In part 1 of the series we shared the architecture of Taboola’s PV2Google service which uploads over 150TB/day to BigQuery.
In this article (part 2), we’ll share the challenges and lessons we’ve learned over the course of a few years.
Lesson 1: queries might be (extremely) expensive
We continuously upload pageviews to BigQuery and keep them for six months. This translates to over 13PB of pageviews in BigQuery. Querying the entire dataset would be extremely expensive, about $65K/query (assuming $5/TB).
We apply a few methods and guidelines to substantially reduce this cost:
- Never use `SELECT *`: BigQuery’s query cost is based on the size of the data scanned. Most queries actually need only a few fields. Hence, selecting only the relevant fields will dramatically reduce the cost of the query.
- Cluster tables: clustering is a neat BigQuery feature that reduces the scanned row count. With clustering, BigQuery optimizes the data layout to reduce the scanned data size when filtering on a clustered field. For example, with clustering on ‘siteName’ field, a query containing ‘WHERE siteName = example.com’ will only scan rows matching that filter rather than the entire table, reducing the cost significantly.
- Partition/shard tables by day: most queries use a timespan of week or a month. Daily partitioning of tables enables scanning only the relevant days, eliminating the cost of scanning redundant data.
- Sample tables: many queries calculate statistical information on the pageviews (e.g. click ratio). Such statistical data can also be determined from querying a sample of the pageviews. This is much more cost effective. Hence, in addition to the complete pageviews tables, we also have 0.5% sampled pageviews tables. Using the sample tables reduces the cost by a factor of 1:200.
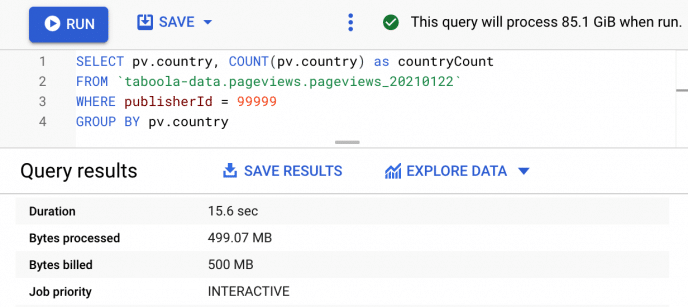
Figure 1. A query demonstrating: (a) Selecting only relevant fields. (b) Using publisherId clustered field to reduce bytes billed from 85.1GB to 500MB. (c) Querying a single day table
Lesson 2: multi-layer retries are essential
Ideally the PV2Google service functions without human intervention. On the other hand, the service is complicated and depends on other internal and external services. These services might temporarily fail or be unavailable. We do our best to contain and automatically recover from these problems.
Airflow operators execute their tasks by submitting jobs to the PV2Google engine. Temporary Internet issues or Google service interruptions might cause these jobs to fail. To mitigate this, we leverage the Airflow operator retry feature. Airflow will automatically retry the failed operators a few times before giving up.
Airflow operator retires are a simple solution that work well. However, it is an expensive solution because operator execution can be long. In most cases only a small portion of the operator work fails, and it can be recovered by retrying only the part that has failed. Retries at lower layers do the trick:
- Spark task retry: a spark job builds and uploads the pageviews to Google Cloud Storage using thousands of Spark tasks which create thousands of files. It is likely that a few of those Spark tasks will fail due to Internet failures. To avoid failing the entire Spark job along with the Airflow operator, we use the Spark task retries feature. Each Spark task may retry a few times. In most cases this will save the job. If the problem is persistent, Spark will give up and the entire job will fail.
- REST API retry: Airflow and the engine communicate over REST API. The API is vulnerable to internal networking problems. Hence, API retries are important. To retry at the REST API layer, we extended Airflow’s HTTP hook with a state-machine to gracefully recover from such problems. For example, retry on timeout, but fail (without retrying) on 4XX responses. These retries are transparent to the Airflow operator.
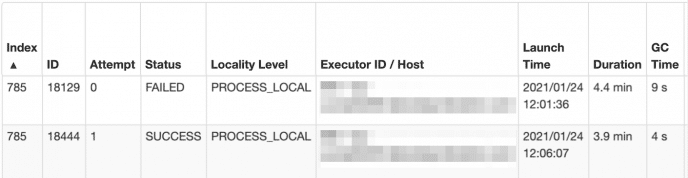
Figure 2. Spark task 785, attempt #0 failed, retried and succeeded on attempt #1
Lesson 3: appends might corrupt your data
In some PV2Google’s workflows, we append an hourly stage table into a daily production table. Appending the same stage table twice will lead to duplicate data. For example, Airflow might retry the append (copy) operator, which can lead to double append. Obviously, this must be avoided!
The bright side is that Google jobs are atomic. They’re either completely successful, or in case of failure, do nothing at all. This is the key to avoid double appends. All that’s left, is to make sure we run Google’s append job exactly once. We do that by checking the status of the existing job before submitting a new one:
- Job does not exist: this is the typical case (first append), when we definitely did not append the data before. Hence, we can safely execute the append job.
- Job successful: we already appended the data. There’s nothing more to do.
- Job faile: Something bad happened at the last attempt. The data was definitely not appended, because the job is atomic and failed. So we submit the job again.
- Job running: We “adopt” the running job and wait for its completion.
How do we know which BigQuery job ID to look for? The trick is to calculate a unique job ID ourselves rather than letting BigQuery generate it randomly. Before submitting the job, we attach the job ID to the destination table in a label to ensure we always can retrieve it.
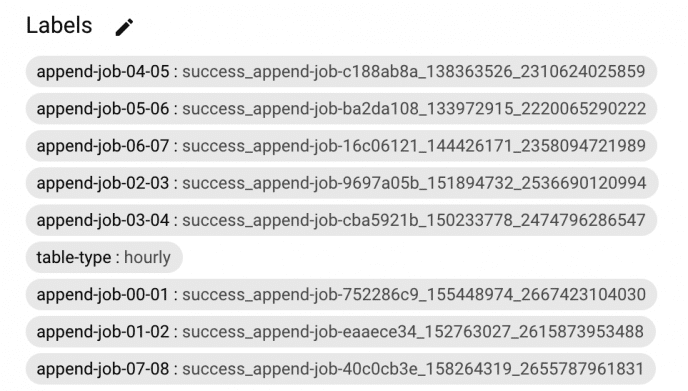
Figure 3. Table labels keeping job ids
Lesson 4: mind the uploads duration
A few hours after the end of each day, we re-upload the pageviews of the day to BigQuery to ensure BigQuery has the most complete and up to date pageviews, including data that arrived recently. The load size is 75TB and it takes about 10 hours. Initially, we uploaded the entire day in one step. This turned out to be problematic.
If an upload fails just five minutes before its completion, we would have to retry and repeat the entire 10 hours upload. Furthermore, the longer the step, the higher the probability it would encounter a problem and fail.
To mitigate that, we split the day upload into 24 independent hourly uploads. This aligns well with Airflow’s periodic processing. We just changed the Airflow 24 hour cycle to a one hour cycle.

Figure 4. PV2Google Airflow DAG, data is uploaded every hour while it is copied to production only daily
The devil is in the details
The right architecture is important but not enough, the devil is in the details. Paying attention to the lessons described above makes the service scalable, reliable and cost effective.