Introduction
In machine learning, one critical challenge is ensuring that the features used during model training (offline) match those used during inference time (online serving). Discrepancies between training and serving features can lead to significant performance degradation, making it crucial to identify and address these inconsistencies as fast as possible.
At Taboola, we specialize in content discovery and native advertising, enabling users to find and engage with personalized content across the web. Our advanced machine learning powered recommendation systems serve billions of recommendations every day, helping publishers, advertisers, and brands reach their target audiences effectively.
In this blog post, I’m going to discuss the challenges of training-serving feature discrepancies in machine learning models and how they can affect model performance. I’ll explain how we tackle these discrepancies at Taboola, including the design and implementation of our solution, Sherlock. Finally, I’ll discuss some of the key discoveries made and the significant impact Sherlock has had on our recommendation systems.
Discrepancies?? No Way…
Training-serving feature discrepancies can occur for several reasons. The most common reason is the way we handle large features. Due to their significant storage requirements, these features are often not reported back as-is after serving in the online environment. Instead, before training, they are re-calculated from sampled data and various data sources. The re-calculated features may differ from the original calculations performed during serving. This may be due to data differences, changes in external data between serving and training times, or calculation logic differences.
Another cause of discrepancies can be cache misses and database queries timeouts in the online serving environment. For Taboola to be able to return recommendations to the client in a matter of hundreds of milliseconds we must wrap database queries in a very strict limit. These misses and timeouts can result in certain features having no values in serving while in the report back pipeline they will have values due to less strict timeouts.
Additionally, integration bugs can introduce further discrepancies. Poorly integrated components or erroneous data pipelines can cause mismatches between the features used during training and those available during serving.
Meet Sherlock
In order to tackle this issue, we developed Sherlock. Sherlock is a robust system designed to detect and alert on training-serving feature discrepancies in our models. Developed as part of our continuous efforts to improve the reliability and performance of our recommendation systems at Taboola, Sherlock allows us to promptly detect discrepancies and quickly address them, ensuring consistent and accurate model performance.

How Sherlock Works
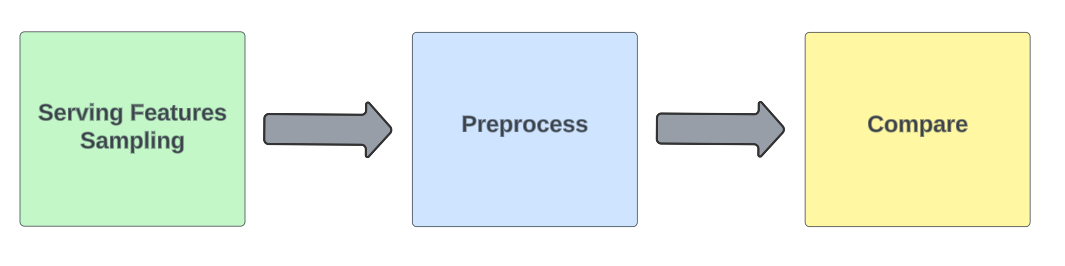
Sherlock pipeline is composed of three main parts:
- Sampling: Saving a sample of feature values that were used for the serving.
- Preprocess: Building the training feature values.
- Compare: Comparing the serving and training feature values and raising warning/alerts based on the results.
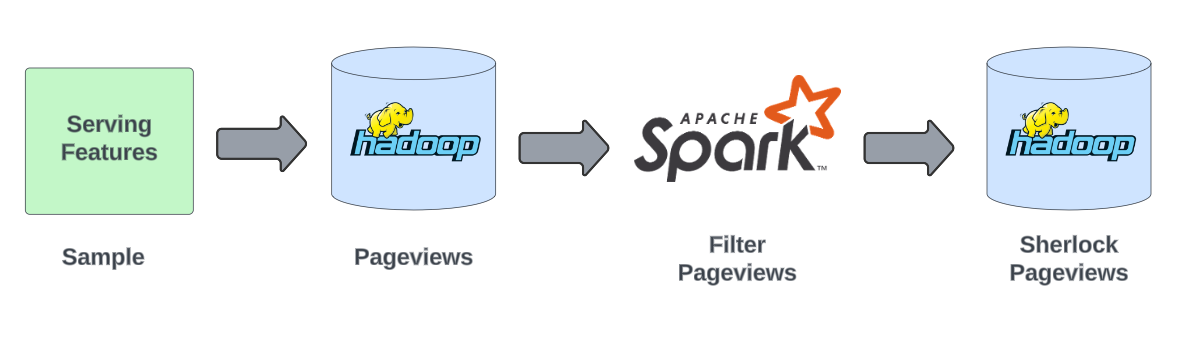
Stage 1 – Sampling
Saving all feature values from the serving environment is impractical due to the enormous volume of data it would generate. To tackle this challenge, we implemented a sampling strategy where feature values are reported for 1 in every 10,000 requests handled at Taboola. This approach significantly reduces the data volume while still providing a representative sample of the feature values used in serving.
The sampled feature values are included in Pageview objects in HDFS. A Pageview is a record that encapsulates various details about a user’s visit to a webpage, including recommendations served, user activities such as clicks, and more.
To further streamline the process, we run a Spark job that aggregates these Pageviews containing the sampled features values once an hour. This job collects all relevant Pageviews from the previous hour that have the sampled data and copies them to a dedicated location in HDFS, making them easily accessible for the next stage of Sherlock’s workflow.
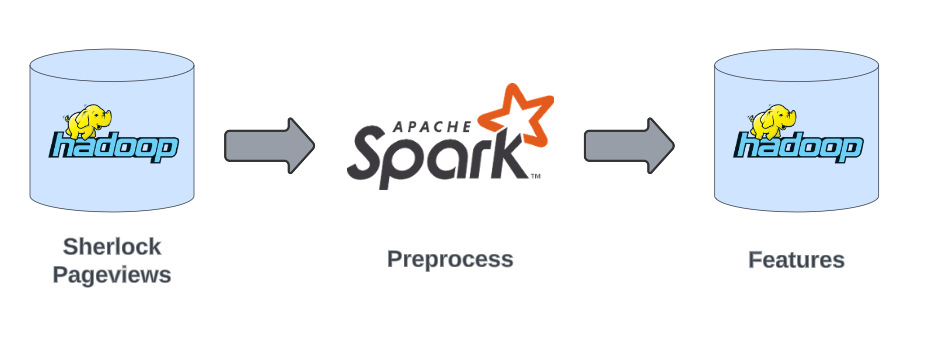
Stage 2 – Preprocess
Preprocess refers to a group of Spark jobs designed to prepare data for the model training jobs. These jobs read Pageviews data from HDFS based on a range of dates and perform a series of operations, including filtering, enrichment with external data sources, and calculations. The result is a comprehensive dataset containing all the features of the model, along with train and test folders filled with TFRecords used as inputs to the training job. All these outputs are then stored in HDFS.
For Sherlock, our primary focus is on the features dataset. To accommodate Sherlock’s requirements, we developed a special mode within our existing Preprocess jobs, characterized by the following key points:
- Reading Input Data from Sampled Pageviews: The job reads input data exclusively from the path specified in stage 1, which contains only the Pageviews containing the sampled serving features values.
- No Filtering or Sampling: Unlike our standard preprocess before training job, this special mode processes all the data without any filtering or sampling, ensuring that all the data is processed.
- Features Calculation: The job calculates all the features for training as it would in a standard preprocessing run, ensuring that the training feature values are calculated just as they are calculated in the standard production process.
- Including Serving Sampled Feature Values: In addition to the calculated features, the job includes the features from the serving sampling exactly as they were recorded. This results in a dataset where each feature is represented twice: once with the serving values and once with the Preprocess calculation (the one that should have been used while training the model).
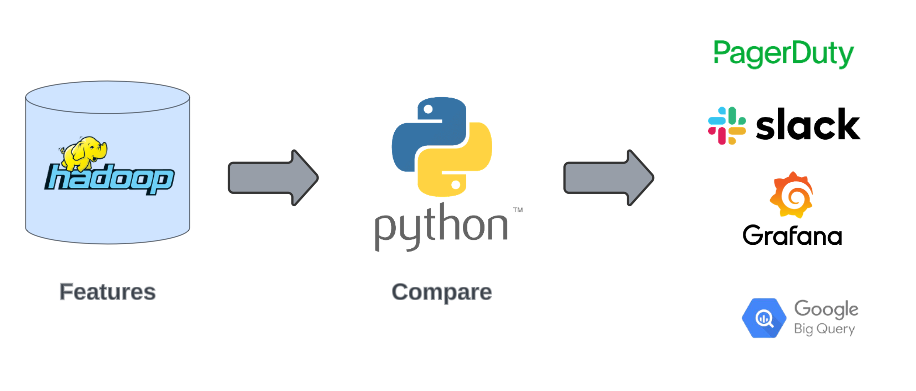
Stage 3 – Compare
The Compare stage is the core of Sherlock, where the serving and training values of the features are analyzed and discrepancies are detected. This job is implemented in Python and leverages the Pandas package, enabling the efficient and fast comparison of large amounts of data.
Since there are various types of features, such as integers, strings, lists and more, some comparisons are straightforward while others are more complex. Basic types are automatically detected from the data, whereas complex types are defined per feature in configuration files. Each feature is configured with warning and alert thresholds to identify significant discrepancies. Additional metrics, such as the percentage of Out of Vocabulary (OOV) values, are also calculated for each feature.
Once the comparison is complete, the results are uploaded to Google BigQuery and are also made visible in our easily accessible logs. To automate the monitoring of these results, we have defined auto-scheduled queries over BigQuery that check for features whose comparison results exceed their warning or alert thresholds. For features that exceed the warning threshold, a Slack message is sent to a dedicated channel. For features that exceed the alert threshold, a Slack message is sent along with a PagerDuty notification to the on-call person, ensuring prompt attention to critical discrepancies.
By implementing these automated checks and notifications, Sherlock ensures that any significant discrepancies between training and serving features are quickly identified and addressed, maintaining the integrity and performance of our machine learning models.
Discoveries and Impact of Sherlock
Since its release, Sherlock has identified multiple broken features, allowing us to make critical fixes that have significantly improved our models. Here are some examples of the types of bugs Sherlock has uncovered:
- Non-Equal Logic in Feature Building: One common issue was the use of different logic for building features during serving and training. The fix involved ensuring that the same function was used on both sides, eliminating duplicate logic that could be mistakenly altered on one side only.
- Inconsistent Feature Calculations: In some cases, features were calculated differently for serving and then recalculated with different logic for inclusion in the Pageview resulting in a broken report back value. The solution was to calculate the feature only once and use the same value twice. When this wasn’t feasible, we made sure the calculation logic remained consistent.
- Configuration differences: We have had multiple cases where the building logic of the feature is equal for serving and training but the configuration wasn’t the same. For example, the OOV values weren’t equal on both sides resulting in inconsistent models.
One of the most notable fixes involved correcting a broken feature that led to a significant increase in Taboola’s global Revenue Per Mille (RPM) by 1.31%. This improvement underscores the substantial impact Sherlock has had on our system’s performance.
A significant impact of Sherlock is to allow us to make the right calls regarding our models. For example, when Sherlock was first activated, it flagged several features as broken—features that were about to be removed from our models due to their perceived lack of value (which, of course, was because they were broken). Instead of removing them, we fixed the features and saw the positive impact they had when functioning correctly.
Conclusion
Training-serving feature discrepancies can be a real pain, reducing the accuracy of machine learning models and potentially leading to financial losses. When we noticed that features which previously boosted our models’ RPM stopped doing so, it became clear that we needed a solution like Sherlock.
The impact of Sherlock has been substantial for Taboola. By ensuring that our features are free from discrepancies, it has enhanced the reliability and accuracy of our machine learning models. Sherlock enables us to identify and address bugs promptly, even during the development and testing phases of new features. Moreover, it provides a safety net, alerting us if a feature is accidentally broken, and helps maintain the integrity of our recommendation systems.