When you set out to build the world’s largest content recommendation platform that performs to high service level agreements, you need a lot of computing power, responsiveness, and reliability. That’s why Taboola uses nine data centers worldwide, each with hundreds of servers. Users send and receive data from the closest data center to ensure the fastest and most efficient performance of the system.
Behind the scenes, however, the Taboola system needs to access data across all the data centers to find, analyze, and serve up the right data at the right time. To coordinate all the traffic, data, and information, we use a single data center as an aggregation point for all the rest.
This technology helps Taboola digest, transform, and aggregate the data at scale, so it’s valuable to our customers and users.
In this article, we’ll explain what conversions are, how we handle billions of daily events at scale, and how it all presents meaningful data to customers.
Ready to take a look under the hood of Taboola? Let’s go.
Quick Definitions
Before we go any further, here are a few definitions that’ll help you understand the data path in Taboola.
- Action: The desired action a user takes on an advertiser’s website, such as a product purchase, page view, or email sign-up. Each action is reported to the Taboola server by a corresponding event using the Taboola Pixel.
- Taboola Pixel: A Taboola script embedded in an advertiser’s website that gathers specific data about user behavior on the site. The script sends events to the server for consumption and analysis. You can learn more about the Taboola Pixel here.
- Rules: A set of conditions defined for a conversion for a specific advertiser. E.g., if a page contains the phrase “Thank you” or “Sign-up successful.”
- Action Conversion: When a user takes a desired action on a landing page they reach through a Taboola recommendation. The two main types of conversions defined by rules in Taboola are event-based conversions and URL-based conversions.
- Event-based conversion: A conversion based on an event sent from the advertiser’s website through the Taboola Pixel. E.g, Add a product to the shopping cart, install an application, or sign up for the newsletter.
- URL-based conversion: A conversion based on rules created for a specific URL. E.g., event signups from a specific landing page.
Now, back to the conversion data path in Taboola.
The Data Path in Taboola
The data path architecture in Taboola is divided into two main parts:
- In each data center, where the data is consumed and processed internally.
- In a central processing data center, where the data is mirrored from all data centers and written to a Vertica database for further analysis.
Part 1: Data inside the Data Center
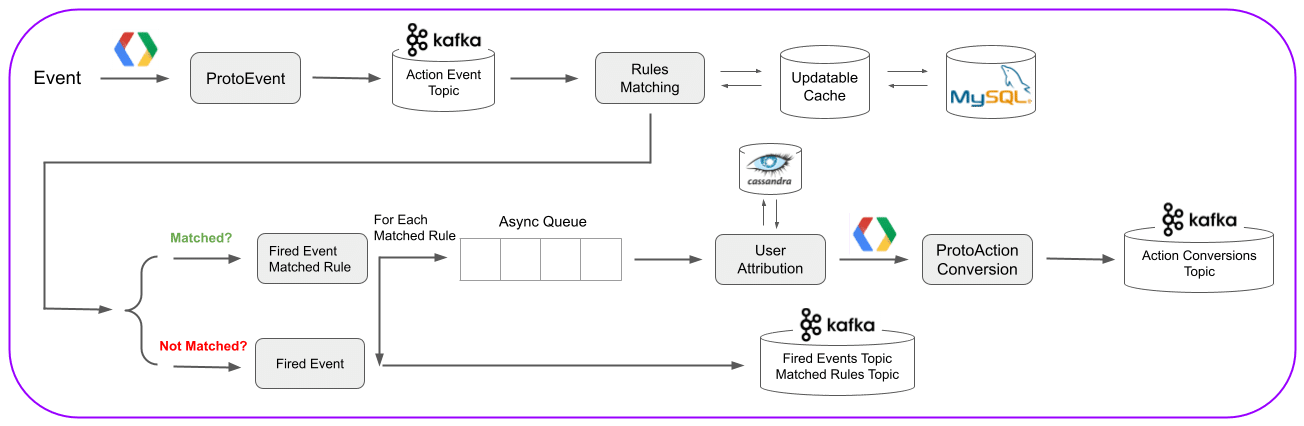
Data Path Inside Each Data Center
Step 1: Creating an Event
When the Taboola Pixel is triggered, it sends an event to our back-end servers. The event is processed and transformed into a ProtoEvent using Google’s Protobuf format for easy and lightweight serializing and deserializing.
The ProtoEvent is sent to the Action Event Topic and is consumed by an Apache Kafka consumer, where it’s prepared for rules matching.
Step 2: Rules Matching
Each event contains contextual account information, so this step checks for a relationship between the business rules that the advertiser defined in the Taboola Ads platform and the current event. It looks to match the event data with the advertiser’s defined rules, which are fetched from an updatable cache reading from a corresponding MySQL database for reduced time and increased performance.
An event can match a single rule, multiple rules, or no rules. They will still be sent to Kafka.
Once passed the rules matching phase, the event, and any matching rules, are sent to the Fired Events & Matched Rules Topics in Kafka to be consumed in a later stage. Matched events are asynchronously queued to move to the next stage of the process.
Step 3: User Attribution
Once matched, the event must be analyzed to determine if it’s attributed to a user that reached the current website through one of Taboola’s publisher partners. Our platform tries to match the user’s event to their clicks and relevant visible events on publishers’ websites.
It’s checked to see if it’s from a direct ad click on a publisher’s page or if the user was presented with an ad on the publisher’s site and they reached the advertiser’s site some other way. As we deal with a very large scale of events, in order to have high performance and availability at scale we store the data above in an Apache Cassandra cluster.
Once the event is attributed, it’s reported, counted, and stored as an action conversion.
Step 4: Topic Storage in Kafka
The final step for the data in the single data center is transformation and storage in Kafka. The conversion is transformed into a ProtoActionConversion using Protobuf protocol and sent to the relevant topic in Kafka for the aggregation part.
Once the conversion data passes through the individual data center, it’s ready for aggregation.
Part Two: Data is Sent to the Aggregation Data Center
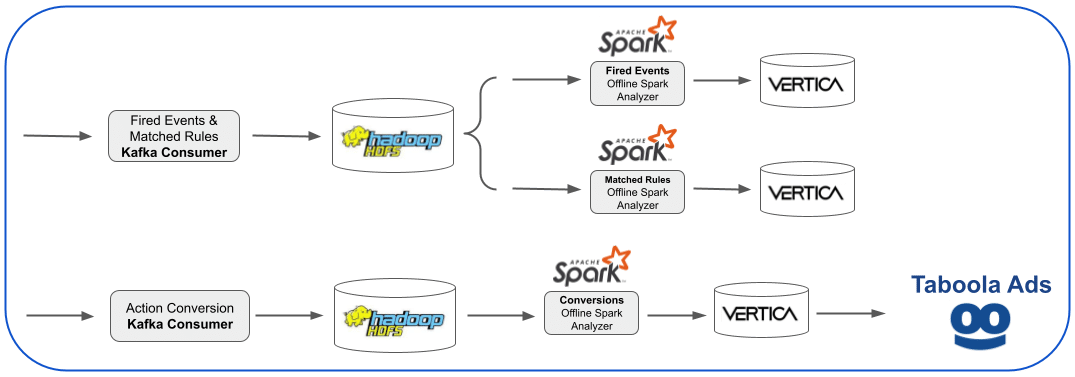
Aggregation Data Center Data Path
Conversion data is mirrored from the individual data centers into the aggregation data center before being analyzed and consumed by the Taboola platform.
- The final Kafka consumer reads and writes the data to the aggregation Hadoop Data File System (HDFS.)
- Offline Apache Spark jobs read the data on HDFS for further filtering and aggregation into multiple tables in Vertica.
- The data is sent to Taboola, where it’s used in various visualizations and reporting for advertisers, such as the Campaigns Report with Conversions Statistics.
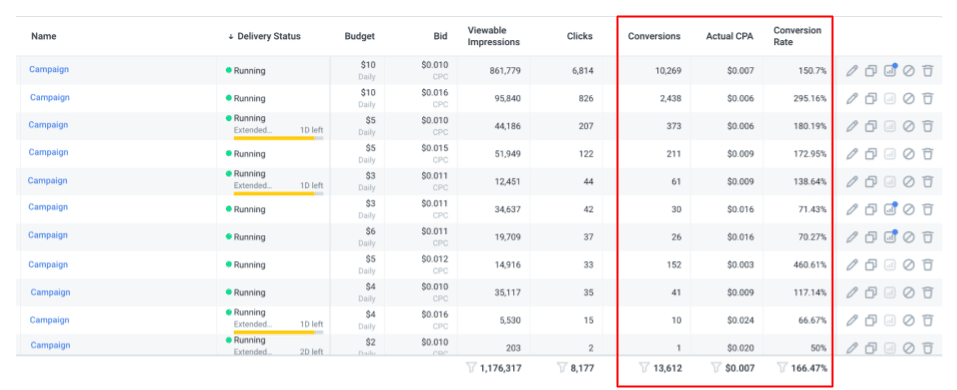
And there you have it! Now you know how conversion data moves through our servers, data centers, and systems to provide Taboola customers relevant conversion information.
Do you have any questions about how we handle this? Let us know, and we’ll try to answer them.