As a team member in the Scale Performance Data group of Taboola’s R&D, I had the opportunity to develop a mechanism which prioritizes the consumption of Kafka topics. I did so to tackle a challenge we had of handling messages that are being sent from hundreds of frontend servers around the world by our time-series based backend servers.
In this post, I will focus on three things.
- Why we needed such a mechanism – the problem
- Code snippets showing how I put said mechanism in place – the solution
- Issues I faced with Kafka – bumpers on the way to the solution
Prerequisites
Assume you have basic knowledge in:
- Java multithreading multithreading in Java
- Kafka
Data coming from all over the world needs to be divided by minutes
Taboola has a few hundred frontend servers. They serve more than half a million requests per minute – and this number grows steadily. The frontend servers send data to our backend servers using Kafka, this data is aggregated and analyzed by our backend servers.
The backend servers need to have the data arranged by minutes before they can analyze it.
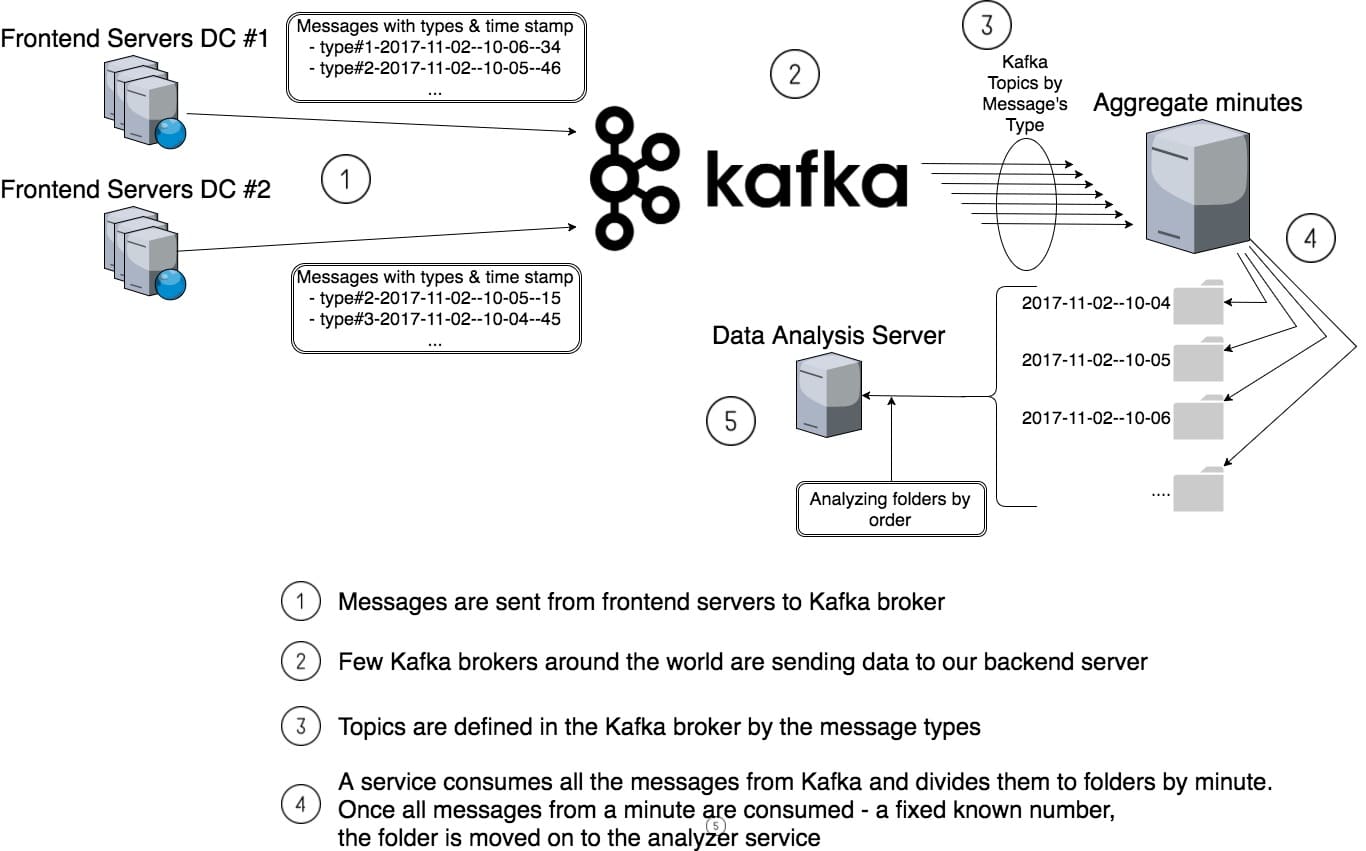
Things might get complicated when dealing with big data
Imagine the next scenario, we have a problem in some data center (packet lost, Kafka issues, maintenance, etc.). As a result, messages from that DC arrive to the backend server in delay. Meanwhile, messages from other DCs arrive on time. We never finish to consume all the messages of “old” minutes, but we keep opening more and more “new” minutes. The analysis server can’t process the folders, while they are in this “standby” mode. Eventually, memory is filled up and new messages can’t be consumed from Kafka.
Another reason such a gap may occur, is that our topics are of different message types. Some types are lighter and faster to consume than others.
We wanted to consume messages with a maximal gap of a few minutes. That way we prevent opening new buckets before closing old ones. In other words, only after all the messages from “old” minutes are consumed, will messages from “new” minutes be consumed.
Which solution we decided to implement
We decided to develop a mechanism to prioritize the consumption of Kafka topics. Such a mechanism will check if we want to process a message that was consumed from Kafka, or hold the processing for later.
Using the graph below, I will describe what I am expecting the consumption of messages from Kafka to be like.
What was the expected result
The next graph shows a metric that measures every time a message is consumed from a Kafka broker. Each line represents a Kafka consumer. We measure the gap between the current time and the time that the message was sent from the frontend server (as explained above). For example, a gap of 10 hours means that we are now processing a message that was produced in the frontend server 10 hours ago. Usually and ideally, this gap should be a few minutes.
Before turning prioritization on, some topics are consumed faster than others. This causes some topics to close the gap faster than others (to the right of the yellow arrow). Our mechanism should prioritize the tardy topics. Such that it will make the preliminary ones to wait (to the right of the red arrow). You can see that the gap of preliminary ones is steady (horizontal line) until tardy topics narrow the gap.
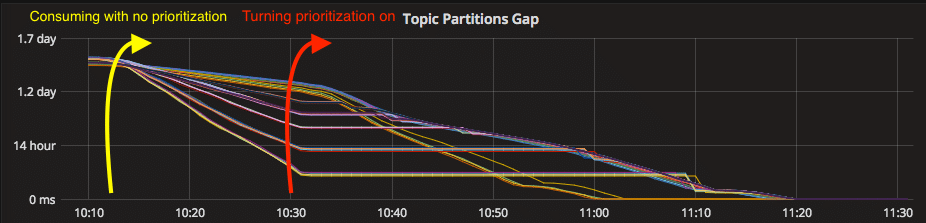
How do we get where we want to be?
Blocking Kafka topics we don’t want to process right now
We map between the partitions and Booleans, which blocks the consuming of each partition if necessary, topicPartitionLocks. Blocking the preliminary ones, while continuing to consume from the tardy ones, creates prioritization of topics. A TimerTask updates this map and our consumers check if they are “allowed” to consume or have to wait – as you can see in the method waitForLatePartitionIfNeeded.
Prioritizer class
public class Prioritizer extends TimerTask {
private Map<String, Boolean> topicPartitionLocks = new ConcurrentHashMap<>();
private Map<String, Long> topicPartitionLatestTimestamps = new ConcurrentHashMap<>();
@Override
public void run(){
updateTopicPartitionLocks();
}
private void updateTopicPartitionLocks() {
Optional<Long> minValue = topicPartitionLatestTimestamps.values().stream().min((o1, o2) -> (int) (o1 - o2));
if(! minValue.isPresent()) {
return;
}
Iterator it = topicPartitionLatestTimestamps.entrySet().iterator();
while (it.hasNext()) {
Boolean shouldLock = false;
Map.Entry<String, Long> pair = (Map.Entry)it.next();
String topicPartition = pair.getKey();
if(pair.getValue() > (minValue.get() + maxGap)) {
shouldLock = true;
if(isSameTopicAsMinPartition(minValue.get(), topicPartition)) {
shouldLock = false;
}
}
topicPartitionLocks.put(topicPartition, shouldLock);
}
}
public boolean isLocked(String topicPartition) {
return topicPartitionLocks.get(topicPartition).booleanValue();
}
}
waitForLatePartitionIfNeeded method
private void waitForLatePartitionIfNeeded(final String topic, int partition) {
String topicPartition = topic + partition;
prioritizer.getTopicPartitionLocks.putIfAbsent(topicPartition);
while(spaFileBufferPrioritizer.isLocked(topicPartition)) {
monitorWaitForLatePartitionTimes(topicPartition, startTime);
Misc.sleep(timeToWaitBetweenGapToTardyPartitionChecks.get());
}
}
We let our mechanism run for a while, and unfortunately things were not as expected.
Avoid Rebalance
Turning our prioritization, we saw a strange pattern in the “Topic Partition Gap” graph. We saw that the consumption is stuck very often. Trying to understand what was happening, we found that those breaks in consuming were a result of Kafka rebalancing. We can see this very clearly in the graph below. The horizontal lines represent a period of time where the gap stays steady. In other words, we are not consuming messages.
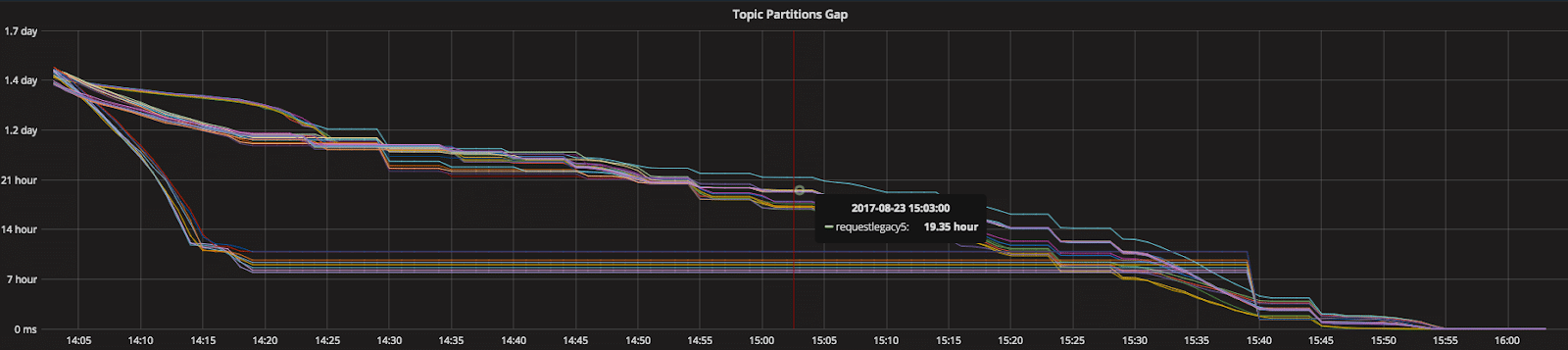
What happened, is that whenever we paused the consumer, Kafka thought that this consumer was“dead” and started rebalancing. Moreover, when this consumer continued consuming, it was no longer registered in the broker, so Kafka had to rebalance again.
This mechanism of Kafka is what makes it reliable and efficient, but in our scenario it was unnecessary. It is important to remember that if we were consuming from multiple machines this mechanism would obviously have been necessary.
In order to prevent this rebalancing, we changed the next configuration in Kafka
request.timeout.ms: 7300000 (~2hrs)
max.poll.interval.ms: 7200000 (2hrs)
These configurations will substantially lengthen the time that the broker waits for a consumer to consume, before considering it as “dead” and rebalancing.
Monitoring
Monitoring is very important, especially when working with thousands of messages consumed from Kafka every second. Using logs at such rates is irrelevant. In order to follow the processing behavior and performance, we defined metrics which measure the blocking term. In this case we defined a metric which measures the gap between the current time and the time that the message was sent from the frontend server. For example, that way I discovered the rebalance issue.
Great Success
This actually worked very well and you can see the result in the graph I showed before (to the right of the red arrow). We blocked the consumption of preliminary topics (horizontal line) until tardy topics narrowed the gap.
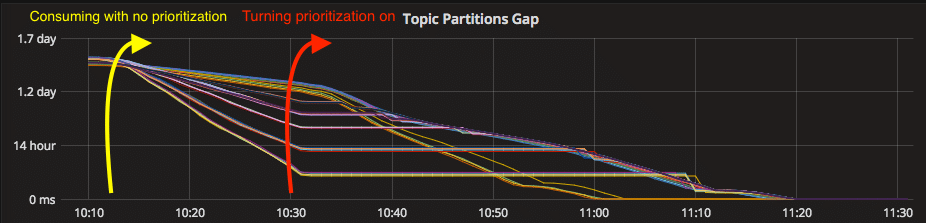
Lastly, to summarize, 3 steps you should take to prioritize you Kafka topics
- Block topics: you can define any condition you would like to for blocking topics. I used a condition about the time gap. You could use the concept of the above code.
- Prevent rebalancing: change Kafka configuration as described above.
- Monitor your results: follow your performance by defining a metric to measure your blocking term.
That’s it for now, I hope you find this post useful ☺