Intro
First, some background about Spark in Taboola.
We use Spark extensively across many services and provide multiple ways to do so. One of the common ways to create a Spark Job is by using our “Analyzers” infrastructure.
When someone wants to create a Spark job which is based on our main data pipe, they can usually do it by implementing it as a simple Analyzer. An Analyzer is a Java class that mostly contains only the required Spark SQL query. The rest of the concerns will be handled by our infra – triggering it when new data arrives, writing the result to HDFS in a unified way, loading the results from HDFS into our Vertica database if needed, and handling reruns, monitoring and other Spark complexities.
As part of this Analyzers infra, after we get the user’s dataset and before we write it to HDFS, we also repartition it, with a configurable small number of partitions. We do that in order to control the number of output files, to avoid creating too many small files and overload the HDFS NameNode which manages this metadata.
Problem
The story begins with a complaint we got from one of the R&D teams saying that something is wrong with some of their Analyzers. Their output tables contained duplicate rows, even though it shouldn’t happen because the data is produced by jobs that calculate some simple aggregations using a group-by clause with a few key columns. For example, given a job with the following query:
Its output table contained more than one row per region, for some of the regions, and these rows were duplicates, including the value.
So we have a problem, something is not working as expected and the results in the relevant Vertica table are incorrect, but that was basically everything we knew at that point.
We had no way of knowing if the issue was somewhere in the Spark job or later in the process that loads the results to Vertica because the relevant data was no longer in HDFS due to retention.
We need more data, let the investigation begin.
*Side note – Our Vertica tables do not have any primary or unique key constraints because it’s causing performance issues when working with relatively large tables.
Investigation Begins
Clueless about the source of the issue, we started taking steps that will provide us more information on the next occurrences of this bug:
- We added monitoring on multiple Vertica tables, to alert us as soon as a duplicate row was found. For example, for the given query above, we queried the relevant table every few minutes, counting the number of rows per region and triggered an alert if the count was more than one.
- We increased the retention of the relevant directories in hdfs, so we can inspect the Spark jobs output once we will get an alert for the corresponding table in Vertica.
- We tried to reproduce the issue in a test environment, to see if we can get anything and understand if that’s an issue in the specific executions of the relevant problematic timeframes.
- We tried to look for suspicious Spark tickets that may be related (here)
The tests were not successful, we didn’t manage to reproduce the issue, but one day later we already got our first alert. We had new duplicate rows in one of the tables, and now that we still had the data in HDFS we could inspect it as well.
We could now see that it’s not an issue with the load to Vertica. The duplicate rows were already present in the data in HDFS, which means that we have a problem with our Spark Jobs.
Collected Evidences
We encountered this issue only a few times during a period of a few weeks since the first alert, but it was still enough to gather multiple observations along the way:
- The issue rarely happens, and when it does – rerun fixes the data. We have hundreds of Analyzers in Taboola, each of them can be triggered multiple times per hour, and yet during a period of a few weeks we encountered the issue only a few times.
- The issue affects a relatively small portion of the result rows. When it happens, only a relatively small subset of the result rows were duplicated.
- The duplicates issue was a problem in multiple Analyzers, not only some specific victim. All of them were quite simple without any esoteric operations, just some simple aggregation – grouping by a few key columns and calculating the sum of a few values etc.
- This is not only a duplicate-rows problem, we have missing rows too and their count is identical to the duplicate rows. In one of the first alerts, we counted the rows of the problematic execution in order to compare it to the rows count after the rerun. The rerun fixed the data, we no longer had duplicate rows in it, and yet – the total rows count stayed the same. If the rows count had the same value with and without the duplicates, it means that after the rerun we had rows that were missing from the first attempt, and their count is the same as the duplicates count.
- When the issue occurs, the Spark job finishes successfully, and the duplicate rows are present in different files. When we got the first alert, we examined the data of the relevant execution in the corresponding directory in HDFS. We noticed that the job finished successfully and each single file didn’t hold duplicates on its own. The duplicate rows appeared in two files, for example – some specific row was once in part-0 file, and once in part-4 file.
- We saw correlation to shuffle fetch failures. Every time that we got an alert and inspected the execution we saw FetchFailed exceptions. When Spark needs to perform a shuffle of the data to redistribute it differently across partitions, the shuffle will happen as follows: First, the map side tasks will map the rows of each source partition to the new target partitions and store these shuffle data blocks locally. Next, the reduce-side tasks in the following stage will try to fetch their subset of shuffle data from the previous tasks locations in order to create the new partition and continue. When they fail to fetch this data, FetchFailedException is thrown.
- We found a Spark ticket (SPARK-23207) that felt related to our issue. It was talking about a repartition operation and a failure that may lead to duplicate rows in the results. The thing is – this issue was fixed in a much earlier Spark version than ours, in Spark 2.x, while we were using Spark 3.1.2. On top of that, the ticket also provided an example code to reproduce it, and when we tried to execute it with our version, we didn’t get duplicates.
- Seems that we stopped getting duplicates in jobs once we disabled our pre-write repartition call (the one that we mentioned earlier, that we’re adding before the write in order to control the number of output files). Despite the failed attempts to reproduce the above Spark issue with our version, this direction was still our main suspect. Why? One of the tests we were running as part of the investigation was to disable the pre-write repartition, for some of the Analyzers. We didn’t experience the bug for this test group anymore.
Theory – Intro
With those observations in mind and after revisiting the fixed Spark issue, we came up with a theory that can explain what is going on and why the previous fix in the mentioned Spark ticket was not enough.
Let’s explain it with our per-region aggregation query example. Given such user’s query, the full Spark job will be made of:
As mentioned earlier, we take the user’s dataset, which is a result of a simple per-region aggregation query in this case, add a repartition call to reduce the number of the output partitions (to 3 in this case), and write it in HDFS.
Such a job will have the following structure (The diagram is partial, we focus on the main details):
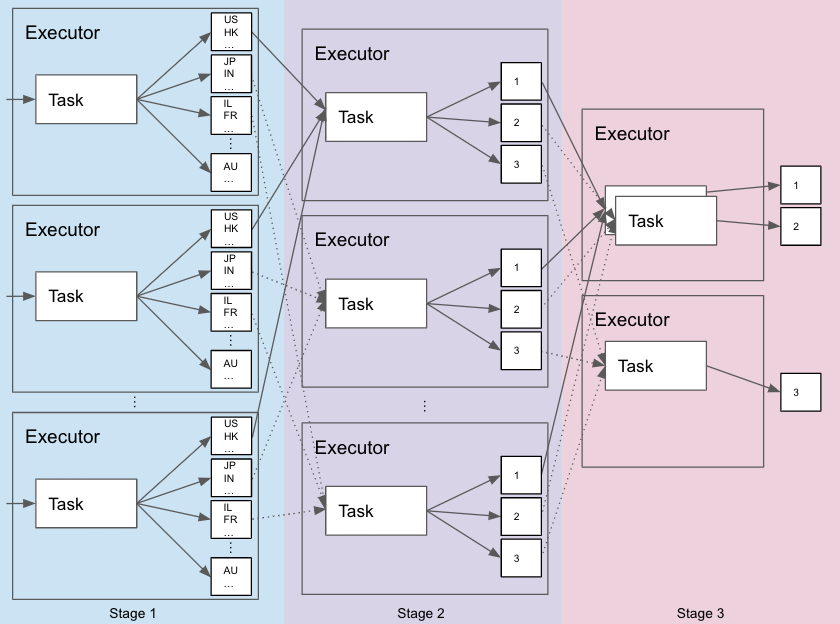
It will be composed of 3 stages.
- Stage 1 – Read input data from HDFS, calculate local partial sum of val per region, and map the results rows to the relevant shuffle data partitions, based on their region column that was used in the group-by, using hash partitioning.
- Stage 2 – Read the shuffle data from the previous stage, calculate the final sum of val per region, and map the results rows to 3 partitions. The partitioning of rows to partitions is based on round robin partitioning, but we will get back to that soon.
- Stage 3 – Read the shuffle data from the previous stage, and write the results to HDFS.
The first shuffle, that separates stages 1 & 2, was created as a result of the group-by operation.
The second shuffle, that separates stages 2 & 3, is a result of the repartition operation.
Theory – When Things Go Wrong
Let’s assume that the job has started, stage 1 and 2 completed successfully, and we’re somewhere in the middle of stage 3. Some of its tasks have finished successfully, tasks 1 and 3 in our case, but some did not, like task 2, and exactly at that point we’re losing some shuffle data from stage 2. How do we lose it? A node that had stage 2 executor running on, died and is not reachable anymore, for example. In this case, task 2 from stage 3 will fail and Spark will trigger retry of the relevant tasks from stage 2, to recompute the missing shuffle data, in order to be able to retry the failed task 2 in stage 3 and finish the job.
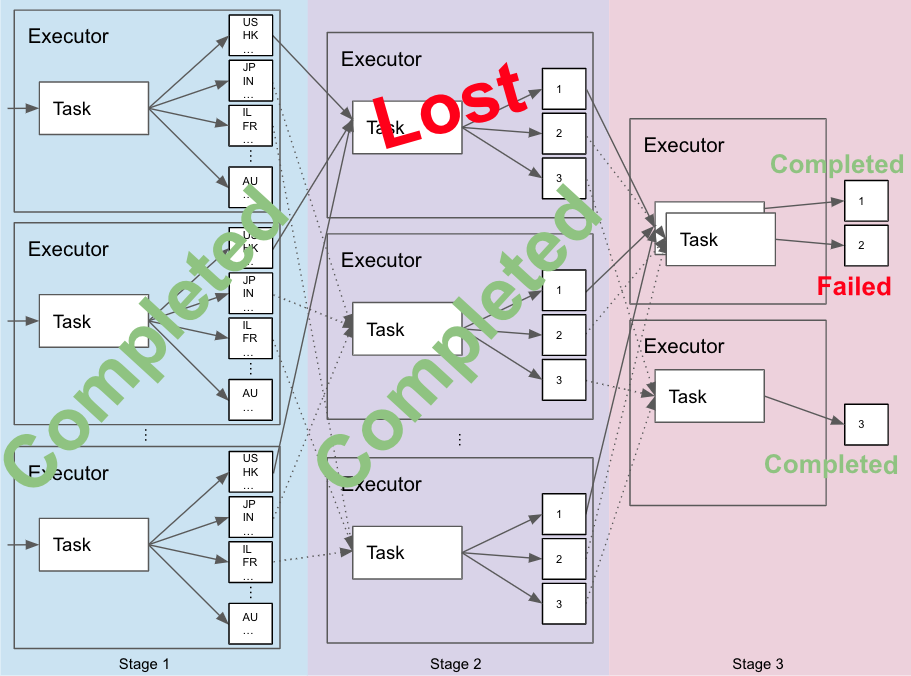
Before we will talk about the retry, let’s first take a closer look at stage 2 tasks:
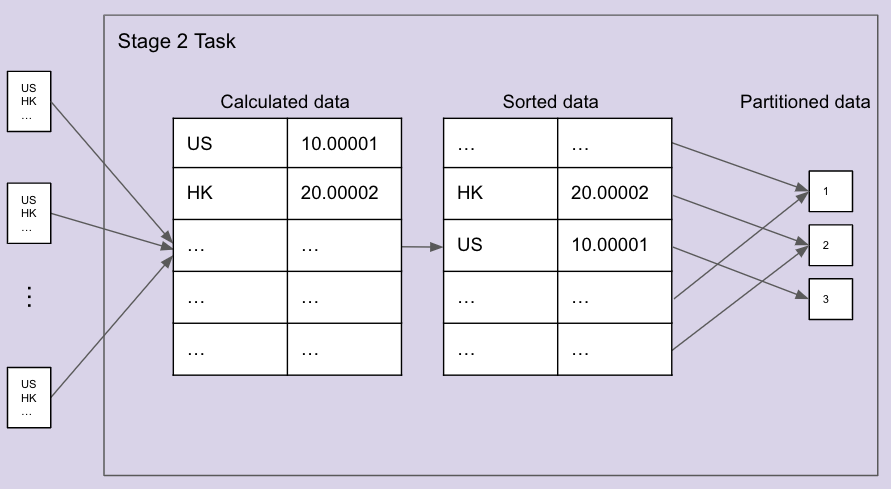
Each task will get the relevant shuffle data from the previous stage and calculate the final sum of val per region, for the subset of regions in its partition. Next, due to the repartition call, the partition will be sorted, based on the hashcode of the rows, and each row will be mapped to its target partition using round robin.
Wait, why does Spark sort the rows by their hashcode?
When repartition was born, this sorting preparation step didn’t exist. This local sort is the workaround that was implemented in Spark to fix the bug in the mentioned Spark ticket (see here).
Since the rows order in such a partition is not guaranteed, when a retry of such a task was triggered, the rows order was different and each row was mapped to a different target partition than before.
To avoid this issue, a local sort step was added per partition, to make sure that the mapping is consistent across retries.
So the partition will be sorted, what can still go wrong on a retry?
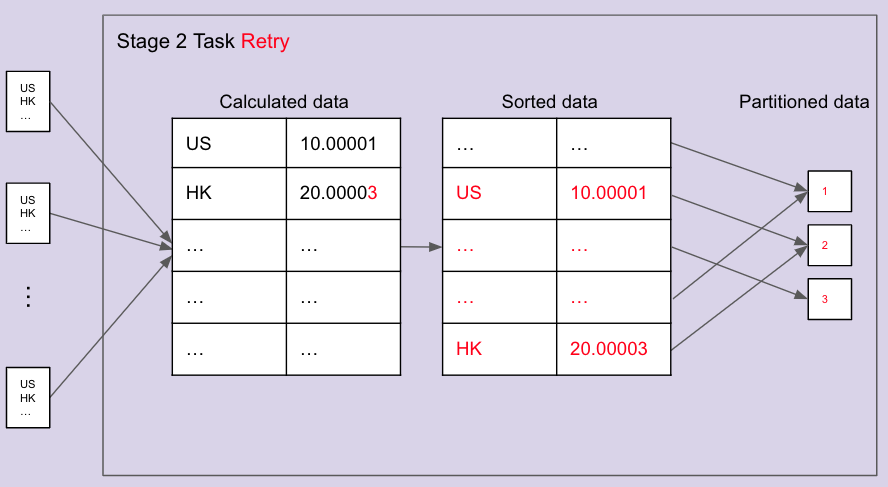
One more important detail about our job is that the val column data type is double.
When dealing with doubles, the sum recalculation might produce a slightly different value when performed in different order (sum of floating point numbers is not commutative).
Once a row has changed, its hashcode will change, its position after the sort will change, and it will shift multiple other rows even if they haven’t changed.
When the rows order after the sort is different, we are basically back to the original problem again. The rows will be mapped to different target partitions because the mapping is based on round robin partitioning.
Ok, we might get different target partitions on a retry, but why does it lead to duplicate and missing rows in the results?
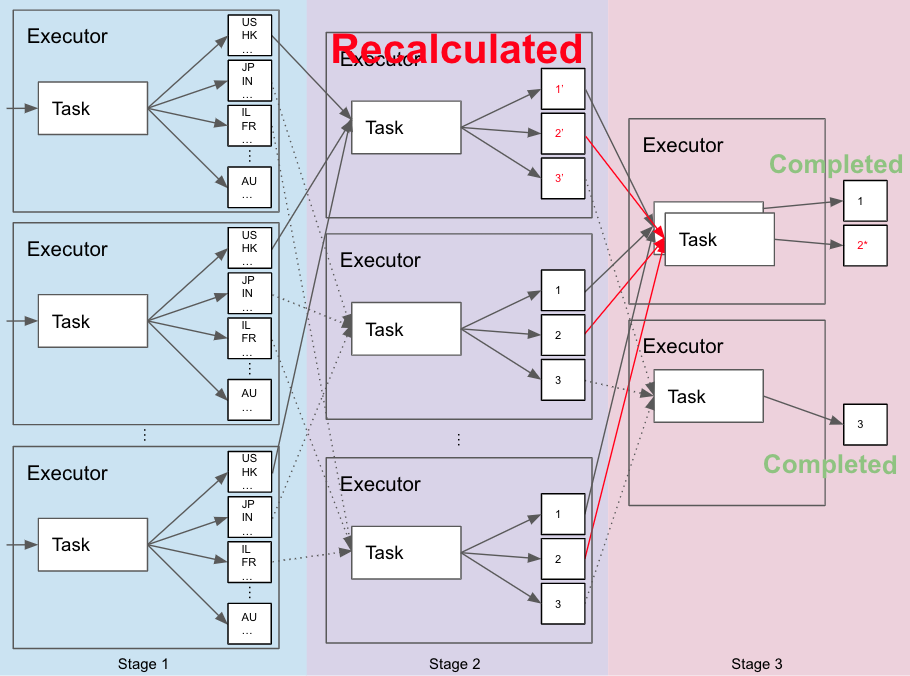
Need to remember that we started from a point where tasks 1 and 3 in stage 3 have already completed. They finished writing their files and they won’t be retried. Only task 2 is going to be retried now.
Add it to the fact that the recalculated partition 2′ from the previous stage is different than before and you’ll get that:
- It holds rows that were previously mapped to 1 and 3, and were written already, but now were mapped to 2 and will be written again, causing duplicate rows in the output.
- Rows that were previously mapped to 2, and were not eventually written, were now mapped to 1 or 3, that are not going to be written, causing missing rows in the output.
And why does the duplicate rows count equal the missing rows count?
The recalculated partition in stage 2 is always the same size, because it will always hold the same subset of regions.
The shuffle data partitions that are created from it are always the same size too, because the entire partition is the same size and its rows are mapped into target partitions via round robin that always begins from the same one.
So, retry or not, part 2 should always contain N rows in total. If X of them are duplicates, we must have X rows that are missing as well.
Reproducing it
Now that we had a theory and we understood the situation better, we wanted to create a test version that will reproduce it consistently in our environment and see the theory in practice. The test job was similar to this:
- We implemented a simple double-value-per-region calculation as in our examples.
- We added a code to kill an executor in the middle of stage 3. After we repartition and before we write the dataset, we added a dummy rows mapper that is not really doing anything but killing the running executor (calling System.exit(1)) after sleeping for one minute if we’re in the first attempt and we are not in the first two partitions.
We are basically exiting an executor while we are at the first attempt of the 3rd task (partitionId = 2) of the 3rd stage, after we sleep for enough time in order to make sure that the first 2 tasks of this stage will finish successfully.
This is not enough yet. In order to reproduce the bug, we want that losing this executor will cause loss of shuffle data from the previous stage, to trigger the desired retry of tasks from stage 2. In order to get it we changed few configurations as well: We executed the job on a small static setup of executors, with dynamic allocation disabled, to make sure that tasks from all the stages are running on all of them.
We disabled the external shuffle service, in order to lose the shuffle data when we lose an executor (external shuffle service is an external component in the cluster that can serve shuffle data even when its source executor is gone).
And we disabled Spark speculation, to avoid a too-early-retry of our sleeping task, before we wanted it to happen.
Success! We got the expected tests results:
- We got duplicates on every execution of this job.
- When we executed it without repartition, but with repartition that is based only on the region column, we didn’t get duplicates. To avoid being dependent on unwanted columns when we repartition, we can provide the key columns that we want Spark to use for the partitioning. For example, instead of:
We can do:
Which will use hash partitioning based only on the region column to partition it into n partitions, so we don’t care if the val column has changed a bit on a retry because it won’t affect the partitioning. And indeed, this time we didn’t get duplicate rows because the partitioning was consistent across retries.
- When we executed the same code, including the repartition, but instead of using a double type value column we used an integer column, we didn’t get duplicates.
Conclusion
We decided to consider repartition(N) as a non safe operation that should generally be avoided because it can’t really be used on an arbitrary dataset. Its result depends on the hashcode of the entire row, including non deterministic columns (e.g. floating point calculations, random values), and we saw that it can lead to correctness issues when retries are involved.
We also found a related spark ticket (SPARK-38388).
What are the current alternatives?
- Coalesce: We said that we mostly use repartition to limit the number of output files, so why don’t we just use coalesce? The reason is that coalesce happens too soon in most of our cases. It doesn’t add a stage and a shuffle, it works differently by merging the partitions of the given dataset. It’s not the desired behavior in most of our cases because we usually have a heavy computation that we want to keep running with the original higher parallelism and limit the partitions count only a moment after that. Using coalesce might cause performance degradation in most of our cases.
- Repartition over selected columns: As we saw, calling df.repartition(n) will repartition the rows based on their position in the source partition, after it was sorted by the rows hashcode which is based on all of their columns. We showed that we can avoid the bug by choosing our own safe subset of partitioning columns, as we did in our test with: df.repartition(n, col(“region”)).It can create skewed results compared to the uniform partitions created by the round robin partitioning, but in practice it’s not really an issue in our case and we usually have wide enough columns to use when repartitioning, so skewness is mitigated.
- Working with big decimal data types instead of double/float types: This is a good approach regardless of this issue and used in other places in our system, but it doesn’t come for free (more resource demanding), and it’s not always required. For every job the owner can decide if floating point calculation is enough in its case or not. In addition, in this case it required more changes on our side and would not fully protect against similar variants of this bug (because, as we mentioned earlier, the floating point issue is only a specific example of this bug, which can generally occur in any scenario with a non deterministic column).
Repartition over selected columns was our chosen solution. Since we do that in the infra and not specifically per Analyzer, we implemented it dynamically based on the column types of the given dataset. We get the user’s dataset, extract its schema’s columns and choose a subset of columns for the repartition based on their types (float & double columns are not allowed, etc). This is the default behavior, but it can also be customized per Analyzer if needed. Note though that this approach is not bulletproof. For instance, a boolean column may be computed based on a float column, and therefore still be non-deterministic.
We also plan to check additional directions. One possible alternative that we’re looking into includes the new dynamic coalesce abilities that are part of the adaptive query execution in the new Spark versions. We already verified that it eliminates the problem as well, but we still need to test it because we want a solution that will have minimal impact on production. We want to avoid the concern of tuning the hundreds of different queries we have, and adaptive query execution sometimes requires it.
Bugs can be annoying most of the time, but if you’re lucky enough (or unlucky, depending how you see it) they can also be very interesting. As part of our work in the Data Platform group at Taboola, we experienced one pretty elusive and interesting bug recently.