One pleasant morning I got to work, thinking this day couldn’t get any better. But as Murphy would have it, there was my boss walking frantically toward me.
It turned out that almost over night one of the main data pipeline systems had become a major bottleneck for the company, and a solution was needed, Fast!
Usually in a startup, let alone a company moving as fast as Taboola, these things can occur on a weekly basis.
I needed to find some quick wins to relieve some of the bottlenecks inside the system.
Luckily Re2 was there to the rescue – in this post I will share how to find the bottlenecks using Gprof2dot beautiful image rendering, and of course, what Re2 is and how to use it.
* Note that this article addresses a pain I had in a Python framework, but because there are Re2 implementations to all major languages you should still find value reading this article.
The strategy to relieve bottlenecks is pretty straightforward
Step one: Recognize were it hurts the most
Step two: Reduce the pain
Step three: Iterate back to step one until you get the desired result
Sounds simple enough, right? Well it is, in theory.
Usually the implementation is where it gets you.
Step one: Recognize where it hurts the most
Like anyone who ever saw a guy talking about A.A. meetings on TV, will say: “The first step in dealing with your problem is recognizing that it exists”, in our case that meant measurements and finding the bottlenecks.
The system in question is a pretty straightforward ETL system written in Python, so I decided to start by looking at the transform part first.
I spent a couple of hours extracting the main part of the code into a single independent process, and when it was done I started a Jupyter notebook http://jupyter.org/.
Using cProfile built-in python package and gprof2dot, I ran the following code to test it –

This is the image Gprof2dot produced:
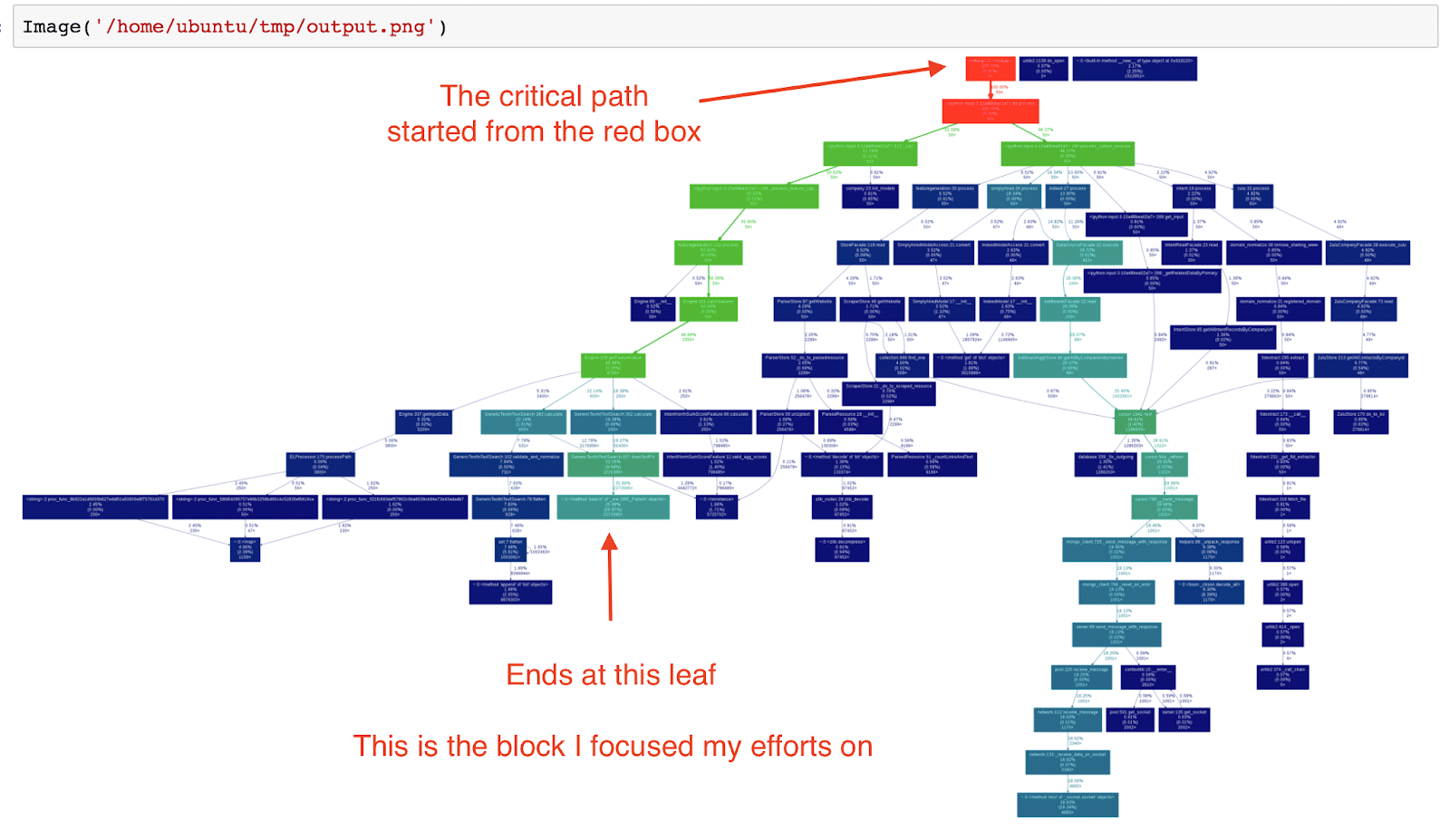
A short explanation if this is the first time you encountered the Gprof2dot library: The image that I got was a profile that measured our code, and determined, for each major block, how much time our code visited that block and how much time in total each block contributed to the overall running time.
The dark blue ones are the “cold” areas, the interesting parts in our investigation.
The path starting from the red box, and “cooling down” all the way to the leaves are the interesting paths to investigate.
Each box has the following format:

In the next image below, I looked at the leaf at the end of the path.

If you look at the upper box, you can see that it’s a method called doesTextFit in class GenericTextInTextSearch. The system spent 32.05% of it’s runtime in that code, but only 4.94% of it is in the actual code of the method, the other ~95% of the time was spent in code called from doesTextFit.
The 2,221,386 is the amount of times this code was called.
The more interesting part is that doesTextFit calls another method, where it spent ~26% of the time.
That was the method I decided to focus my attention on.
* Note that it might happen in the leaf box, that the self time – in the parenthesis – and the total time – above the self time – don’t add up.
This happens when the execution time is too short, causing the round-off errors to be large. Don’t worry about it.
“Method ‘Search of’ _sre.SRE_Pattern object“ is from Python built-in library – the Regex library re.
It turned out that the system that had a lot of moving parts, spent ~26% of the time on a single method on a single library call.
So now I set out to see if I could find a replacement for the Python built-in method.
It turns out there is. And I was completely surprised by it.
Step two: Reduce the pain
I came across these two articles:
They basically told me, I was living a lie – I always thought that Regex is the most efficient way to match a string. It turns out that it might have started like that, but somewhere along the way we sacrificed – in all the major programing languages – performance for features.
The salvation was going back to the fundamentals: State Machine Based Regex!
What’s wrong with the built in Regex engine?
TL;DR Backtracking.
When the built-in Regex tries to match a string, it follows a greedy algorithm pattern. Trying to match the full string first, and when it fails trying to match minus one characters on the full string and the leftover char separately. Then on the full string minus two characters, and on the two leftover characters separately, and so on and so forth. If there is no match, the engine is destined to fail, it simply doesn’t know that before it iterates through all the different combinations.
This process is time and space consuming.
So what’s the alternative?
Introducing Ken Thompson. you can read more about him in his wiki page, but here is the TL;DR for the list of his achievements:
- Unix
- B (programming language) – ancestor to C
- UTF-8
- Go (programming language)
- State Machine Based Regex!
The last bullet is best represented in this comparison graph:
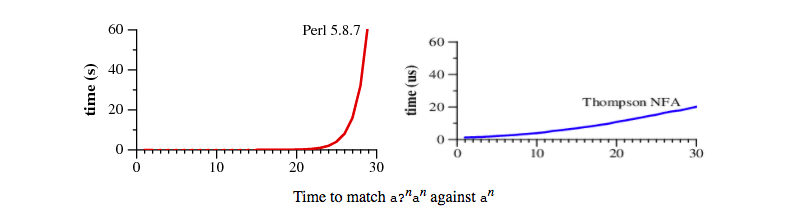
The left one is for Perl, but represents the major programing languages, the right one is the Thompson method. Make sure you notice that the left one is in seconds and the right one in microseconds(!).
How did he do that? state machine.
Think of a regular expression as a state machine built from the expression you want to match.
Each char the engine encounters, propels it to make the next decision, if by the end of its journey it reaches a “final” state. Then the engine found a match.
If not, then there is no match.
The space complexity of a solution like that, is the amount of different states the regular expression has. And the time complexity is the length of the text being checked.
With that in mind, I went out to see if I could find an implementation of the Thompson engine, and I found the good people of Google with their Re2 implementation in C++.
To integrate Google Re2 in Python, I had to use a third party wrapper py-re2 , but for Java there is Google Re2/J project or Brics, we in Taboola, use Brics in our Java code, you can read comparison of the two projects in this great blog: brics-vs-re2j.
The integration in the code is that simple:

It is important to remember that not all the functionality that exists in re, exists in re2. So what I did, and what you should do if you plan to use this solution, is to analyze all your Regex calls, and make sure that you get the expected result.
Although the graph above promised a performance boost of hundreds of percent, the performance boost I managed to get was just a ~40%-50% boost. I didn’t complain, it was not too bad for a few days work.
Step three: Iterate back to step one till you get the desired result
I never got to this part, and hopefully, if you use this engine you won’t either…
No Silver Bullet
The specific circumstances of the system i described here, is that the majority of the Regex comparisons finish without a match.
So it worked really well to have a new Regex engine that returns “no match” faster than the regular – backtracking – one. You will need to test it in your unique scenario to see how much performance improvement you will get.
Second thing to check is the Regex you use, if it needs Backtracking to complete it’s comparison it won’t work, and you will get Segfault.
But, it shouldn’t be too hard to rewrite them to a simpler syntax.
Third thing to monitor, is the state explosion problem when building deterministic automata, that can happen in some of the Re2 implementations – Brics for example but not in Google Re2. The cost is in performance.
The last thing you need to check is the return values, there might be a case that the expected outcome has changed from what you had before. For example to get a null were before you got a False.
The bottom line is that you will need to do the same evaluation process that you would have done before upgrading to a new version of a library. Things might change, so you need to be carefull.
Having said that, even if it is only a few percent improvement, the fact that it is so easy to integrate makes it a “money on the floor” scenario.
Good luck, and feel free to contact me for help and guidance.