
Some of the problems we tackle using machine learning involve categorical features that represent real world objects, such as words, items and categories. So what happens when at inference time we get new object values that have never been seen before? How can we prepare ourselves in advance so we can still make sense out of the input? Unseen values, also called OOV (Out of Vocabulary) values, must be handled properly. Different algorithms have different methods to deal with OOV values. Different assumptions on the categorical features should be treated differently as well. In this post, I’ll focus on the case of deep learning applied to dynamic data, where new values appear all the time. I’ll use Taboola’s recommender system as an example. Some of the inputs the model gets at inference time contain unseen values – this is common in recommender systems. Examples include: Item id: each recommendable item gets […]
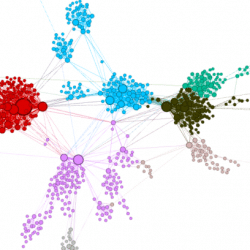
In the last couple of years deep learning (DL) has become a main enabler for applications in many domains such as vision, NLP, audio, click stream data etc. Recently researchers started to successfully apply deep learning methods to graph datasets in domains like social networks, recommender systems and biology, where data is inherently structured in a graphical way. So how do Graph Neural Networks work? Why do we need them? The Premise of Deep Learning In machine learning tasks involving graphical data, we usually want to describe each node in the graph in a way that allows us to feed it into some machine learning algorithm. Without DL, one would have to manually extract features, such as the number of neighbors a node has. But this is a laborious job. This is where DL shines. It automatically exploits the structure of the graph in order to extract features for […]

About a year ago we incorporated a new type of feature into one of our models used for recommending content items to our users. I’m talking about the thumbnail of the content item: Up until that point we used the item’s title and metadata features. The title is easier to work with compared to the thumbnail – machine learning wise. Our model has matured and it was time to add the thumbnail to the party. This decision was the first step towards a horrible bias introduced into our train-test split procedure. Let me unfold the story… Setting the scene From our experience it’s hard to incorporate multiple types of features into a unified model. So we decided to take baby steps, and add the thumbnail to a model that uses only one feature – the title. There’s one thing you need to take into account when working with these […]

So you just finished designing that great neural network architecture of yours. It has a blazing number of 300 fully connected layers interleaved with 200 convolutional layers with 20 channels each, where the result is fed as the seed of a glorious bidirectional stacked LSTM with a pinch of attention. After training you get an accuracy of 99.99%, and you’re ready to ship it to production. But then you realize the production constraints won’t allow you to run inference using this beast. You need the inference to be done in under 200 milliseconds. In other words, you need to chop off half of the layers, give up on using convolutions, and let’s not get started about the costly LSTM… If only you could make that amazing model faster! Sometimes you can Here at Taboola we did it. Well, not exactly… Let me explain. One of our models has to predict […]

Imagine you’re walking down the street and you see a nice car you’re thinking of buying. Just by pointing your phone camera, you can see relevant content about that car. How cool is that?! That was our team’s idea that awarded us first place in the recent Taboola R&D hackathon aptly named – Taboola Zoom! Every year Taboola holds a global R&D hackathon for its 350+ engineers aimed at creating ideas for cool potential products or just some fun experiments in general. This year, 33 teams worked for 36 hours to come up with ideas that are both awesome and helpful to Taboola. Some of the highlights included a tool that can accurately predict the users’ gender based on their browsing activity and an integration to social networks for Taboola Feed. Our team decided to create an AR (Augmented Reality) application that allows a user to get content recommendations, […]

Introduction One of the key creative aspects of an advertisement is choosing the image that will appear alongside the advertisement text. The advertisers aim is to select an image that will draw the attention of the users and get them to click on the add, while remaining relevant to the advertisement text. Say that you’re an advertizer wanting to place a new ad titled “15 healthy dishes you must try”. There are endless possibilities of choosing the image thumbnail to go along with this title, clearly some more clickable than others. One can apply best practices in choosing the thumbnail, but manually searching for the best image (out of possibly thousands that fit this title) is time consuming and impractical. Moreover, there is no clear way of quantifying how much an image is related to a title and more importantly – how clickable the image is, compared to other […]
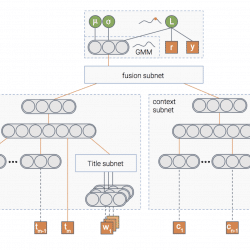
In the first post of the series we discussed three types of uncertainty that can affect your model – data uncertainty, model uncertainty and measurement uncertainty. In the second post we talked about various methods to handle the model uncertainty specifically . Then, in our third post we showed how we can use the model’s uncertainty to encourage exploration of new items in recommender systems. Wouldn’t it be great if we can handle all three types of uncertainty in a principled way using one unified model? In this post we’ll show you how we at Taboola implemented a neural network that estimates both the probability of an item being relevant to the user, as well as the uncertainty of this prediction. Let’s jump to the deep water A picture is worth a thousand words, isn’t it? And a picture containing a thousand neurons?… In any case, this is the […]

Now that we know what uncertainty types exist and learned some ways to model them, we can start talking about how to use them in our application. In this post we’ll introduce the exploration-exploitation problem and show you how uncertainty can help in solving it. We’ll focus on exploration in recommender systems, but the same idea can be applied in many applications of reinforcement learning – self driving cars, robots, etc. Problem Setting The goal of a recommender system is to recommend items that the users might find relevant. At Taboola, relevance is expressed via a click: we show a widget containing content recommendations, and the users choose if they want to click on one of the items. The probability of the user clicking on an item is called Click Through Rate (CTR). If we knew the CTR of all the items, the problem of which items to recommend […]

Understanding what a model doesn’t know is important both from the practitioner’s perspective and for the end users of many different machine learning applications. In our previous blog post we discussed the different types of uncertainty. We explained how we can use it to interpret and debug our models. In this post we’ll discuss different ways to obtain uncertainty in Deep Neural Networks. Let’s start by looking at neural networks from a Bayesian perspective. Bayesian learning 101 Bayesian statistics allow us to draw conclusions based on both evidence (data) and our prior knowledge about the world. This is often contrasted with frequentist statistics which only consider evidence. The prior knowledge captures our belief on which model generated the data, or what the weights of that model are. We can represent this belief using a prior distribution p(w) over the model’s weights. As we collect more data we update the […]

As deep neural networks (DNN) become more powerful, their complexity increases. This complexity introduces new challenges, including model interpretability. Interpretability is crucial in order to build models that are more robust and resistant to adversarial attacks. Moreover, designing a model for a new, not well researched domain is challenging and being able to interpret what the model is doing can help us in the process. The importance of model interpretation has driven researchers to develop a variety of methods over the past few years and an entire workshop was dedicated to this subject at the NIPS conference last year. These methods include: LIME: a method to explain a model’s prediction via local linear approximation Activation Maximization: a method for understanding which input patterns produce maximal model response Feature Visualizations Embedding a DNN’s layer into a low dimensional explanation space Employing methods from cognitive psychology Uncertainty estimation methods – the focus of […]