
At Taboola, we work daily on improving our Deep-Learning-based content-recommendation model. We use it to suggest personalized news articles and ads to hundreds of millions users a day, so naturally we must stick to state-of-the-art deep learning modeling methods. But our job doesn’t end there – analyzing our results is a must too, and then we sometimes return to our data science roots and apply some very basic techniques. Let’s lay such a problem out. We are investigating a deep model that behaves rather strangely: it wins over our default model for what looks like a random group of advertisers, and loses for another group. This behavior is stable in the day to day, so it looks like there might be some inherent advertisers qualities (what we’ll call – campaign features) to blame for this. You can see a typical model behavior for 4 campaigns below. So we hypothesize that […]

Introduction Newsrooms are under constant pressure to deliver the most up to date, relevant, and engaging information possible. At Taboola, we are building tools to make this faster, easier, and now–predictable. As soon as an article is published the team has a critical eye on engagement data. Garnering insight on article performance as soon as possible is critical for guiding content strategy. Some articles receive wide attention immediately, drawing hundreds of thousands of page views within minutes, others may only see the first page view after a few hours. Taboola aims to narrow this gap even further by leveraging Machine Learning Models to predict article performance the moment after it becomes available to the reader. Read on for details on our latest research and fascinating discoveries around predicting article performance! Article Data Taboola Newsroom is a real-time optimization technology that empowers editorial teams with actionable data around what stories, headlines, […]

At Taboola, our goal is to predict whether users will click on the ads we present to them. Our models use all kinds of features, yet the most interesting ones tend to be related to the users’ history. Understanding how to use these features well can have a huge impact on the model’s personalization capabilities, due to the user-specific knowledge they hold. User history features vary strongly between different users; for example, one popular feature is user categories – the topics a user had previously read. An example for such a list might look like this – {“sports”, “business”, “news”}. Each value in these lists is categorical and they have multiple entries, so we name them Multi-Categorical features. Multi-Categorical lists can have any number of values per user – which means our model must handle both very long lists and completely empty lists (for new users). Supplying inputs of unknown length […]

About 8 months ago my team and I were facing the challenge of building our first Deep Learning infrastructure. One of my team members (a brilliant data scientist) was working on a prototype for our first deep model. The time arrived to move forward to production. I was honored to lead this effort. Our achievements: we built an infrastructure that ranks over 600K items/sec, our deep models have beaten the previous models by a large margin. This pioneer project has led the way for the subsequent Deep Learning projects at Taboola. So the prototype was ready, and I was wondering: how to go from a messy script to a production ready framework? In other words, if you are into establishing a deep model pipeline this post is for you. This blog post is focused on the training infrastructure, without the inference infrastructure. Prerequisites Assume you have basic knowledge in: Python […]

For the past year, my team and I have been working on a personalized user experience in the Taboola feed. We used Multi-Task Learning (MTL) to predict multiple Key Performance Indicators (KPIs) on the same set of input features, and implemented a Deep Learning (DL) model in TensorFlow to do so. Back when we started, MTL seemed way more complicated to us than it does now, so I wanted to share some of the lessons learned. There are already quite a few posts about implementing MTL in a DL model (1, 2, 3). In this post I will share some specific points to consider when implementing MTL in a Neural Network (NN). I will also present simple TensorFlow solutions to overcome the discussed issues. Sharing is caring We wanted to start with the basic approach of hard parameter sharing. Hard sharing means we have a shared subnet, followed by […]
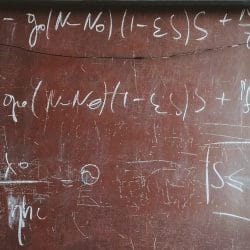
If you happen to write code for a living, there’s a pretty good chance you’ve found yourself explaining another interviewer again how to reverse a linked list or how to tell if a string contains only digits. Usually, the necessity of this B.Sc. material ends once a contract is signed, as most of these low-level questions are dealt with for us under-the-hood of modern coding languages and external libraries. Still, not long ago we found ourselves facing one such question in real-life: find an efficient algorithm for real-time weighted sampling. As naive as it might seem at first sight, we’d like to show you why it’s actually not – and then walk you through how we solved it, just in case you’ll run into something similar. So buckle up, we’ve got some statistics and integrals coming up next! Why We Need Weighted Sampling in Production? At Taboola, our core business is to personalize […]

A joint post with Ofri Mann We went to ICLR to present our work on debugging ML models using uncertainty and attention. Between cocktail parties and jazz shows in the wonderful New Orleans (can we do all conferences in NOLA please?) we also saw a lot of interesting talks and posters. Below are our main takeaways from the conference. Main themes A good summary of the themes was in Ian Goodfellow’s talk, in which he said that until around 2013 the ML community was focused on making ML work. Now that it’s working on many different applications given enough data, the focus has shifted towards adding more capabilities to our models: we want them to comply to some fairness, accountability and transparency constraints, to be robust, use labels efficiently, adapt to different domains and so on. A slide on ML topics, from Ian Goodfellow’s talk We noticed a […]

About a year ago we incorporated a new type of feature into one of our models used for recommending content items to our users. I’m talking about the thumbnail of the content item: Up until that point we used the item’s title and metadata features. The title is easier to work with compared to the thumbnail – machine learning wise. Our model has matured and it was time to add the thumbnail to the party. This decision was the first step towards a horrible bias introduced into our train-test split procedure. Let me unfold the story… Setting the scene From our experience it’s hard to incorporate multiple types of features into a unified model. So we decided to take baby steps, and add the thumbnail to a model that uses only one feature – the title. There’s one thing you need to take into account when working with these […]

If you’ve been following our tech blog lately, you might have noticed we’re using a special type of neural networks called Mixture Density Network (MDN). MDNs do not only predict the expected value of a target, but also the underlying probability distribution. This blogpost will focus on how to implement such a model using Tensorflow, from the ground up, including explanations, diagrams and a Jupyter notebook with the entire source code. What are MDNs and why are they useful? Real life data is noisy. While quite irritating, that noise is meaningful, as it gives a wider perspective of the origins of the data. The target value can have different levels of noise depending on the input, and this can have a major impact on our understanding of the data. This is better explained with an example. Assume the following quadratic function: Given x as input, we have a deterministic output […]

So you just finished designing that great neural network architecture of yours. It has a blazing number of 300 fully connected layers interleaved with 200 convolutional layers with 20 channels each, where the result is fed as the seed of a glorious bidirectional stacked LSTM with a pinch of attention. After training you get an accuracy of 99.99%, and you’re ready to ship it to production. But then you realize the production constraints won’t allow you to run inference using this beast. You need the inference to be done in under 200 milliseconds. In other words, you need to chop off half of the layers, give up on using convolutions, and let’s not get started about the costly LSTM… If only you could make that amazing model faster! Sometimes you can Here at Taboola we did it. Well, not exactly… Let me explain. One of our models has to predict […]