Do you ever go to a local boutique brewery and buy a Carlsberg? Drive to your local farmer to buy Walmart packaged tomatoes? Of course not. You want to get a local experience, beer that is brewed from your neighboring produce. News is no different. When browsing your hometown’s news site, you hope to find uniquely related articles.
Local content por favor!
Taboola collaborates with a substantial number of local news publishers through serving organic content across their site. These publishers are dedicated to serving local news. However, identifying whether a news article is about local news or not, can be challenging. Nowadays, straightforward solutions might be: a) explicit tagging by the editors of articles being local or national and b) extracting the location that the article is referring to from the article’s text with Named Entity Recognition models (NERs). The first solution requires a non-negligible effort from publishers and the second works well only when the name of the location is explicitly mentioned. Now consider the following examples: “A Dolphins football player felt sick today” or “Governor DeSantis has consistently improved his city’s attractiveness”. From an initial examination, no explicit location appears in those titles, but when looking deeper, the Dolphins are actually a football team in Miami, and Ron DeSantis is currently the Governor of Florida. Implicit locations understanding could increase the location coverage significantly.
ChatGPT? Don’t mind if I do
Detecting the implicit locations seems pretty complex. For the examples above, we could have used a Knowledge Graph that will match between Dolphins to Miami Dolphins which is a sports team in Miami. Can Large Language Models (LLMs), such as ChatGPT and its kind, which seem to have a built-in Knowledge graph, do that matching easily? In order to answer this question, we took 2K english titles of news articles, and sent them to ChatGPT, asking to extract the location entities from the title, such as city, state and country.
The task was not straightforward, and we had to implement prompt engineering principles such as In-context Learning [1], for giving the engine a context about the task, for example: “Imagine you are an editor of a newspaper, try to extract the city, state and country from the given titles”. In addition, we brokedown the task into steps using Chain-of-thought [2] technique, and added guidelines for specific categories that the articles are related to, such as sports, business and politics, for easy identification of the location entities (e.g., “Let’s work step-by-step. If this is a sports item, first search for the sports team name, then check its hometown, and then look for the state and country”). Finally, we asked to return the result in simple json format (see Table 1 below).
| a) Json result of sports item | b) Json result of business/ political item |
| {“title”: “A football player in the Dolphins felt sick today”, “title_city”:”Miami”, “title_state”:”Florida”, “title_country”:”United States”, “sports_team”:””Miami Dolphins”, “sports_hometown”:”Miami”, “sports_state”:”Florida”, “sports_country”:”United States”} |
{“title”: “Republican crusade to convert UNC-Chapel Hill will lead to its demise”, “title_city”:”Chapel Hill”, “title_state”:”North Carolina”, “title_country”:”United States”, “political_party”:”Republican”, “business”:”UNC-Chapel Hill”, “business_city”:”Chapel Hill”, “business_state”:”North Carolina”, “business_country”:”United States”} |
Table 1: Few shot example of sports item (a) and business item (b) and the LLM result as a json. The json contains dedicated attributes per category in order to make the task easier of the model to extract the location entities. In (a) there are specific attributes regarding the name of the sport team and its hometown. In (b) we ask specifically for the political party and the business name.
We used Few Shot Prompting [1] to send specific examples, positive and negative ones, in order to improve the consistency of ChatGPT. Once done, we compared the results of both GPT 3.5 and GPT 4 against our current NER engine. The specific questions on sports such as “What is the sports team name and where is it playing?” contributed 3% more to the coverage of local items in GPT 3.5 and 6% more in GPT 4 (see Fig. 1a). While specific questions on business or politics did not contribute that much (e.g., “Where is the business headquarters?”, “What is the political party related to that person and where is it based?”). In sum, GPT 4 was 6 times better than NER, GPT 3.5 was 3.5 times (haha!) better than NER, and in total NER had an answer that was different from GPT 3.5 in 1% of the cases and from GPT 4 in 0.5% of the cases.
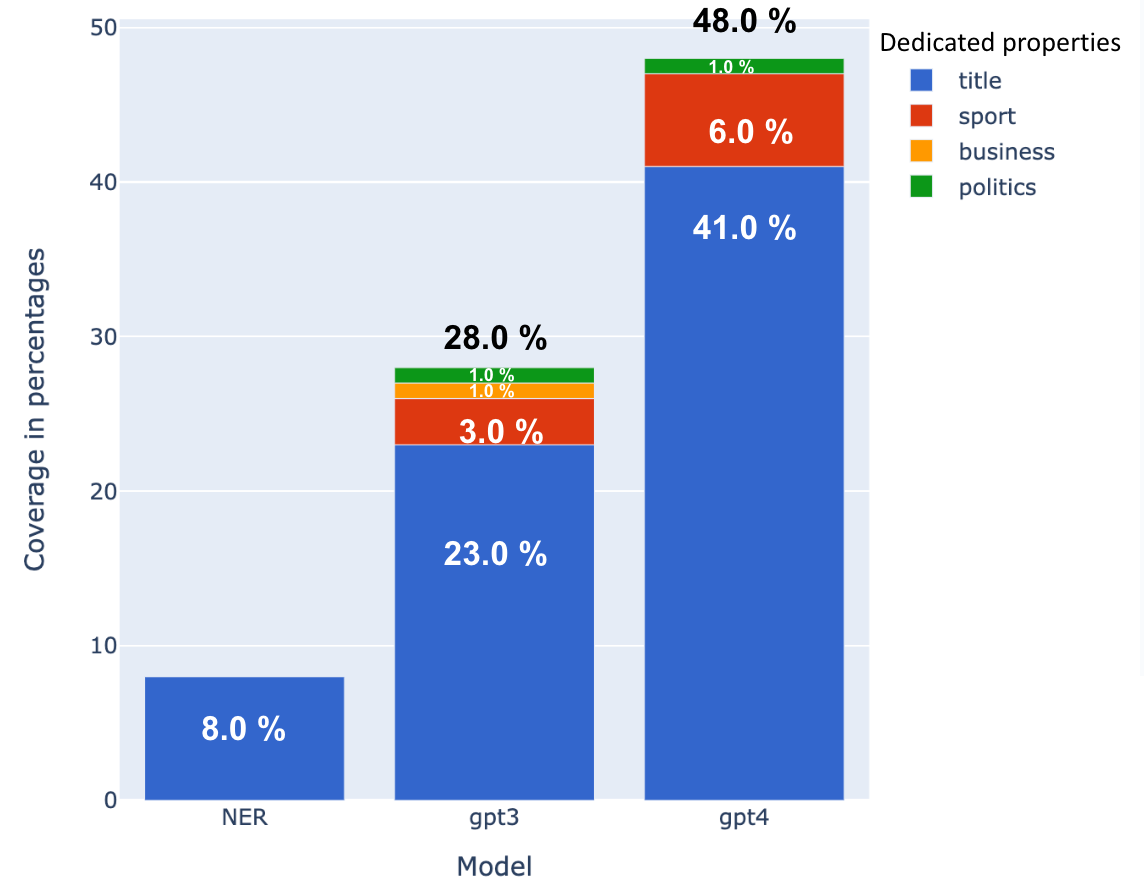
Figure 1a: Classifying news articles based on titles using NER vs. ChatGPT. (a) One day of 2K unique titles of one day sent to NER, gpt-3.5-turbo-0301 and openai-gpt4-32k for extracting the location of the titles (city/ state/ country). The blue bars are the location entities extracted only from the title (implicit and explicit). The red bars are the added value to the coverage contributed from the specific questions on sports. Yellow and green signifies the added value to the coverage contributed by specific questions on business or politics.
We tested this further with ~8K unique titles over a week only with GPT 3.5 and only on sports sections and saw that there is a potential of using LLMs to increase the coverage of location entities (see Fig. 1b).
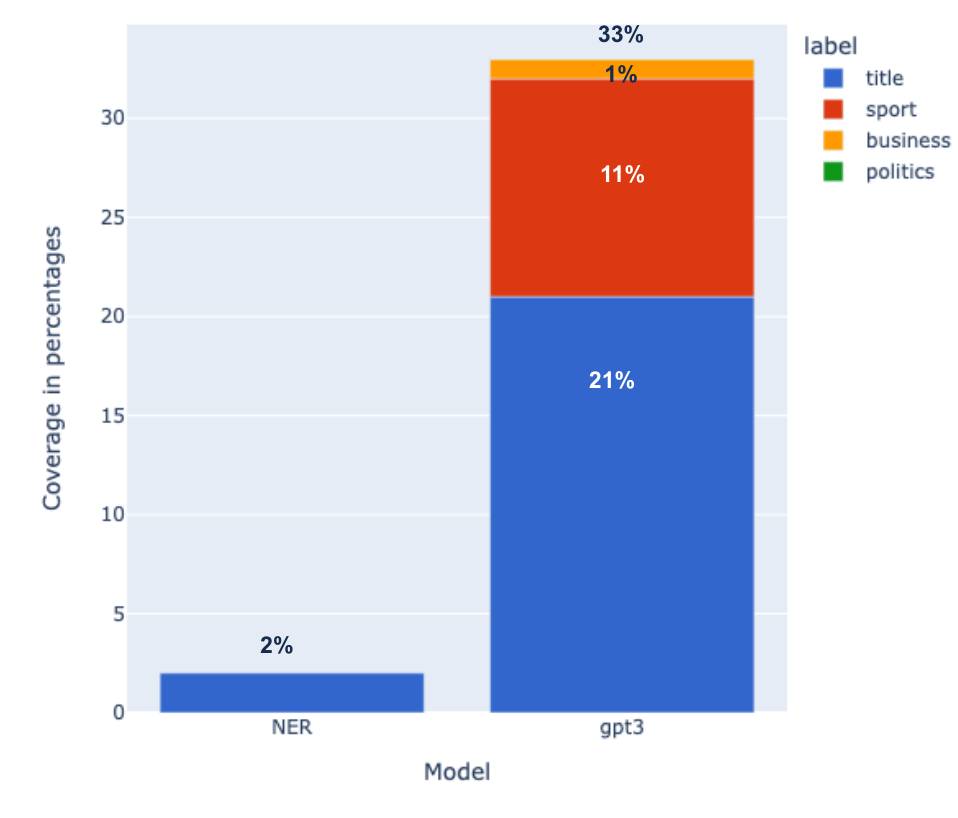
Figure 1b. Classifying location in news in sports placements based on titles using NER vs. ChatGPT. Sports section coverage on 577 unique titles. The blue bars are the location entities (city/ state/ country) extracted only from the title (explicit or implicit). The red bar is the added value to the coverage contributed from the specific questions on sports. Yellow and green marks the specific added value to the coverage contributed specifically by questions about business or politics.
Performance and cost
This POC compared two versions of GPT vs. a standard NER. The major differences were the cost and duration (see Table 2). GPT 4 was far more expensive than GPT 3.5 turbo ($180 vs. $10), and was also 1.5 hours slower. On the other hand, it was more reliable and returned more valid results on the first try than GPT 3.5 (98% vs. 83%).
| Model | GPT3 (gpt-3.5-turbo-0301) | GPT4 (openai-gpt4-32k) |
| Response time per prompt | 5~20 sec | 10~30 sec |
| Price | $0.002/ 1k tokens | prompt $0.03/ 1k tokens response $0.06/ 1k tokens |
| Tokens | input: 3,776,796
output: 1,054,222 |
input: 3,776,796
output: 1,097,167 |
| Titles returned | 83% | 98% |
| Cost | $9.66 | $179.13 |
| Duration | 4:34:13 hours | 6:07:02 hours |
Table 2: Performance and cost of the POC, sending 2K titles to GPTs and to a standard Named Entity Recognition engine. Prices were taken from https://openai.com/pricing.
Are you telling the truth my friend?
ChatGPT and similar LLMs are pruned to hallucinations. Thus, we first added a basic validation for all the engines in the POC, including NER, to verify that the city, state and country do exist in the world, and that the city is indeed inside the state and the state inside the country. Is it enough? – unfortunately no.
What if the location entities exist in the world, but are not related to the article at all? To tackle this, we fetched a dataset of 9K unique titles from our local publishers’ editors and their tagging of local/ national as the ground truth. We added an extra logic on the ChatGPT output to decide whether the items are local/ national according to the relevant publishers. Then, we calculated the precision and recall. This was done for 2 flavors of inputs:
(I ) Unique titles of news items.
(II) Unique titles of news items and their 1st paragraphs.
The results of the first iteration (unique titles only) were 92.1% precision and 27.3% recall. It means that we succeed in understanding what is national, but we missed many local items. When thinking of it, the editors have more knowledge on every news article than the LLM. The editors read the full text of the article, and have a broader context, while our LLMs got only the title.
As a side note, we could use location classification instead. Meaning that we will send the publisher location alongside the prompt and ask the model whether the item is related to that particular city. We did not do it, mainly because we planned to use the item location information in other places in the system and sometimes users from neighboring regions are also interested in cities outside of their locality.
Trying again – this time with more text
We added the 1st paragraph of each article to the title (input version II), and tried again. The results in Table 3 present the LLMs precision and recall while also sending the 1st paragraph. As can be seen, the precision stayed pretty high (86.8%), and the recall improved (35%). We still consider many local items as national, but our intuition regarding a broader context was validated and it seems that the next step is to add the full text of the article. This, of course, will be done with considerations of scale and performance, since articles can vary in length, and some can be very long.
It is important to note that, in our case, precision is prioritized over recall. This means that accurately classifying the locality of items is more important to us than capturing all local items. This is mainly because we aim to promote local items in specific slots provided by local publishers. These slots require a small number of items (1-3). Therefore, as long as we can accurately identify enough items, we can ensure that at least one local item will appear in each section.

Table 3: A comparison of the LLM outputs to a ground truth. 9K titles and 1st paragraphs of news items from our local publishers were sent to LLM for extraction of location entities. An extra logic was added to the output to understand whether the item is local or national according to the relevant publisher. Then, precision and recall were measured. The precision is high (86.8%), meaning only few national items mistakenly considered local (false positives), while the recall is low (35%), meaning we miss many local items and consider them as national.
POC looks promising – let’s productize!
Taboola constantly crawls new articles. In order to classify these articles using LLM, we needed to integrate the classification flow into our existing crawler pipeline (see Fig. 2). The classification process was performed asynchronously and offline. We sent batches of article titles and their first paragraphs to ChatGPT for classification. The results were saved in Cassandra and made available during serving time.
Taboola’s models are continuously trained for real-time click-through rate (CTR) prediction. To incorporate new location information into the training process, we included it as a categorical and historical feature in the recommendation model. This allows us to determine whether the location is local or national based on the publisher’s policy. The model then personalizes the ranking of relevant candidate items for the user and relevant context, and returns a list of recommendations as the result.
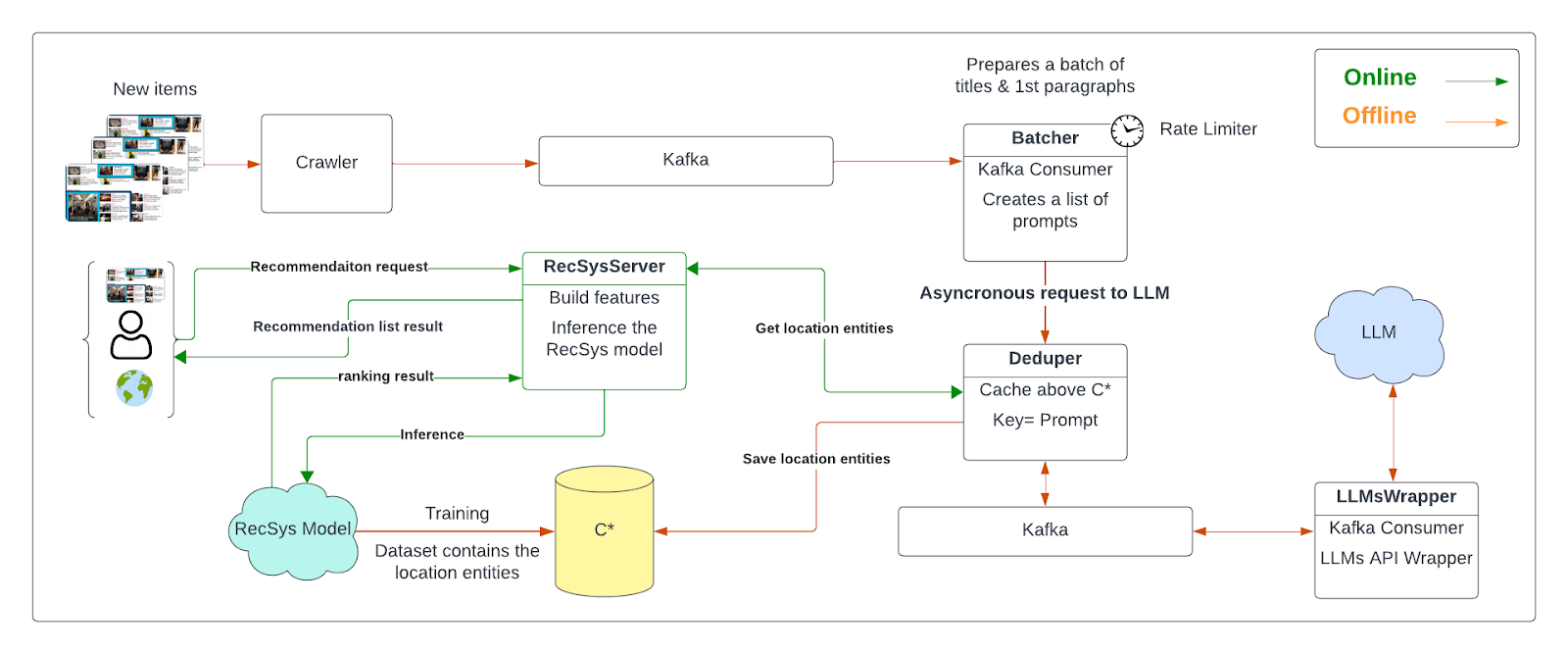
Figure 2: Recommendation system integration with LLMs. Offline flow (Orange) – sending asynchronous batches to LLM by keeping the rate limit. Sending unique prompts and saving the result in C*. Recommendation model is being trained on the LLM entities retrieved from C*. Online flow (Green) – recommendation request is being sent for a given item, user and context, retrieving the LLM result from a cache and building features, performing inference to the pretrained model and getting a list of ranked recommendations.
Did it work?
Yes! We succeeded in serving 48% more local content to our in-market users in local publishers. We have chosen a few selected local publishers, and measured the system impact by measuring the amount of local items served to the user after adding the item location information to the model. Before the treatment we served 1 local item every 15 items, the treatment on the other hand served 1 out 6 local items (see Fig 3.), more than doubling the amount of local items. In terms of user engagement, we have noticed the most significant user engagement improvement on users within the same city, with additional 16% clicks-per-user.
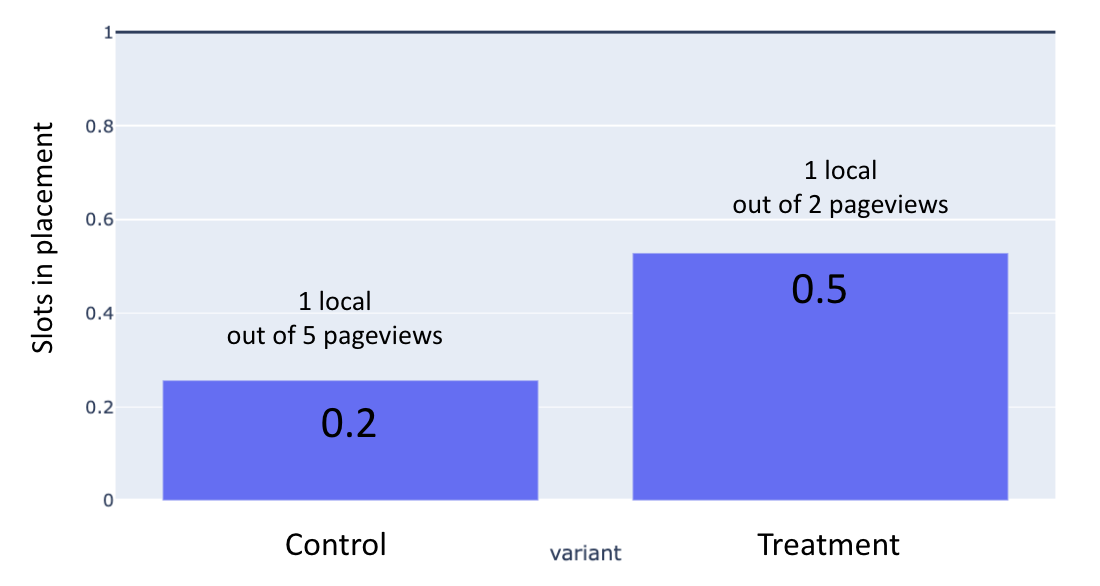
Figure 3: A/B test impact analysis. The average number of local items served measured in placements with 3 slots for in-market users. With Treatment, we served 1 local item out of 6 items (2 pageviews * 3 slots). In Control we served 1 local item out of 15 items (5 pageviews * 3 slots).
To summarize
The successful use of LLMs has increased the coverage of news items, enabling us to provide more local content on our local publishers’ websites. Having a broader context, similar to that of the editors, will result in better coverage outcomes. However, it is important to take into account the potential impact on latency and cost.
Considering a similar POC?
You might want to:
- Supply context and break your instructions to step-by-step phases.
- Specify the exact format of the expected output.
- Give a few negative and positive examples.
- Validate your responses and don’t be afraid to do a retry.
- Evaluate the results and make sure the answers are good enough for your use-case. Don’t trust ChatGPT.
Good luck!
Acknowledgements
Many thanks to the great team of algo experts @Taboola, Hai Sitton, Dorian Yitschaki, Yevgeny Tkach, Elad Gov Ari and Maoz Cohen for reviewing this blogpost.
References
- Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., … & Amodei, D. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33, 1877-1901.
- Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le QV. & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35, 24824-24837.3.