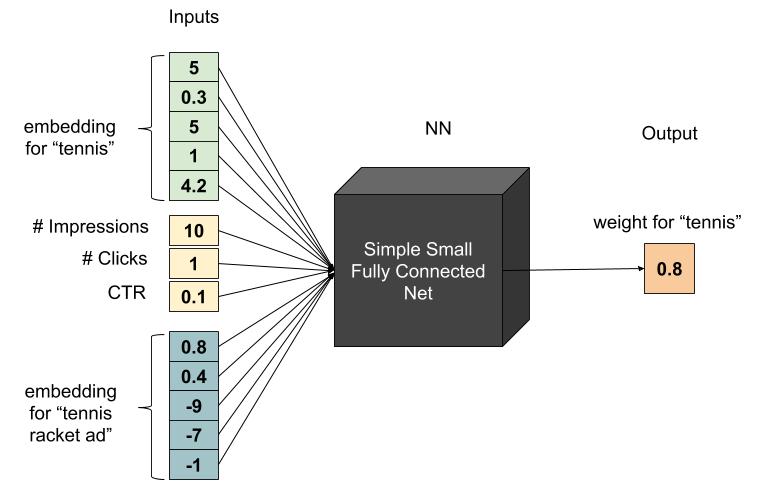
With Deep Interest, the ad features are used as inputs for the neural network twice: once as an input for the model itself (contributing information for whether or not presenting this ad to the user will lead to a click), and a second time as an input for the user’s history embedding layer (tuning the user’s history attention to the parts relevant for this specific ad).
We can also have different ways to create embeddings for the ad-features: one is to use the same embedding vector for both cases mentioned above, and another option is to generate two different embeddings for the two cases. The first option gives the embeddings twice as much gradients while training, and might converge better. In the latter, we can have two different embeddings (say embedding of size 12 for the full network, and embedding of size 3 for the user history weight layer). A shorter embedding could save run-time serving but adds more parameters to the learning process, and might lengthen training time. Choosing between the two options is of course dependent on the specific use case.
Summary
Multi-categorical features are crucial for predictions in various common problems, and particularly when trying to predict future user behavior (like clicks, conversions) from past interactions. There are simple ways to do so – but for better predictions we recommend the Deep Interest architecture, as it allows dynamic weighting of the feature vector according to the relevant context. This architecture is quite simple to implement and gives great results for many recommender systems. Go give it a shot!
