Something strange happened while I worked with Kafka.
While adding a new consumer from Kafka to one of our services, the service stopped consuming from ALL other existing consumers. As part of my job at Taboola as a team leader on a production team in the Infrastructure group, we’re supposed to remove bottlenecks, not create them.
This post will describe how I investigated the issue, explain what I discovered, and share my insights into the whole situation.
Some background
Before I get into the rest of the story, here’s some background on how we use Kafka at Taboola’s events handling pipeline and why it’s critical to our infrastructure.
Taboola’s recommendations appear on tens of thousands of web pages and mobile apps every second. As users engage with the content, multiple events are fired to signal that recommendations are rendered, opened, clicked, and so on. Each event triggers one or more Kafka messages, which translates into a lot of Kafka messages for every recommendation.
Event handling pipe
Our Kafka clusters reside in eight data centers around the globe and handle more than 140 billion messages a day. That’s more than 100TB of raw data daily, and approximately one-quarter of those messages are related to the events.
Taboola serves over half a million events per second. The servers that handle those events need to be as fast as possible (p999 < 1ms fast,) so they don’t ruin the user’s experience. To achieve such a quick response time, we split the work between two types of services, HTTPS request handling services and data enrichment services. Kafka helps pass messages between them.
Event handling servers
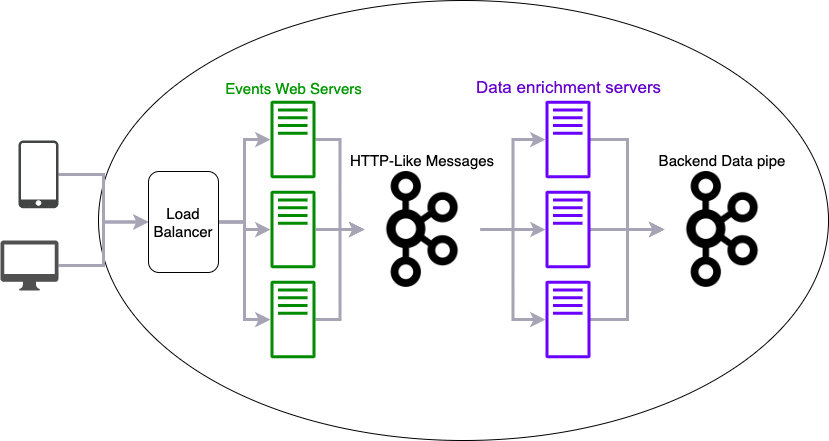
Event handling pipe
HTTPS request handling services: The events web servers handle the HTTP requests and run a light and quick process for responding to HTTP requests. They convert requests into a proto and send it to Kafka. Some events need to be processed faster or backed up for a longer time. We have several topics based on event types to keep track of this. Kafka can then tailor the retention and prioritization of processing events based on multiple factors, including event type, topic, and more.
Data enrichment services: The data enrichment servers consume the messages from Kafka and send them to another Kafka topic, which is the next part of our data pipe. (The Backend Data Pipeline in the previous diagram).
Each consumer reads messages from a specific topic, and there are multiple consumers on each server. Since the data enrichment can be CPU- and IO- intensive, we considered splitting each topic’s consumers onto dedicated servers. This would isolate problems like CPU pressure from when handling one topic affects the consumption of another. But, because we run these on physical machines, it’s hard to maintain such topology. It requires a larger number of physical servers from different types, and it is hard to scale up and down those servers.
Message processing affects servers differently
In our scenario, the partition assignment between data enrichment servers must be balanced.
Processing messages for each topic requires different resources because each topic represents a different event. And some event processing requires more CPU power, others require data to be read from a database, etc. It can create partition bottlenecks if too many similar events are consumed from a specific server and can delay processing for all the events.
Additionally, we want to have one consumer per topic partition so the message processing will be as parallelised as possible. We have more servers than we actually need, so we still have a consumer per topic if one or two servers go down. Therefore, when all servers are running, there are few idle consumers.
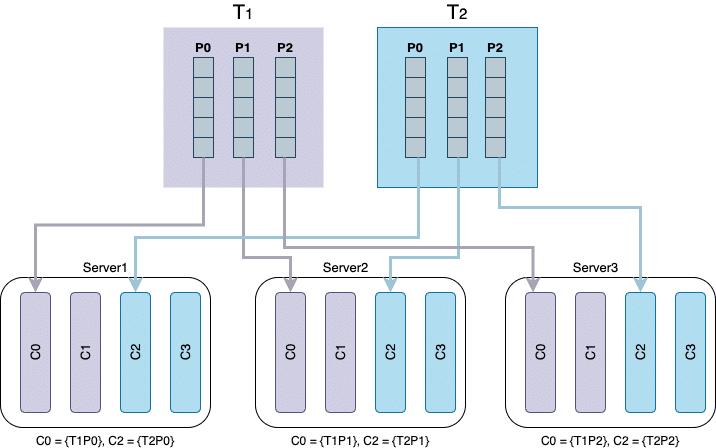
The topology of the consumers’ servers
Now back to the story of what happened when I added a new Kafka consumer to one of our services.
The strange thing that happened when we added the new consumer
We add new types of events to our infrastructure all the time. We usually just add the new topic and relevant consumers, test everything locally with different CI procedures, and then on production servers running existing consumers.
This time, something strange happened when we added a consumer for a new event type.
When we added the new consumers on one server in the server pool, other consumers on that server stopped consuming from all other topics. The new consumer had a different group ID and consumed from a new topic, so this shouldn’t have happened. We were surprised that it affected other groups and other topics.
Here’s a visual of the consumer assignment after adding the new topic (Topic 3, or T3) to Server3. You’ll see that Server 3 should have active consumers for Topics 1, 2, and 3 (the new one,) yet when we added T3, Server 3 stopped consuming T1 and T2, making them inactive.
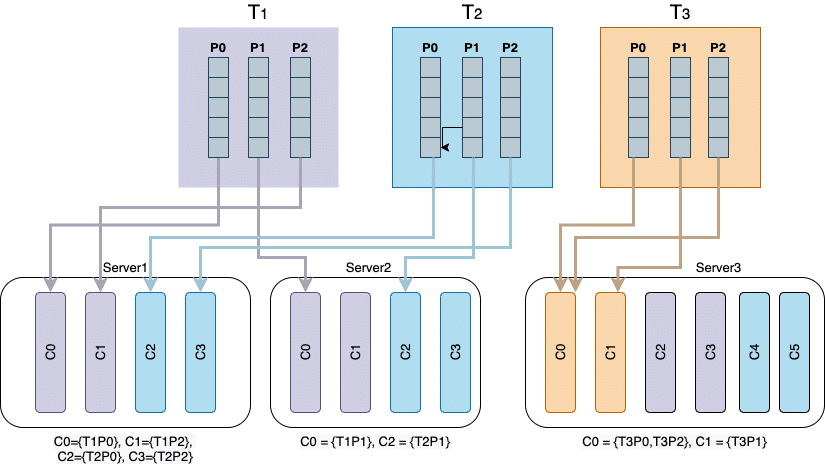
Consumer assignment diagram after adding the new topic
What was going on? We started investigating immediately to figure it out.
We needed help answering why
At first, nothing we looked at could explain why this was happening. We searched online to see if other data teams and developers had suffered this but came up empty. So, we looked at Kafka’s code as we thought it might’ve been an issue with how the group coordinator works in Kafka’s clients code.
We needed a little help from the Kafka instruction manual (Kafka: The Definitive Guide) to help us understand what was going on:
When a consumer wants to join a group, it sends a JoinGroup request to the group coordinator. The first consumer to join the group becomes the group leader. The leader receives a list of all consumers in the group from the group coordinator (this will include all consumers that sent a heartbeat recently and which are therefore considered alive) and is responsible for assigning a subset of partitions to each consumer. It uses an implementation of PartitionAssignor to decide which partitions should be handled by which consumer. – Kafka: The Definitive Guide
Log files to the rescue
By looking at the code and enabling all logs on the ConsumerCoordinator event, we finally found the source of the problem.

ConsumerCoordinator’s logs on debug level
“Aha!” I cried.
Looking at the consumer’s naming, I noticed that the names have some kind of incremental part which is not related to the groupId nor the topic.
It all made sense now.
The solution was in the partition assignment
Looking at the logic of RoundRobinAssignor#assign we discovered that before assigning consumers for each topic in the partition, it sorts the consumers by their member ID.
The same logic happens also on RangeAssignor#assign, so the issue I described can happen also if you are using RangeAssignor as your assigning policy.
Now, a member ID is composed of two parts:
- The consumer ID, which is incremented as the consumer is created, and
- a UUID, the universally unique identifier, which is assigned by the group coordinator when a new member joins a group, as per the Apache Kafka Rebalance Protocol.
By default, consumer IDs are numbered sequentially regardless of their consumer group. You can see this in ConsumerConfig#maybeOverrideClientId. (Note: consumer IDs can be overridden by a specific value in a configuration file, but we’ll get into that further down.)
Why the consumer ID mattered here
When we added the new consumers to the server, they were added to a new consumer group and given low sequential ID numbers. We expected them to be placed at the end of the ID list since they were new IDs. Instead, they were added to the front of the list, which then moved all existing IDs on that server forward.
Since the assignor sorts the consumer IDs for each group and we have more consumers than partitions, it assigns all partitions to consumers in servers running without the new consumer groups since their sequential IDs are lower. As a result, the affected servers are assigned only to new consumer groups. Partitions were assigned to the new consumers first, so the old consumers no longer had partitions to consume from the old topics.
As a reminder, here are the assignments before and after adding the new consumer again.
Before
- Server 1:
- Consumer 0 = {T1, Partition 0}
- Consumer 2 = {T2, Partition 0}
- Server 2:
- Consumer 0 = {T1, Partition 1}
- Consumer 2 = {T2, Partition 1}
- Server 3:
- Consumer 0 = {T1, Partition 2}
- Consumer 2 = {T2, Partition 2}
After
- Server 1:
- Consumer 0 = {Topic 1, Partition 0}
- Consumer 1 = {Topic 1, Partition 2}
- Consumer 2 = {Topic 2, Partition 0}
- Consumer 3 = {Topic 2, Partition 2}
- Server 2:
- Consumer 0 = {Topic 1, Partition 1}
- Consumer 2 = {Topic 2, Partition 1}
- Server 3:
- Consumer 0 = {Topic 3, Partition 0; and Topic 3, Partition 1}
- Consumer 1 = {Topic 3, Partition 2}
Remember, Server 3 stopped consuming from Topic 1 and Topic 0 and that incremental consumer IDs are per server. All consumers on the same server affect the lexicographical order regardless of their group ID or topic.
And that was ultimately the cause of the issue. The order in which consumers are created affects the assignment of partitions to consumers.
Now that we knew what to fix, it was time to edit the new consumer to avoid affecting the IDs this way.
Implementing the fix
To fix it, we needed to add the new consumers for Topic 3 on Server 3 at the end of the consumer list. This would leave the consumption of T1 and 2 balanced as before, but Server 3 can now additionally consume the new T3.
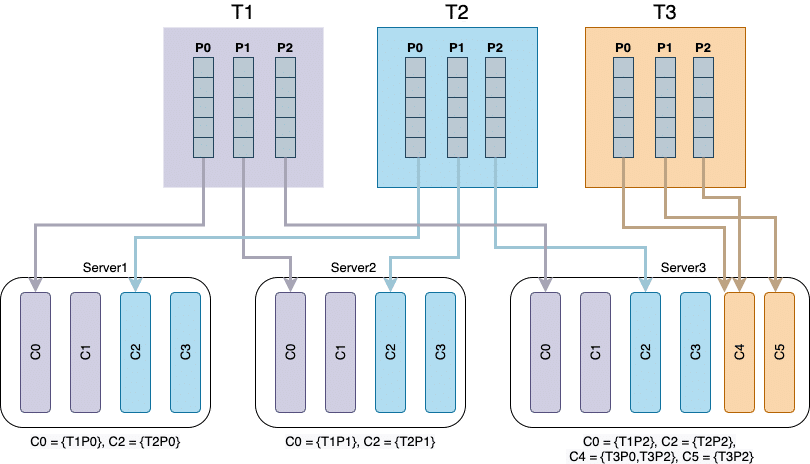
Consumer assignment diagram with the fixed T3 consumption on Server 3
We investigated several ways to implement this fix, but we knew we’d have to create short- and long- term fixes. Given how we could introduce this issue into our infrastructure at large, we wanted to be sure to have a good fix available.
Our short-term fixes
We had two options here:
- Stopping and starting all consumers simultaneously.
- Decreasing the number of idle consumers on each server.
Stopping and starting all consumers simultaneously resulted in adding the new consumers to all the servers at the same time. That rebalanced the old topics across all servers and fixed the issue. However, it’s a risky move since there may always be problems if any server doesn’t restart as expected.
As we investigated the issue, we discovered that even though we increased the server numbers over time due to increased traffic, the configuration of the number of consumers per server hadn’t changed. That meant there were a lot of idle consumers, no matter how many servers there were. We could mitigate the balancing problem by playing around with the number of idle consumers on each server.
But we still needed that long-term fix to truly solve the issue and ensure we didn’t have it again in the future.
Our long-term fixes
We came up with four different long-term solutions that would work, depending on the situation.
1. Force the order of bean creation
We discovered that we could achieve deterministic assignment of consumer IDs by controlling the order in which Kafka consumers are created for each service. At Taboola, we use Spring to create the consumers, so we can use the @order code to ensure the order of consumer ID creation.
2. Use client.id consumer configuration to control the order of consumer IDs
We can control the lexicographic order of the consumers by adding the consumer configuration client.id to Kafka consumers. It replaces the incremental consumer ID and assigns an incremental predefined identifier to all consumers on a server. We can enforce this usage by commenting the code to ensure that all developers specify an ID when adding a new consumer.
3. Implement Kafka PartitionAssignor
We can override the ID assignment method to create the sorting we need by using a custom PartitionAssignor in Kafka. By implementing the assign() method, we can control the exact way we want to assign topic partitions between the consumers’ servers.
4. Modify the ConsumerConfig code
We can modify the client ID creation code inside ConsumerConfig#maybeOverrideClientId, so that the consumer client ID sequence is per consumer group instead of using a global sequence. This solves the issue because it creates a random balance of consumers through the UUID component of the consumer ID.
Key takeaways
While consumer issues aren’t ideal, this one helped my team be better developers, and truly understand Kafka’s assignment to the further extent.
We learned that:
- There’s a relationship between consumers on the same service and the assignment of topics on a partition, regardless of the group or topic ID.
- Each server increments consumer IDs unless the order is explicitly overridden.
- All consumers on a service affect the lexicographical order of consumers on the same service .
Knowing all this will make it easier and safer for us to add new consumers to servers and topics, and deliver more information more efficiently to our Taboola customers.