Time has come and we decided that we need to move forward and upgrade our data pipeline from Spark 2.2.3 to Spark 3.1.2. One may think that upgrading to the new Spark version is just a matter of a simple version number change in our dependency management. Well, it’s hardly ever the case, especially for a core dependency such as Spark, which affects many of our services in our monorepo project. A new version can include well documented API changes, bug fixes and other improvements. However it may also come with some other, not so documented, functionality changes, bugs and unexpected performance issues.
In this blog post we will share issues from our Spark upgrade journey in Taboola. A journey that started with a dependency version number change and ended after multiple code adaptations and configuration changes that we applied in order to overcome several issues. We will dive into 8 issues, explain the symptoms that we have seen in each of them, the reason behind it including related Spark tickets. And explain the workaround that we chose to apply for each of them.
See What Breaks
The first step in our journey, and probably the easiest, is changing Spark version and dealing with the failures, be it compilation errors or failing tests.
Well, we make it sound easy… As mentioned before, we have a monorepo project, and with hundreds of different production workloads, we couldn’t just upgrade Spark, test it all in a couple of weeks and go on with our lives. It was a migration that was cautiously managed over a few months, in which we had to support both old and new Spark versions side by side, but that’s for another blog post…
Anyway, there were several changes in behavior that surfaced up in our unit tests:
#1 – Proleptic Gregorian calendar VS Hybrid calendar
Spark 3 comes with a change in parsing, formatting and conversion of dates and timestamps. Previous Spark versions used the hybrid calendar while Spark 3 uses the Proleptic Gregorian calendar and Java 8 java.time packages for manipulations. This change affects multiple parts of the API, but we encountered it mostly in 2 places – when parsing date & time data that is provided by the user, and when extracting sub components like day of week and so on.
Parsing:
We have many tests that read their input data from JSON files with schema that includes timestamps fields. These tests now failed due to new strict timestamp parsing. In our case, the parsing failed since there was no match between the provided format “yyyyMMddHH” and the input, e.g: “2019-10-22 01:45:36.0185438 +00:00″.
Code:
Luckily, the symptom in this case was a descriptive exception, which had very clear cause:
Docs:
Documentation can be found in Spark migration guide in the section about the Gregorian calendar: https://spark.apache.org/docs/latest/sql-migration-guide.html
Solution:
As can be seen from the exception, we had two options to handle that. One option was to fix the supplied timestamp pattern in both test and production code. The only problem with this option was the amount of affected tests and jobs. We wanted to move fast so we decided to handle that later, gradually, after the upgrade, and use the other option instead, which is to force Spark to behave the same as in the previous versions by setting spark.sql.legacy.timeParserPolicy = LEGACY.
Sub Component Extraction:
As mentioned above, the time related changes also affect the sub-components extraction API. In our case, we had code that tried to extract the day of week from a timestamp using the date_format function along with the “u” pattern. This wasn’t supported anymore and raised an exception.
Code:
Solution:
We fixed our code to use the supported DAYOFWEEK_ISO function instead.
In Spark3 the array type created by collect_list and collect_set functions is not nullable and can not contain null values. The data type itself has changed, which means that the column type of a column with such an expression is expected to change as well.
We first experienced it in our unit tests. We have tests that create some expected schema programmatically and compare it with the results schema. One of our tests started failing after the upgrade due to schema mismatch.
While investigating it we found that the behavior has changed in Spark3 in order to comply with Hive behavior.
Code:
Spark issue:
https://issues.apache.org/jira/browse/SPARK-30008
Solution:
The solution was quick and easy. As the nullability of the column didn’t really matter to us, we just changed the expected schema accordingly and created this type with nullable=false in createStructField and containsNull=false in createArrayType.
#2 – Random using seed produces different results in Spark3
We have code that generates pseudo random numbers by using the rand function along with a given seed. The unit tests that cover this functionality expect a predefined sequence of numbers as a result. Guess what? These unit tests failed.
We discovered that the rand function result was based on XORShiftRandom.hashSeed method, which has changed in Spark3. This change caused different return values in the new version.
Spark issue:
https://issues.apache.org/jira/browse/SPARK-23643
Solution:
The solution here was also quick and easy. We fixed the tests according to the new implementation results (as it had no effect on the real functionality of the job that wanted pseudo random numbers for sampling purpose and used seed just for deterministic test results).
#3 – Quantiles calculation with approxQuantile function produces different results
We use approxQuantile function in cases where we need to calculate percentiles, we don’t want to pay the price of the exact calculation on massive data and the approximate result is good enough.
In Spark 3 a few bugs were fixed in approxQuantile. In our case it was discovered again by a few tests that failed because the return value of this function was now different from the expected value with the previous version.
Spark issue:
https://issues.apache.org/jira/browse/SPARK-22208
Solution:
We fixed the test and changed the expected result based on the new functionality.
Try It on Production
Finally, we had a green build, yay! Now it was time to test real production workloads with the upgraded Spark version. This is where things started to get interesting, and we encountered various performance issues.
#1 – Constraint propagation can be very expensive
When we started testing production workloads, we noticed that several jobs failed with OOM in the driver before any progress was made in the executors. Profiling the driver for each of them revealed that they spent most of their time on InferFiltersFromConstraints or PruneFilters. Both of these are Spark catalyst optimizations rules that rely on constraint propagation. After searching through some Spark issues we found that it’s a known issue that wasn’t fully resolved yet. There are query plans that can cause this constraint propagation calculation to be very expensive and even cause OOM in the driver due to the amount of memory used.
Profiler result:
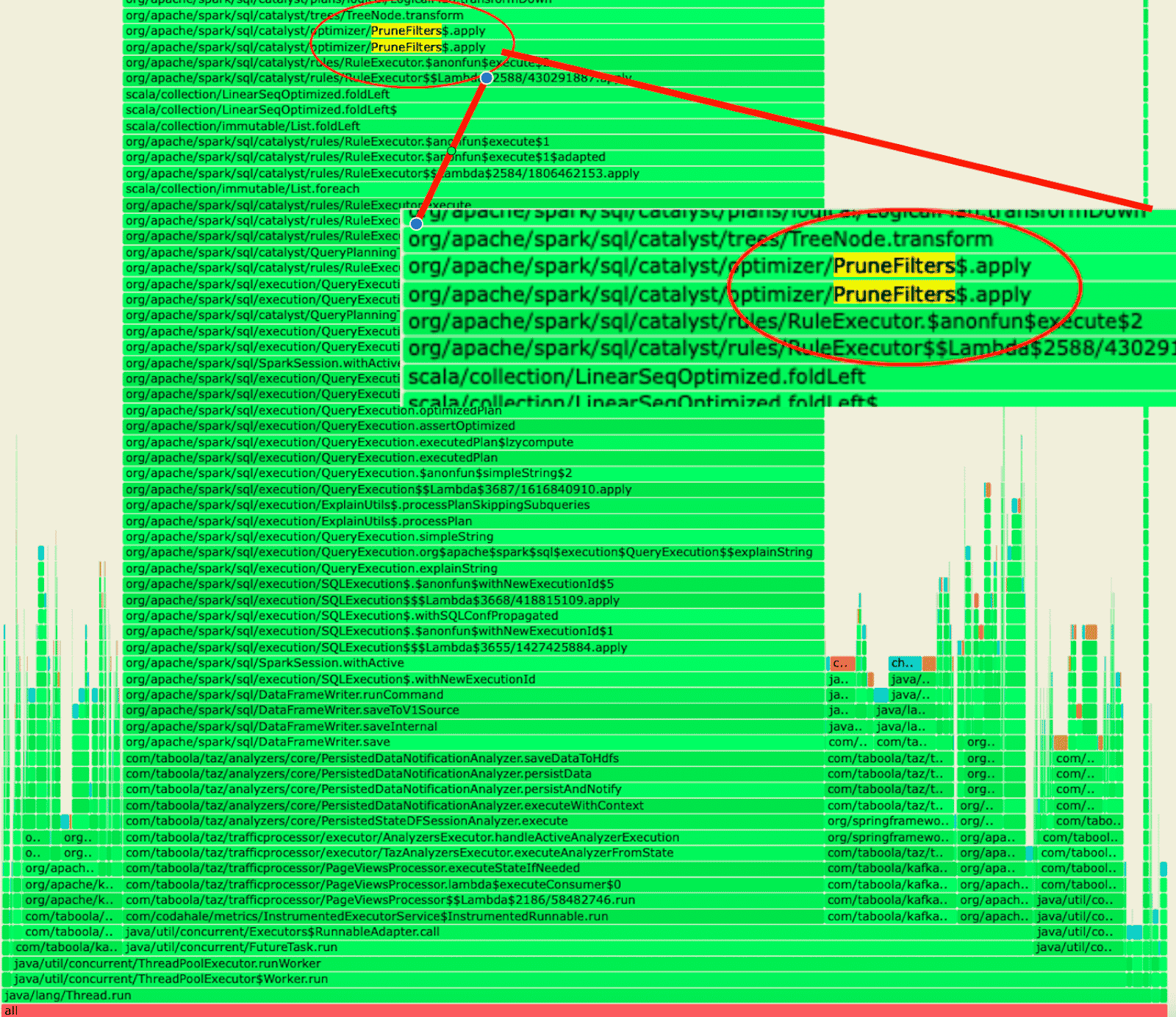
Spark issues:
https://issues.apache.org/jira/browse/SPARK-33013
https://issues.apache.org/jira/browse/SPARK-19846
Solution:
As mentioned in the Spark issues, the suggested workaround in such cases is to disable constraint propagation. The flag is:
spark.sql.constraintPropagation.enabled = false
#2 – Temp view and cache invalidation
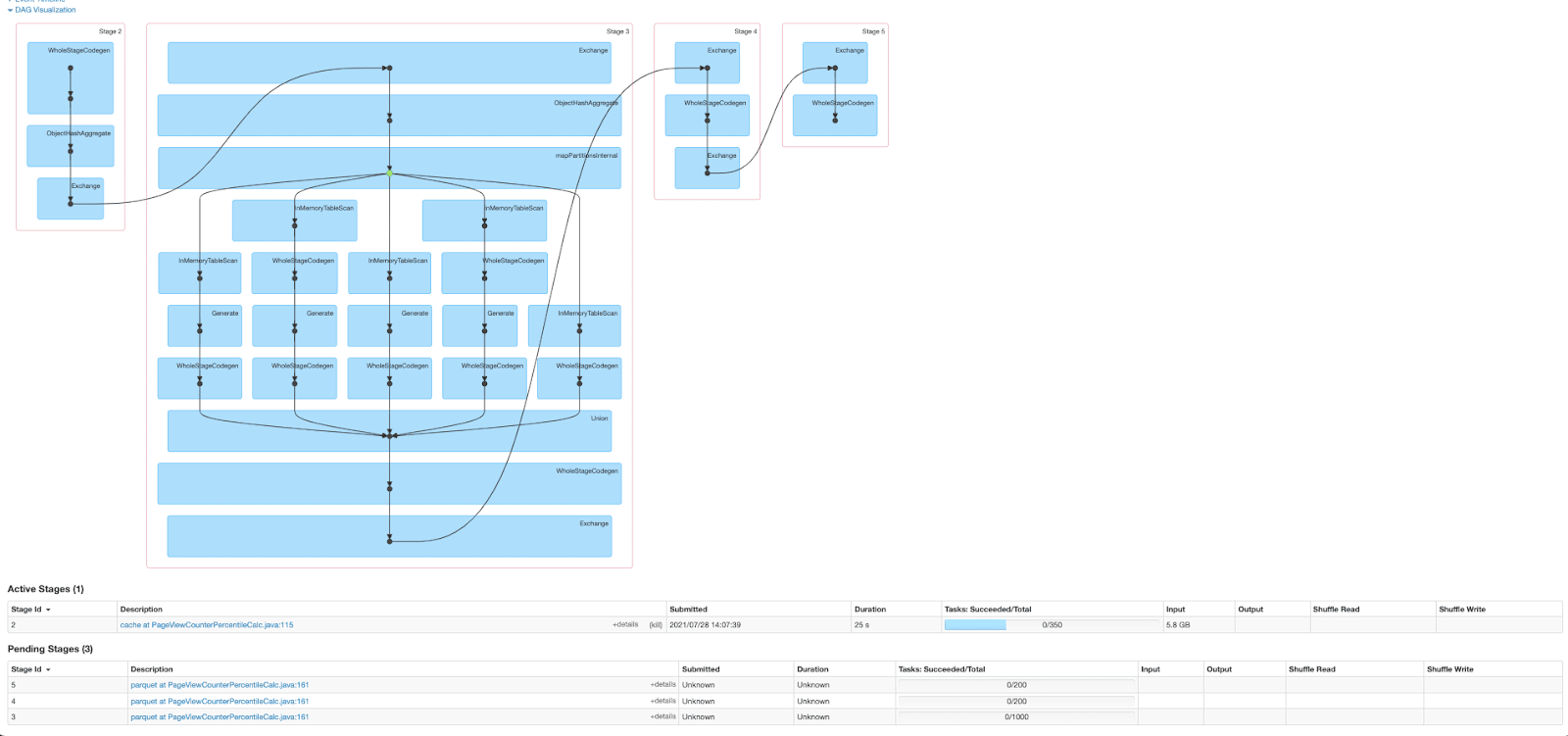
For some workloads, the total time across all tasks in one of our jobs was multiplied by 4 in Spark 3 compared to Spark 2. Spark UI revealed the interesting findings.
Spark 2:
Spark 3:
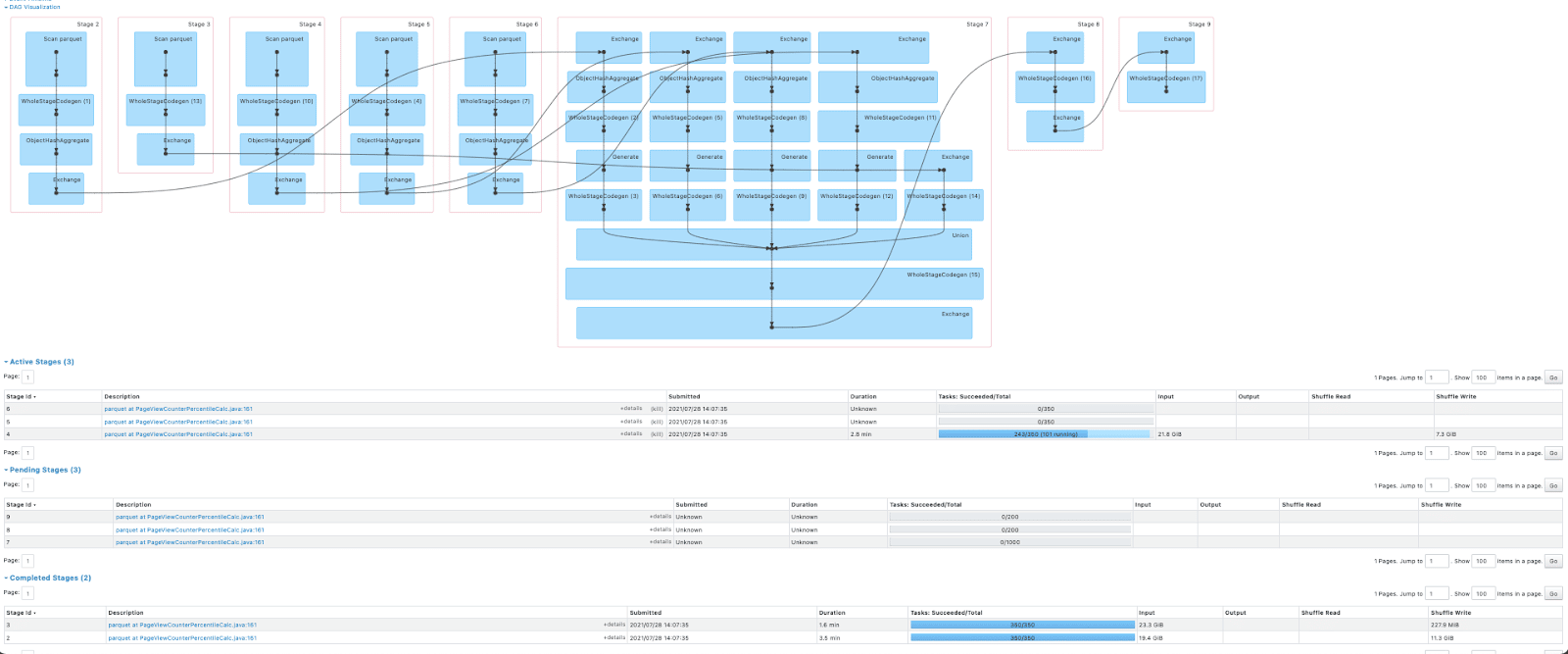
It was obvious that with the new version the job was reading the same data from HDFS several times instead of reusing the cached result. We found that this job was recreating a cached view unintentionally more than once between its calculations, which invalidated the cache with the new Spark version.
Code:
Docs:
https://spark.apache.org/docs/latest/sql-migration-guide.html
Solution:
We changed the code to create the temp view just once, to allow Spark to reuse it. Fix:
#3 – Degraded compression ratio for repeated fields
One of our main Spark jobs writes massive amounts of data into parquet files, about 2TB each hour. With Spark 3 we’ve noticed a significant increase (roughly 10%) in the amount of data written to HDFS. Such an increase in data size surely comes with a price. In our case, having retention of a month, that’s an extra 250 TB in storage (with 3 replicas), and likely slowness in downstream jobs, having to read more data.
When drilling down to parquet metadata, we have noticed that while most columns maintained a similar, or even improved, compression ratio, some columns had suffered a severe degradation. It is time to state that the schema of this output contains over a thousand columns, many of them consisting of several nesting levels. One of these columns, containing a list of INT64 values, is our biggest in our schema, and occupies roughly 25% of the entire data. Unfortunately, when we sampled a few row groups, we noticed that the compression for this column severely degraded.
It did not go unnoticed that both parquet and snappy versions were upgraded in Spark, and after a bunch of tests we’ve made with different snappy versions, we have confirmed this to be a degradation with snappy.
Spark issues:
More details can be found in stack overflow, and we have also opened a bug for snappy.
Solution:
The solution for us was to downgrade snappy back to 1.1.2.6, keeping in mind that with Spark 3 comes the prospect of using zstd compression. Which significantly improves the data compression in our data pipeline. But that’s again for another blog post…
#4 – Inflation of parquet row groups
After overcoming the snappy issue, we could finally see the light at the end of the tunnel. The data size of both Spark 2 and Spark 3 was nearly the same. Now it was time to check downstream jobs over this data, mark a nice V in our checklist and move on.
However, when reading the data by various downstream jobs, we noticed x3 times in input size for very simple queries (reading just a few simple type columns out of our huge schema). This was puzzling… How come data size has hardly changed, yet input size spiked? We’ve confirmed that the encoding and compression of the relevant columns for the query was pretty much the same.
Then we noticed something different in the metadata. The data written with Spark 2 had less row groups in each parquet part, and the sizes were more uniform.
However, with Spark 3 we observed 3-4 times the amount of row groups, and the sizes appeared as saw teeth – trending down gradually and then jumping again to high values:
The reason for that is that Spark 3 came with parquet 1.10, while Spark 2.2 (the version we’ve used), came with parquet 1.8, and the `max-padding` default changed from 0 to 8MB.This behavior is explained in Parquet row group layout anomalies, but to TLDR it – when writing data at parquet format, parquet-mr tries to estimate how much data to write to a single row group, in order not to overflow from the block size (which would result in a row group split across 2 blocks and harm data locality). Setting max-padding to 0, disables this heuristic approach. In our use case we were less concerned about it, as we don’t exploit data locality – our compute clusters are separated from our HDFS cluster. At worst, we’re paying the cost of reading two blocks per row group, but we prefer paying it then having an inflation of row groups.
Ok, but how does all that explain the growth in input size?
Let’s take a look at parquet format:
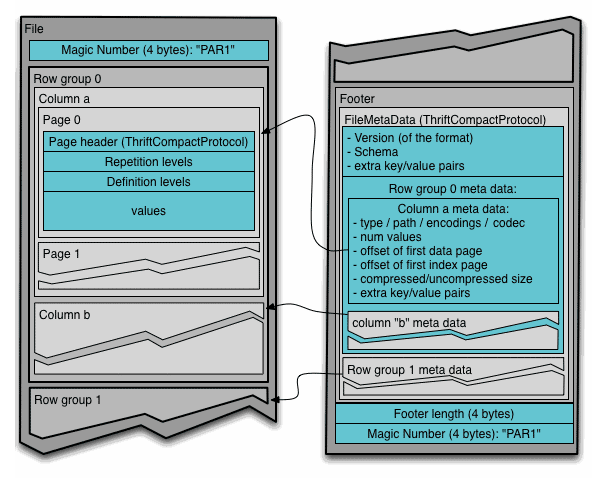
So now imagine that we’ve tripled the amount of row groups for the same amount of data, as a result – the footer size of each parquet file was tripled.
Final thoughts
Upgrading Taboola data pipeline to Spark3 was an interesting journey. We deepened our knowledge in Spark and got familiar with the changes that come with the new version. We hoped that the changes, bug fixes and functionality improvements of the new version will improve the performance of our Spark jobs, but the truth is that the overall performance of our clusters has not changed dramatically. We did see improvements in some cases, but degradation in others as well.
But hey – we can use some fresh new features now, and we are definitely going to try them.
Going to upgrade your data pipeline to Spark3? Read about the issues we encountered while we upgraded the data pipeline in Taboola.