Back in 2012, when neural networks regained popularity, people were excited about the possibility of training models without having to worry about feature engineering. Indeed, most of the earliest breakthroughs were in computer vision, in which raw pixels were used as input for networks.
Soon enough it turned out that if you wanted to use textual data, clickstream data, or pretty much any data with categorical features, at some point you’d have to ask yourself – how do I represent my categorical features as vectors that my network can work with?
The most popular approach is embedding layers – you add an extra layer to your network, which assigns a vector to each value of the categorical feature. During training the network learns the weights for the different layers, including those embeddings.
In this post I will show examples of when this approach will fail, introduce category2vec, an alternative method for learning embedding using a second network and will present different ways of using those embeddings in your primary network.
So, what’s wrong with embedding layers?
Embedding layers are trained to fit a specific task – the one the network was trained on. Sometimes that’s exactly what you want. But in other cases you might want your embeddings to capture some intuition about the domain of the problem, thus reducing the risk of overfitting. You can think of it as adding prior knowledge to your model, which helps it to generalize.
Moreover, if you have different tasks on similar data, you can use the embeddings from one task in order to improve your results on another. This is one of the major tricks in the Deep Learning toolbox. It’s called transfer learning, pretraining or multi-task learning, depending on the context. The underlying assumption is that many of the unobserved random variables explaining the data are shared across tasks. Since the embeddings try to isolate these variables, they can be reused.
Most importantly, learning the embeddings as part of the network increases the model’s complexity by adding many weights to the model, which means you’ll need much more labeled data in order to learn.
So it’s not that embedding layers are bad, but we can do better. Let’s see an example.
Example: Click Prediction
Taboola’s research group develops algorithms that suggest content to users, based on what they’re currently reading. We can think about it as a Click Prediction problem: given your reading history, what is the probability that you will click on each article?
To solve this problem, we train deep learning models. Naturally, we started with learning the embeddings as part of our network.
But a lot of the embeddings we got didn’t make sense.
How do you know if your embeddings make sense?
The simplest way is to take embeddings of several items and look at their neighbors. Are they similar in your domain? That can be pretty exhausting, and doesn’t give you the big picture. So, in addition you can reduce the dimensionality of your vectors using PCA or t-SNE, and color them by specific characteristic.
The advertiser of an item is a strong feature, and we want similar advertisers to have similar embeddings. But this is what our embeddings for different advertisers looked like, colored by the language of that advertiser:

Ouch. Something is clearly not right. I mean, unless we assume that our users are multilingual geniuses that read one article in Spanish and then effortlessly go and read another one in Japanese, we would probably want similar advertisers in our embedding space to have content in the same language.
This made our models harder to interpret. People were upset. Some even lost sleep.
Can we do better?

Word2Vec
If you’ve ever heard about embeddings you’ve probably heard about word2vec. This method represents words as high dimensional vectors, so that words that are semantically similar will have similar vectors. It comes in two flavors: Continuous Bag of Words (CBOW) and Skip-Gram. CBOW trains a network to predict a word from its context, while Skip-Gram does the exact opposite, predicting the context based on a specific target word.
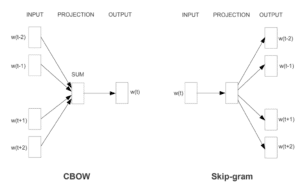
Can we use the same idea to improve our advertisers’ embedding? YES WE.. well, you get the idea.
From Word2Vec to Category2Vec
The idea is simple: we train word2vec on users’ click history. Each “sentence” is now a set of advertisers that a user clicked on, and we try to predict a specific advertiser (“word”) based on other advertisers the user liked (“context”). The only difference is that, unlike sentences, the order is not necessarily important. We can ignore this fact, or enhance the data set with permutations of each history. You can apply this method to any kinds of categorical features with high modality, e.g, countries, cities, user ids, etc.. See more details here and here.
So simple, yet so effective. Remember that messy visualization of embeddings we had earlier? This is what it looks like now:

Much better! All advertisers with the same language are clustered together.
Now that we have better embeddings, what can we do with them?
Using embeddings from different models
First, note that category2vec is just one example of a general practice: take the embeddings learned in task A and use them for task B. We could replace it with different architectures, different tasks, and in some cases, even different datasets. That’s one of the great strengths of this approach.
There are three different ways to use the new embeddings in our model:
- Use the new embeddings as features for the new network. For example, we can average the embeddings of all the advertisers the user clicked on, to represent the user history and use it to learn the user’s tastes. The focus of this post is Neural Networks but you can actually do it with any ML algorithm.
- Initialized the weights of the embedding layer in your network, with the embeddings we just learned. It’s like telling the network – this is what I know from other tasks, now adjust it for the current task.
- Multitask Learning – take two networks and train them together with parameter sharing. You can either force them to share the embeddings (hard sharing), or allow them to have slightly different weights by “punishing” the networks when their weights are too different (soft sharing). This is usually done by regularizing the distance between the weights.
You may think about it as passing knowledge from one task to another, but also as a regularization technique: the word2vec network acts as a regularizer to the other network, and forces it to learn embeddings with characteristics that we are interested in.
OK, let’s recap.
Sometimes we can get great results simply by taking some existing method, but applying it to something new. We used word2vec to create embeddings for advertisers and our results were much more meaningful than the ones obtained with embedding layers. As we say in Taboola – meaningful embeddings = meaningful life.