Optimize Data Center Health: Taboola employs LSTM Autoencoder for precise anomaly detection, enhancing system performance.

Taboola is responsible for billions of daily recommendations, and we are doing everything we can to make those recommendations fit each viewer’s personal taste and interests. We do so by updating our Deep-Learning based models, increasing our computational resources, improving our exploration techniques and many more. All those things though, have one thing in common – we need to understand if a change is for the better or not, and we need to do so while allowing many tests to run in parallel. We can think of many KPI’s for new algorithmic modifications – system latency, diversity of recommendations or user-interaction to name a few – but at the end of the day, the one metric that matters most for us in Taboola is RPM (revenue per mill, or revenue per 1,000 recommendations), which indicates how much money and value we create for our customers on both sides – the […]

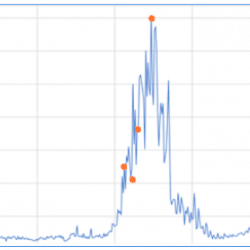
In Taboola, we deal with scale, huge scale. A small issue might turn into a disaster in a matter of hours. Re-writing and replacing an existing service with a new one is a real challenge, moreover doing it without causing downtime is SCARY. Reading logs is not an option. Logs are gigantic, unwieldy and span over many machines. It would take hours to combine and analyze them. In this post I will share with you three graphs in Grafana that I think are a must for observing new code. Let’s start… Did I break production? You write your shiny code, you (even) test it, but, how would you verify that you didn’t break the production environment? Luckily, we use Grafana, and this actually makes a big difference. My plan was to compare old code vs. new in Grafana, but, where to start? You have Grafana… let’s use it! Frankly, I […]
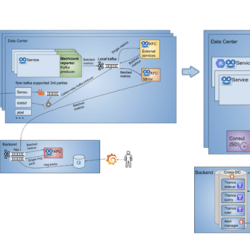
In this blogpost I will describe how we, at Taboola, changed our metrics infrastructure twice as a result of continuous scaling in metrics volume. In the past two years, we moved from supporting 20 million metrics/min with Graphite, to 80 million metrics/min using Metrictank, and finally to a framework that will enable us to grow to over 100 million metrics/min, with Prometheus and Thanos. The journey to scale begins Taboola is constantly growing. Our publishers and advertisers increase exponentially, thus our data increases, leading to a constant growth in metrics volume. We started with a basic metrics configuration of Graphite servers. We used a Graphite Reporter component to get a snapshot of metrics from MetricRegistry (a 3rd party collection of metrics belonging to dropwizard that we used) every minute, and sent them in batches to RabbitMq for the carbon-relays to consume. The carbons are part of Graphite’s backend, and are […]

About 8 months ago my team and I were facing the challenge of building our first Deep Learning infrastructure. One of my team members (a brilliant data scientist) was working on a prototype for our first deep model. The time arrived to move forward to production. I was honored to lead this effort. Our achievements: we built an infrastructure that ranks over 600K items/sec, our deep models have beaten the previous models by a large margin. This pioneer project has led the way for the subsequent Deep Learning projects at Taboola. So the prototype was ready, and I was wondering: how to go from a messy script to a production ready framework? In other words, if you are into establishing a deep model pipeline this post is for you. This blog post is focused on the training infrastructure, without the inference infrastructure. Prerequisites Assume you have basic knowledge in: Python […]
If you happen to write code for a living, there’s a pretty good chance you’ve found yourself explaining another interviewer again how to reverse a linked list or how to tell if a string contains only digits. Usually, the necessity of this B.Sc. material ends once a contract is signed, as most of these low-level questions are dealt with for us under-the-hood of modern coding languages and external libraries. Still, not long ago we found ourselves facing one such question in real-life: find an efficient algorithm for real-time weighted sampling. As naive as it might seem at first sight, we’d like to show you why it’s actually not – and then walk you through how we solved it, just in case you’ll run into something similar. So buckle up, we’ve got some statistics and integrals coming up next! Why We Need Weighted Sampling in Production? At Taboola, our core business is to personalize […]

Intro At Taboola we use Spark extensively throughout the pipeline. Regularly faced with Spark-related scalability challenges, we look for optimisations in order to squeeze the most out of the library. Often, the problems we encounter are related to shuffles. In this post we will present a technique we discovered which gave us up to 8x boost in performance for jobs with huge data shuffles. Shuffles Shuffling is a process of redistributing data across partitions (aka repartitioning) that may or may not cause moving data across JVM processes or even over the wire (between executors on separate machines).Shuffles, despite their drawbacks, are sometimes inevitable. In our case, here are some of the problems we faced: Performance hit – Jobs run longer because shuffles use network and IO resources intensively. Cluster stability – Heavy shuffles fill scratch disks of cluster machines. This affects other jobs on the same cluster , since […]

We all have these amazing machines in our development and testing labs, and we know that our real users do not share this wonderful world. They experience our products very differently from us. These differences result in two major challenges: We do not know what the users experience We cannot debug their machines As a Video Advertisement Player team, these challenges are multiplied. Why? Our product is a third party script that serves other third party scripts for websites. Your code runs on different platforms As a third party web product, you do not know which websites your code runs on. Websites have a variety of frameworks, architectures and styles. Frameworks – change the browser’s core behavior, for example, redefining methods, which challenges the product’s basic behavior. Architectures – affect the website’s performance, which impacts on the product’s natural flow. Styles -manipulate the product’s look and feel. Running […]

Prioritizing Kafka Topic Consumption: How I Developed a Mechanism to Optimize Message Handling. Discover how to handle messages efficiently.

Large production pipelines in TensorFlow are quite difficult to pull off. Training small models is easy, and we mostly do this at first, but as soon as we get to the rest of the pipeline, complexity rapidly mounts. One reason is that the “Computation Graph” abstraction used by TensorFlow is a close, but not exact match for the ML model we expect to train and use. How so? Typically a model will be used in at least three ways: Training – finding the correct weights or parameters for the model given some training data. Often done periodically as new data arrives. Evaluation – calculating various metrics during training on a different data set to evaluate training quality or for cross validation. Serving – on-demand prediction for new data There could be more modes. For example we could re-train an existing model or apply the model to a large amount of […]