Introduction & Overview
As the landscape of LLMs rapidly evolves, leading providers such as OpenAI, Azure GPT, Gemini, and others are emerging as pivotal players, each pushing the boundaries of what’s possible.
Businesses across various sectors are increasingly harnessing the power of LLMs to drive intelligent, data-driven solutions that enhance operational efficiency and user engagement.
This blog delves into how Taboola has developed the LLM-Gateway, a unified solution that addresses operational challenges, streamlines interactions with various LLM providers, and enhances the scalability and reliability of our internal services.
Leveraging the Power of LLMs at Taboola
At Taboola, we recognize the transformative potential of LLMs. From automating customer service interactions to powering advanced data analytics and natural language understanding, LLMs are reshaping our operational strategies and elevating the experiences we deliver. Their versatility and adaptability allow us to innovate continuously, maintaining our competitive edge in a fast-paced industry.
Key Applications of LLMs at Taboola
To enhance user experience and optimize advertisement effectiveness—ensuring ads reach the right audiences on publishers’ sites—we have integrated LLMs into several core components. These integrations include intelligent systems such as the Intelligent Abby AI Agent, GenAI Ad Maker, and Automated Advertisements Filtering for Publishers. By leveraging LLMs, we have significantly improved process efficiency and overall performance across these applications.
- Intelligent AI Agent – Abby: To maximize advertisers’ success, we developed Abby, an intelligent AI agent designed to streamline the creation and management of ad campaigns. Abby leverages LLMs to understand and respond to advertisers’ requirements, enabling effortless campaign setup and enhancing the onboarding process.
Additionally, Abby assists in managing ongoing campaigns by suggesting target audiences and geographic locations based on campaign budgets and key performance indicators (KPIs). Through interactive conversations with advertisers, Abby improves overall campaign performance by providing data-driven recommendations and optimizations. - GenAI Ad Maker: Taboola’s GenAI Ad Maker empowers advertisers with the capability to generate high-quality, customized ads that align with their brand’s unique identity and target audience. Utilizing LLMs, GenAI Ad Maker can create compelling advertisement titles and descriptions from limited input information.
For existing ad campaigns, it offers functionalities to rephrase content and rectify any issues, thereby enhancing campaign editing efficiency. This tool streamlines the ad creation process, enabling advertisers to produce effective ads quickly and consistently. - Automated Ad Compliance for Publishers: We use LLMs to automatically classify and tag ads, flagging any potential inappropriate content before it reaches publisher sites. By matching these tags and classifications with our content policy, we make sure that only suitable ads are shown to our publisher partners’ audiences. This approach not only boosts ad performance but also helps publishers avoid unwanted content, leading to a better experience for users.
Large Language Models (LLMs) are crucial for building Taboola’s key features, enabling functionalities that would be extremely challenging without them. LLMs power the Intelligent AI Agent Abby, facilitating seamless campaign setup and optimization through advanced language understanding. They drive the GenAI Ad Maker, allowing for the efficient creation and customization of high-quality ads, and automate advertisement filtering to ensure appropriate content on publisher sites. Without LLMs, developing these sophisticated and scalable features would be significantly more difficult.
The Challenges After Adopting LLMs
Integrating Large Language Models (LLMs) into our services at Taboola has unlocked unprecedented levels of efficiency and capability. However, this extensive adoption also surfaced a range of significant challenges:
- Limited trackability: One of the major issues we faced after heavily adopting LLMs is the limited trackability. With multiple services utilizing LLMs simultaneously, it became increasingly difficult to gain clear visibility into resource consumption, token usage, and model performance.
- Escalating costs: Each LLM API request consumes tokens, and as the volume of requests across our services increased, monthly expenses began to soar.What began as a manageable expense quickly snowballed into a significant financial strain.
- Difficulties with Seamless Failover for Continuous Availability:
Implementing seamless failover to ensure continuous availability has become a significant pain point. Each of our services needs to build its own retry and fallback mechanism, resulting in repetitive boilerplate code across multiple services. This not only increases development complexity and leads to inconsistency in how failover is handled. - Complex Integration and Lifecycle Management: One of the key obstacles the Taboola internal services face is the complexity of integrating with different LLM models and managing their life cycles. Each model has its own set of requirements, versioning, and updates, making it difficult to ensure compatibility and smooth operation across various services.
- Security Risks in Managing Shared API Keys: In our organization, several services access LLM models using the same API key, which makes it difficult to manage granular access control. This setup creates a vulnerability: if we need to restrict or prevent one service from using the LLM model, it’s almost impossible to do so without impacting other services that rely on the same key.
LLM-Gateway: Our Unified Solution for LLM Challenges
To address the cross-cutting challenges mentioned above, we developed the LLM-Gateway—a centralized intermediary layer between our internal services and various LLM providers and models. The LLM-Gateway offers a unified interface that simplifies interactions with multiple LLM models, while providing enterprise-grade features such as enhanced observability, easily integrated interfaces, intelligent traffic load balancing, customizable failover strategies, a configurable caching mechanism, and robust security protocols.
Design Decisions Behind the LLM-Gateway
Before diving into the architecture of the LLM-Gateway, it is crucial to understand the two core concepts behind the scenes: Virtual Models and a Unified Request & Response Data Schema.
Deep Dive into Virtual Models
At the heart of the LLM-Gateway lies the concept of Virtual Models. A Virtual Model abstracts the complexities of underlying LLM Vendor Models, presenting a unified interface to client applications. This abstraction allows clients to interact with LLMs without needing to manage details such as regional deployments or specific model parameters.
Virtual Model Request Routing
To better understand the integration between LLM Vendor Models, the following diagram illustrates how each client service uses a Virtual Model to connect with the actual LLM Vendor Models.
Between the Virtual Models and LLM Vendor Models, there is an additional layer called the Service Policy. This layer allows the Virtual Model to configure how it utilizes the associated LLM Vendor Model when serving a request.
The Request Routing Flow:
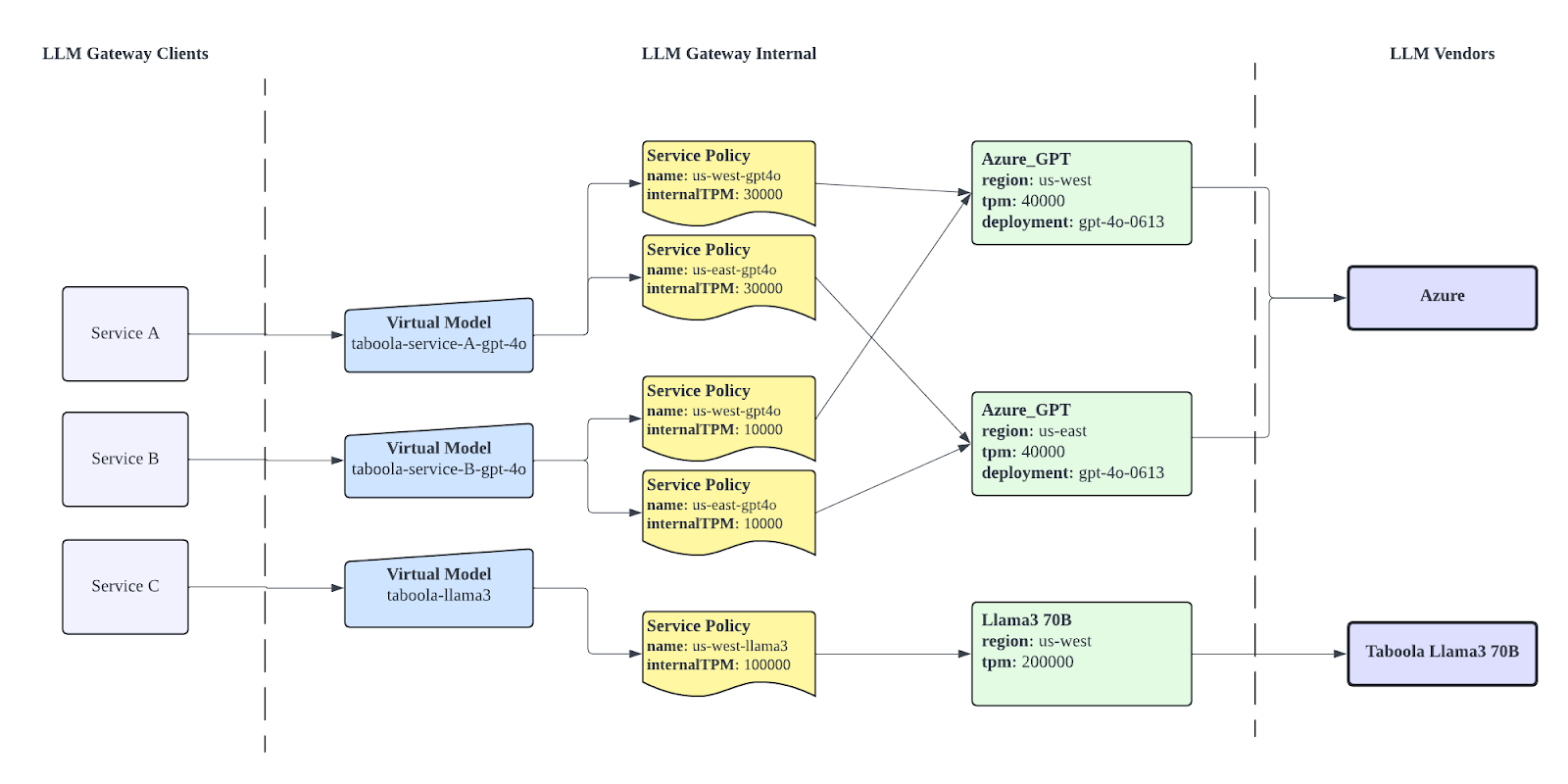
- LLM-Gateway clients submit request with Virtual Model:
The client service sends a request to the LLM-Gateway, specifying the desired Virtual Model identifier. - LLM-Gateway server validates Service Policy:
The LLM-Gateway retrieves the associated Service Policy, which includes rules such as TPM limits and model preferences for an LLM Vendor Model, and performs pre-processing operations before forwarding the request to the LLM Vendor Model.
- LLM-Gateway server forwards requests to LLM Vendor Model:
Once the pre-processing operations are finished, LLM-Gateway selects the associated LLM Vendor Model and forwards the request accordingly.
The Request and Response Data Schema
To maximize the effectiveness of Virtual Models, we standardized the request and response formats into a unified data model. This approach simplifies client interactions with multiple LLM vendor models by abstracting the complexities of model management and routing.
A pivotal design decision was to align our API structure closely with the widely-adopted OpenAI ChatCompletions API. This alignment leverages the extensive ecosystem and familiarity that many developers have with OpenAI’s interface, simplifying integration across our services.
While adhering to the OpenAI framework, we have also introduced support for extra parameters to integrate with our in-house Llama3 model. This slight extension maintains compatibility with internal models while preserving the simplicity and familiarity of the OpenAI API.
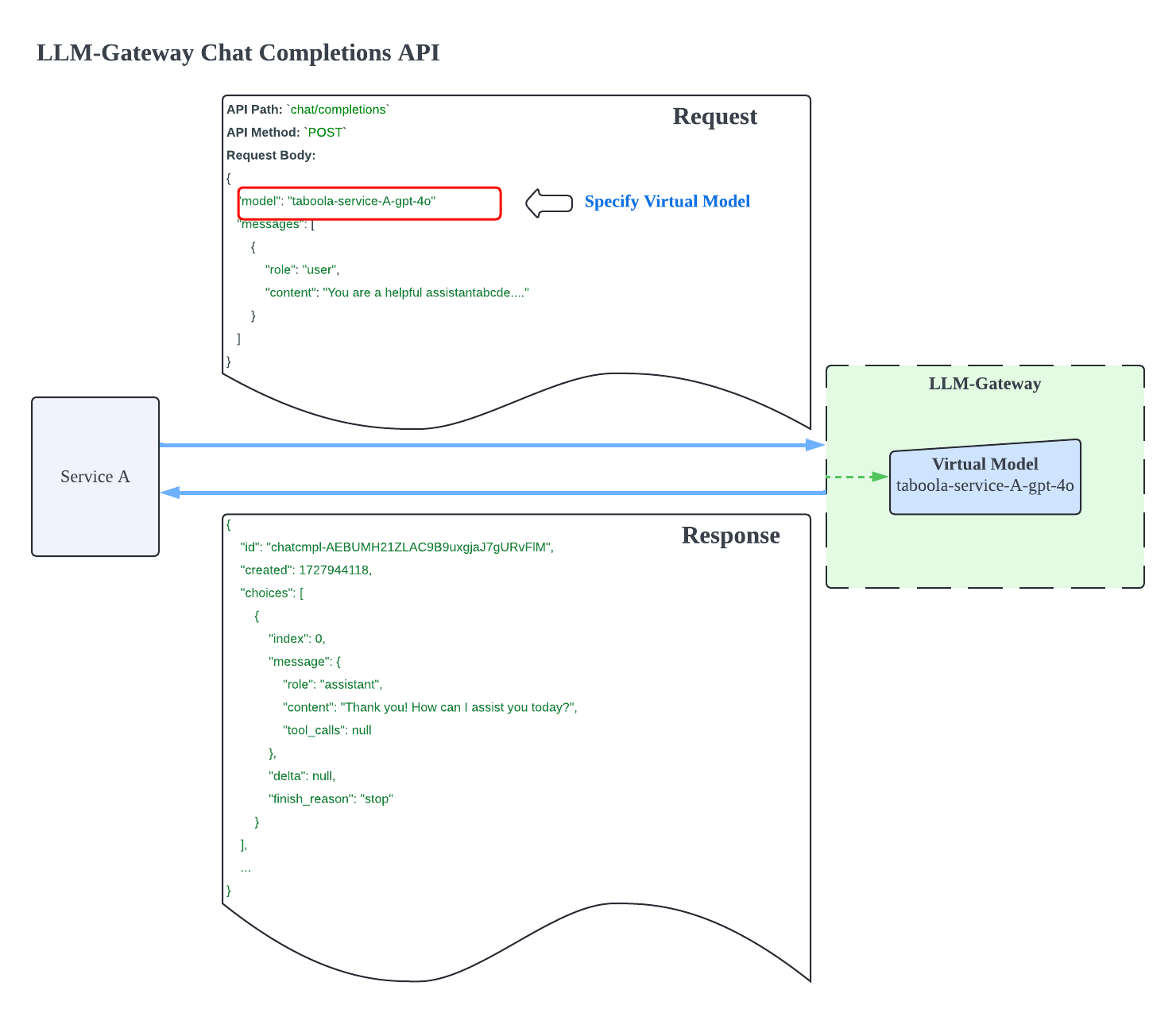
In the demonstration above, clients familiar with the OpenAI ChatCompletions API can easily switch to the LLM-Gateway. Additionally, the standardized data formats enable efficient caching mechanisms, improving performance by reusing responses across services.
This approach not only streamlines integration but also boosts development productivity by reducing the overhead of managing diverse model interactions.
Exploring the Internal Mechanism of the LLM-Gateway
Building on top of the Virtual Model and the Unified Request and Response Schema, we developed several features to address the practical challenges mentioned earlier.
This section delves into the inner workings of the LLM-Gateway, highlighting the mechanisms and processes that power its core functionalities. From intelligent load balancing and dynamic routing to robust fallback strategies, we’ll explore how these internal systems work together to deliver high performance, reliability, and efficiency.
LLM-Gateway – Core Features
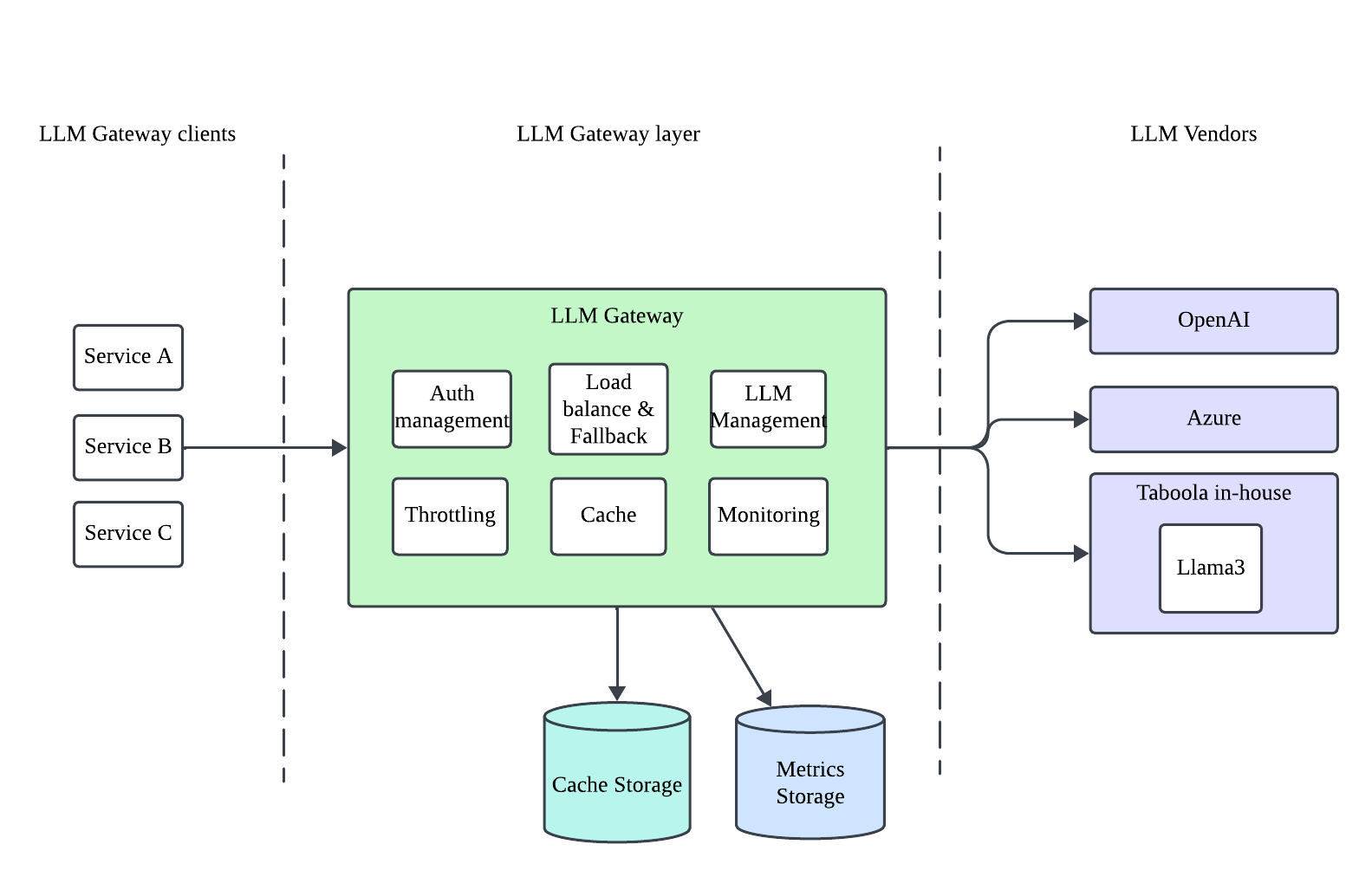
The diagram above illustrates the layered architecture of the LLM-Gateway. It depicts the key components across different layers, including LLM-Gateway clients, the LLM-Gateway internal infrastructure, and various LLM Vendors.
Next, we will explore the core features that address client challenges and make the LLM-Gateway a powerful solution:
Smart Load Balancing
The Smart Load Balancing feature was developed to mitigate Difficulties on Seamless Failover for Continuous Availability issue, it intelligently routes requests based on predefined Service Policies associated with each Virtual Model.
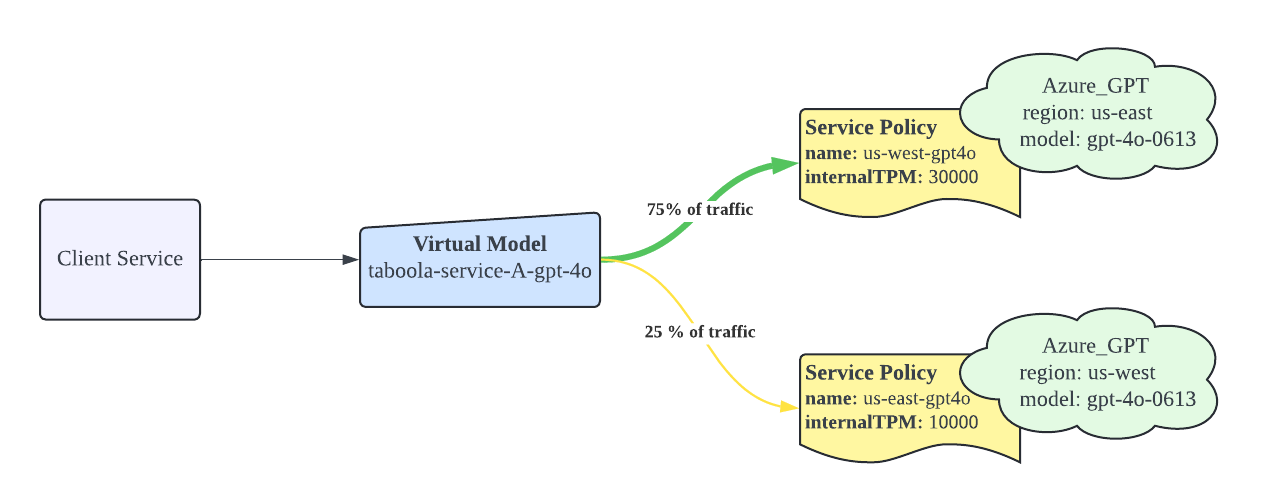
In the diagram, a Virtual Model like taboola-service-A-gpt-4o can distribute traffic between multiple LLM Vendor Models based on TPM configurations. Here’s how it works:
For the virtual model taboola-service-A-gpt-4o, with a total TPM limit of 40K (30K + 10K), the traffic is distributed as follows:
- us-west-gpt-4o: Handles 75% of traffic, based on 30K TPM limit settings. (75% = 30K/40K)
- us-east-gpt-4o: Handles 25% of traffic , based on 30K TPM limit settings. (25% = 10K/40K)
Customizable Fallback Routing
Another feature for dealing with Difficulties in Seamless Failover for Continuous Availability issue is Customizable Fallback Routing. This feature allows clients to specify fallback Virtual Models in the request parameters. If the primary model fails or exceeds its limits, the gateway automatically reroutes requests to the designated fallback model, ensuring uninterrupted service.
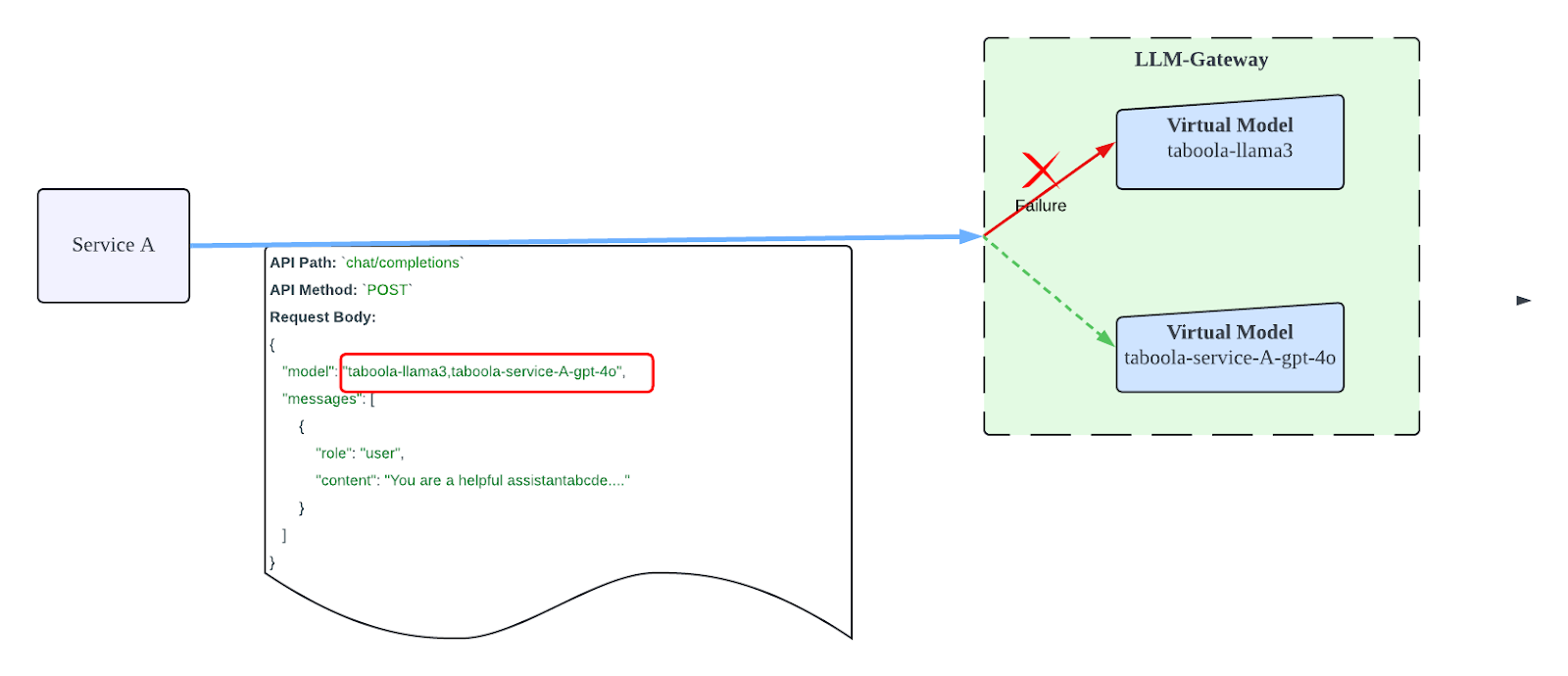
In the above graph, ServiceA sends the ChatCompletions API request with the fallback models, and LLM-Gateway does the error fallback internally when the primary model `taboola-llama3` process fails.
Configurable Caching System
To address the Substantial Costs problem, we provide an Configurable Caching System that allows clients to use an HTTP request header to manage whether to retrieve cached results or request fresh data. This flexibility ensures that up-to-date responses are available when needed, while caching reduces unnecessary costs.
By offering this configurable caching option, the LLM-Gateway enhances efficiency and provides clients with a flexible way to manage and optimize their LLM-related expenses.
Unified Model Management
To overcome Model Integration and Lifecycle Management pain points, the Unified Model Management leverages Virtual Models to simplify the management of model lifecycles. As models evolve or new versions are introduced, LLM-Gateway clients can easily switch to their desired LLM vendor models by updating the configuration of their Virtual Models—no changes to client code are necessary.
This unified approach significantly reduces the complexity and overhead associated with managing model lifecycles and integrations, benefiting both our organization and our clients.
Client Application Authorization
With the introduction of Client Application Authorization, the LLM-Gateway now effectively addresses both Trackability Limitations and Security Risks with Shared API Keys.
This feature centralizes access control, ensuring that each client application is assigned distinct authorization credentials. It strengthens security by preventing unauthorized access and reducing the risk of data exposure.
Additionally, it offers comprehensive visibility into how each client application interacts with LLM resources during the entire request lifecycle. With real-time insights into resource usage, token consumption, and the performance of various LLM models, this feature empowers us to monitor and optimize operations effectively.
Summary
The LLM-Gateway serves as a centralized intermediary between Taboola’s internal services and various LLM providers. It simplifies model management through Virtual Models, allowing seamless updates and lifecycle management without altering client code. Additionally, the gateway enhances security and visibility by centralizing access control and monitoring resource usage, providing clients with real-time insights and control over LLM operations. These solutions collectively create a streamlined, scalable, and secure environment for leveraging LLM technology.
Real-World Impact of the LLM-Gateway
Since its launch, the LLM-Gateway has revolutionized how our client applications interact with LLM models, addressing critical difficulties such as cost efficiency, seamless failover, and intelligent load balancing.
In this section, we delve into the real-world impact of the LLM-Gateway, supported by key monitoring metrics and insights from our applications.
System Metrics and Monitoring
One of the most significant advantages post-launch has been the ability to collect comprehensive monitoring metrics—insights that were previously unattainable when client services interacted directly with LLM vendors. These metrics provide invaluable visibility into system performance, resource usage, and operational efficiency.
Requests Metrics
Client request count:
This metric is essential for assessing usage patterns, identifying peak usage times, and ensuring that the gateway can handle the load effectively.

Client request duration
Monitoring request durations helps in identifying performance bottlenecks, optimizing processing times, and ensuring a seamless user experience across all services.


Client requests traffic across different LLM Model providers
This information is crucial for load balancing, optimizing resource allocation, and negotiating with LLM vendors based on usage patterns.

Caching Metrics
Caching hit rate per client application
This metric is vital for evaluating the efficiency of the caching system, identifying opportunities for cache optimization, and minimizing redundant LLM API calls to control costs.
Token Metrics
Token usage per client application
By analyzing this metric, teams can identify high-usage applications, implement token-efficient practices, and ensure that usage remains within budgetary constraints.

Lesson Learned
Caching vs Cost
Since the launch of the LLM-Gateway, one of the most impactful strategies has been the implementation of a robust caching mechanism. Given that each LLM API request incurs token-based costs, our caching strategy has been instrumental in reducing redundant calls and optimizing overall performance.
- Cost Savings: One of our client applications experienced a dramatic reduction in monthly costs, saving approximately 75% of total expenses. This significant saving was achieved by maintaining a consistent cache hit rate between 60-80% across various applications.
- Performance Improvement: By serving responses from the cache instead of making repeated LLM API calls, we have not only reduced costs but also enhanced response times and overall system efficiency.
These observations highlight the critical role caching plays in mitigating the high costs associated with LLM usage, making it a cornerstone of our approach to optimizing performance and maintaining cost-effective operations.
Request fallback
The Request Fallback mechanism has been another standout feature of the LLM-Gateway. Integrated seamlessly into the standard API request body, this feature has been widely adopted by our clients due to its simplicity and effectiveness.
- Increased Availability: Clients experience higher request availability without implementing complex retry logic.
- Reduced Complexity: The ease of integrating fallback directly into the request body has simplified client implementations, reducing development overhead and improving reliability.
Conclusion
The launch of the LLM-Gateway has been a pivotal advancement in optimizing how our clients and organization interact with Large Language Models (LLMs). By addressing difficulties such as cost management, high availability, security, and comprehensive monitoring, we have developed a solution that significantly enhances performance, reliability, and flexibility in LLM deployments.
On an organizational level, the LLM-Gateway has provided critical visibility into LLM request usage, enabling better resource management, performance analysis, and data-driven decision-making. By centralizing monitoring and tracking, the gateway allows us to optimize usage and control costs more effectively.
In our next article, we will explore advanced technologies supported by the LLM-Gateway, such as BulkChatCompletions—a bulk version of the ChatCompletions API—and other enhanced caching features. These technologies further maximize the LLM-Gateway’s performance, empowering businesses to harness the full potential of LLMs while maintaining efficiency and cost-effectiveness at scale.