In today’s fast-paced world of data-driven applications, real-time access to database changes is no longer a luxury, but a necessity. Whether it’s for real-time cache updates, continuous data replication, or fraud detection, the ability to capture and process these change events in real-time unlocks a world of possibilities for modern data architectures.
This blog post describes the Change Data Capture (CDC) solution we built for streaming tables’ change events (both DML and DDL operations) from our backend MySQL cluster to our main Kafka cluster, utilized by a diverse range of services. We’ll explore the chosen architecture, focusing on Debezium, Kafka Connect, and Avro serialization.
In addition, we’ll explain in detail how we configured Debezium in a non-standard way to meet our unique requirements and ensure a seamless migration from our previous CDC service. We’ll also discuss the challenges that emerged during the process and how we successfully overcame them.
The Challenge
At Taboola, we were previously using an in-house developed service (built on top of the widely-used library mysql-binlog-connector-java) to capture and stream DML events from MySQL tables to Apache Kafka, enabling real-time cache updates across our various services.
While this service performed well for several years, its maintenance was becoming increasingly challenging:
- The library stopped receiving updates and bug fixes. As a result, we occasionally encountered newly discovered bugs that required manual intervention.
- We experienced intermittent instability issues due to its custom implementation for managing Kafka offsets.
Therefore, we decided to look for a well-maintained open-source alternative that would meet our needs. We also wanted to take advantage of this opportunity to find a more versatile CDC software that could easily integrate into our wide range of data pipelines.
Introducing Debezium
After a thorough evaluation of various open-source CDC platforms, Debezium stood out as the leading choice in terms of functionality, maintenance and robustness. Additionally, it supports many other popular DBMSs apart from MySQL, including: PostgreSQL, MongoDB, SQL Server, Oracle and Cassandra.
Another significant advantage is Debezium’s large and active community, which provides exceptional support and resources.
With these factors in mind, we decided to use Debezium to facilitate the MySQL part of the overall solution. However, to fully meet our specific needs, we found it necessary to go beyond the default settings and customize it in several ways. We’ll dive deeper into these customizations and how they unlocked the full potential of Debezium in the following sections.
Key Requirements and Overall Goals
First, we needed to address all the requirements for building an optimal solution while ensuring backward compatibility with our previous service.
To achieve this, we formulated the following set of requirements:
Consumer requirements:
- Single target topic
All events, from all captured tables, should be streamed into a single Kafka topic. This was essential to ensure backward compatibility with our previous service.
- Event record structure
The record key should be a string that represents the full table name in the format schema_name.table_name.
The record value should be a nested structure, including the changed row values both before and after the change.
Producer requirements:
- Fault-tolerance
The producer must be resilient and highly available.
- MySQL GTID support
It must support the MySQL GTID mechanism to ensure that no events are missed, even in the event of a MySQL source server failover.
- Minimal latency
Events’ latency from MySQL should be as low as possible, ideally within the sub-second range.
- Minimize requests rate and efficient batching
To prevent overloading the Kafka cluster and reduce network round trips, the producer should maintain a reasonable request rate, ideally between 5 to 10 requests per second.
Additionally, aggregating as many events as possible within each request will enhance batching efficiency.
- Storage space efficiency
Aim for compact-sized streamed records to reduce Kafka topic size and optimize network bandwidth usage.
Solution Overview
After conducting thorough research and extensive testing, we reached the following solution:
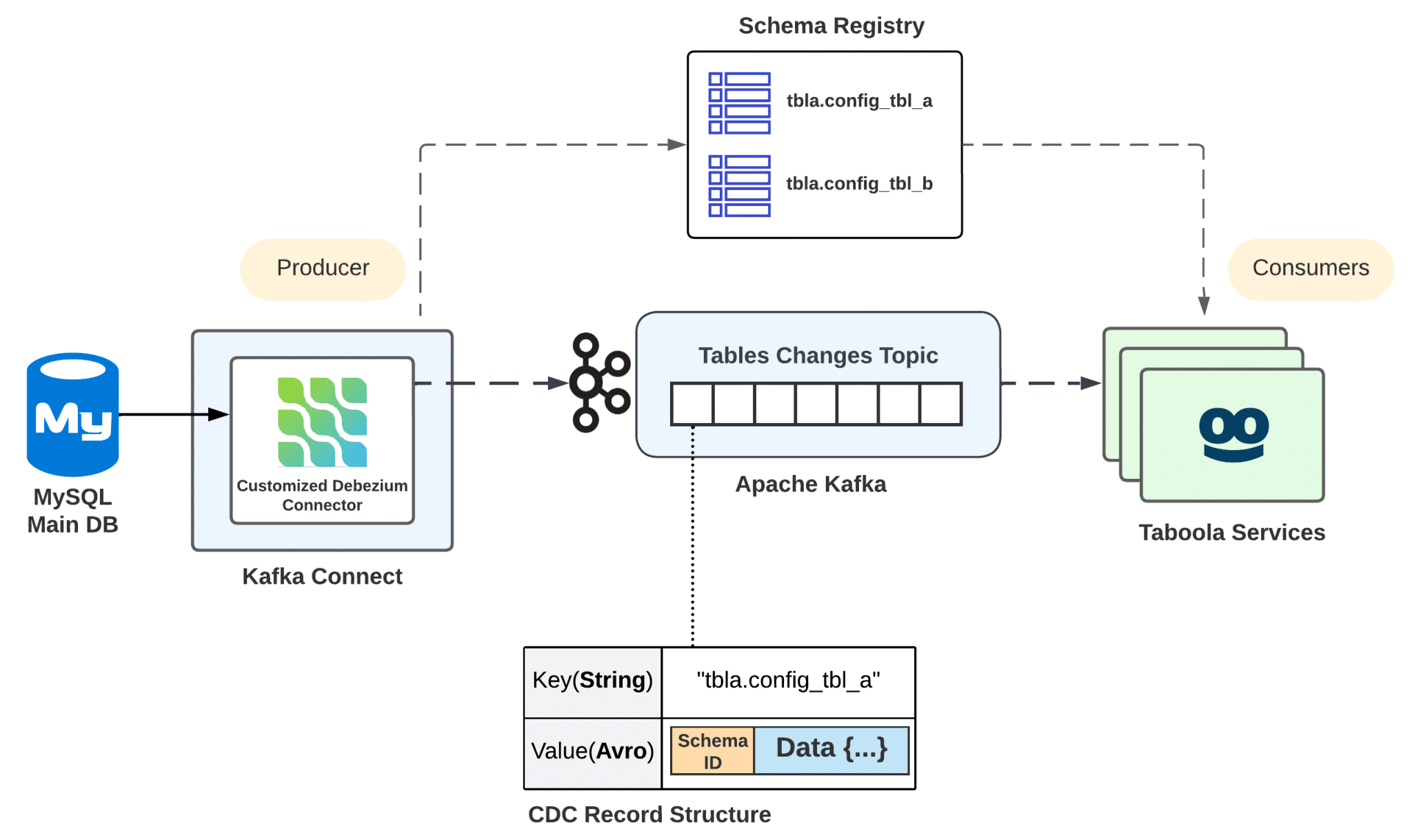
Figure 1. The solution design (in high-level)
The solution is based on the following two main components:
1. Kafka Connect with a customized Debezium connector
We deployed a Debezium connector for MySQL, customized to our specific requirements, on top of Kafka Connect. This is the recommended deployment type by Debezium developers.
Kafka Connect is an open-source framework designed to seamlessly integrate Apache Kafka with external systems. It provides connectors for a wide variety of external data sources and sinks, for ingesting data into Kafka or exporting data from Kafka. It is fault-tolerant and scalable, making it a powerful tool for data integration.
2. Avro serialization
By default, the Debezium connector produces records in JSON format. While this is generally acceptable for databases with a low to medium transaction rate, it can present challenges in write-intensive workloads, as in our case.For us, Avro serves as an excellent alternative to the JSON converter. It serializes the record keys and values into a compact and efficient binary format. This, in turn, reduces the overall load on the Kafka cluster and results in smaller Kafka topics.
In our particular case, we only needed to serialize the record value in Avro format since we designed the record key as a simple schemaless string value.
To enable Avro serialization, we needed to set up a Schema Registry service. This service acts as a centralized repository for managing schemas used for data serialization within Apache Kafka. It plays a pivotal role in data governance, offering features such as data validation, schema compatibility checking, versioning, and evolution.
Currently, we are only using its core functionality, but we look forward to exploring the rest of its valuable features and integrating them into our data streaming infrastructure, taking it to the next level.
Debezium Custom Configuration
What we already had out-of-the-box
We were already able to accomplish some of the requirements by utilizing Debezium’s out-of-the-box capabilities:
- Event record structure
Each record value produced by Debezium includes the changed row state both before and after the change, plus additional useful metadata such as the change timestamp, transaction ID and more.
On the other hand, the record key defaults to a structure composed of the changed table’s primary key fields – which was not compatible with our requirement. We resolved this issue by applying multiple transformations on the produced records (see Transformations Config below).
- MySQL GTID support, Minimal latency
Both are supported by Debezium out of the box.
- Fault-tolerance
Debezium is designed to handle a range of failures (such as a MySQL database crash) without ever missing or losing a change event.
Additionally, the high availability capabilities of Kafka Connect significantly enhance the resiliency of the Debezium connector.
In order to fully meet the rest of our requirements, we made additional custom configuration changes to the connector, which include:
- Transforming the produced change events records by using Kafka Connect Single Message Transform (SMT) feature.
- Customizing the serialization formats of the record key and value by overriding the default properties of Kafka Connect converters.
- Overriding some of the Kafka producer properties used by this connector.
- Fine-tuning several internal configuration properties of the Debezium MySQL connector.
Let’s take a closer look at the corresponding sections in the connector’s configuration.
Transformations config
Single Message Transform (SMT) is a simple interface for manipulating records within the Kafka Connect framework. As the name suggests, each transformation operates on every single message (record) in the data pipeline as it passes through the Kafka Connect connector. For example, you can add, rename, or drop a field, or even change a record’s topic.
In our case, the Debezium source connector passes records through these transformations before they are written to the Kafka topic.
We configured four different transformations to be applied on each event record produced by Debezium:
1. RemoveOptionalDefaultValue
This is a custom transformation developed at Taboola as a workaround for an issue encountered with the Avro and JSON converters.
For reasons unknown to us, these converters replaced all explicitly specified NULL values in optional fields with their corresponding default values, as defined in the record’s schema. While this behavior may be suitable for many other use cases, it did not align with our requirement to preserve the exact row values from the source database.
The transformation operates on the record schema by removing the default value associated with each optional (nullable) column.
As this behavior has recently become configurable in both Avro and JSON converters, we’ll likely no longer need to use this transformation in the near future.
For more detailed information, please refer to:
- Debezium Jira: DBZ-4263
- Apache Kafka Jira (JSON Converter): KAFKA-8713
- Confluent GitHub (Avro Converter): Issue #2314
2. ByLogicalTableRouter
This transformation is provided by the Debezium platform (see Topic Routing section in Debezium docs).
We configured it to perform two actions:
-
- Add a new field __source_table_name to the record key. This field contains the full table name from the MySQL source (e.g: “__source_table_name”: “tbla.config_tbl_a”).
- Modify the target topic name in the record metadata from Debezium’s default format connector_logical_name.schema_name.table_name to schema_name.table_name.
This affects the Connect record schema name that Debezium generates, which is derived from the target topic name (see Figure 2 below).
It ultimately affects the Avro schema name registered in the schema registry by the value converter (more details in the following Value Converter section).
Please note: This transformation will work as expected as long as the captured table has either a defined primary key or unique key.
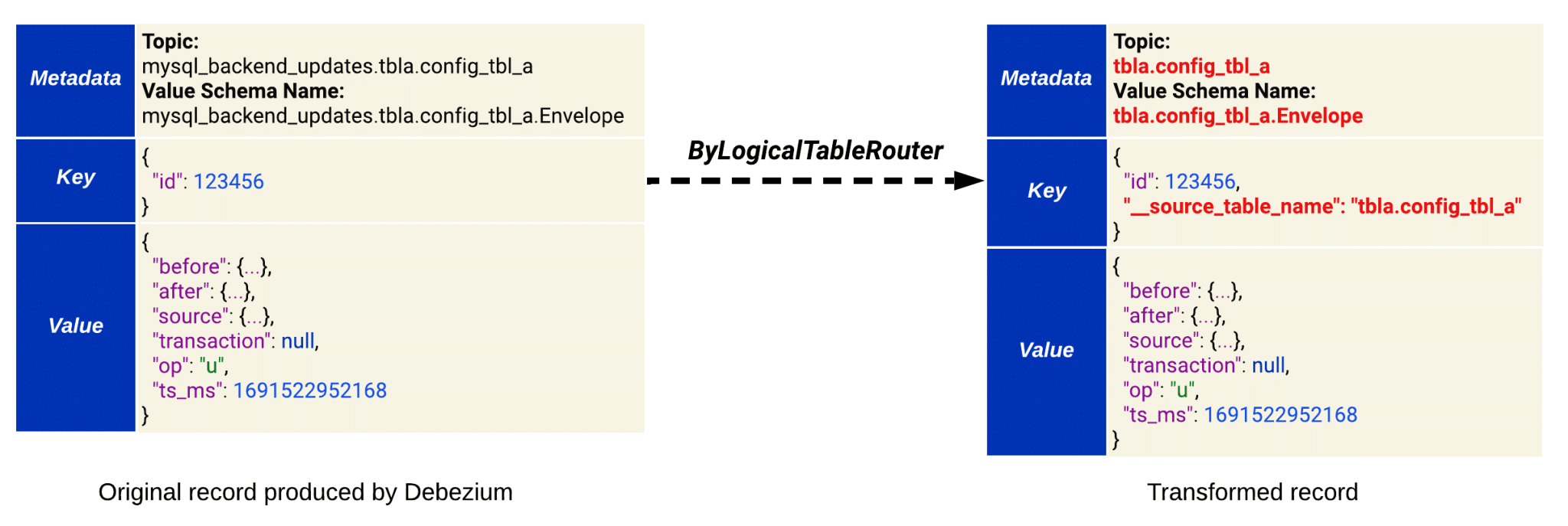
Figure 2. How ByLogicalTableRouter transformation operates based on our configuration
3. ExtractField
This is a built-in transformation provided by Kafka Connect (see ExtractField in the docs).
It is applied to the record key – which, as previously mentioned, comprises the primary key fields of the changed table along with the __source_table_name field (that was added by the previous transformation).
This transformation extracts the value of the __source_table_name field and sets it as the new record key.
In other words, it transforms the key from a structure with multiple fields and values into a single string value (see Figure 3 below).
For example, the structured key { “id”: 123456, “__source_table_name”: “tbla.config_tbl_a” } would be transformed into the string “tbla.config_tbl_a”.
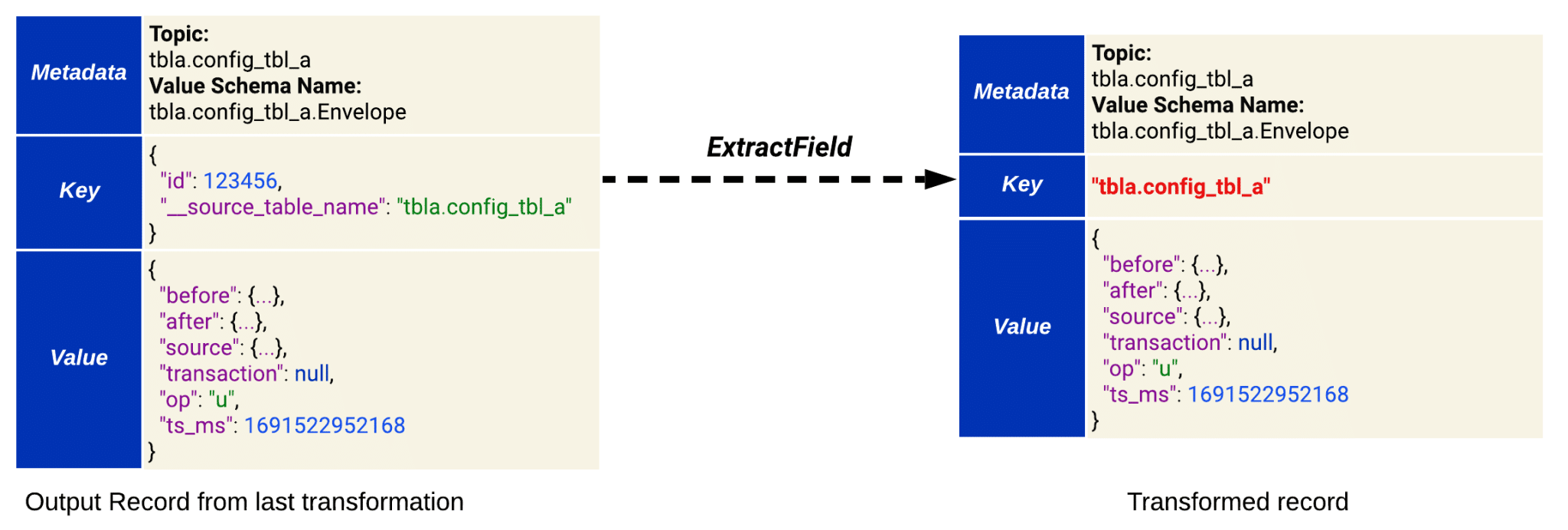
Figure 3. How ExtractField transformation operates on the record key
4. RegexRouter
This is a built-in transformation provided by Kafka Connect (see RegexRouter in the docs).
By default, Debezium assigns the target topic for each event record based on the table that event is associated with (resulting in a distinct Kafka topic for each table). This transformation simply changes the target topic for each record to “table_updates”.
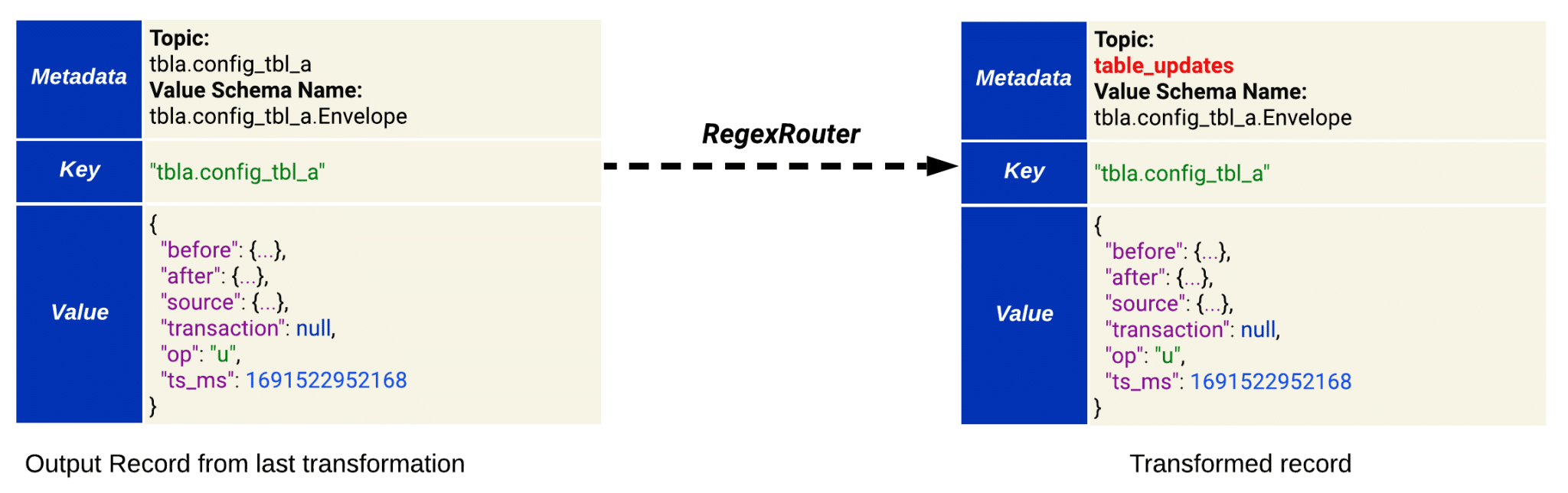
Figure 4. How RegexRouter transformation modifies the record’s metadata
Applying these transformations allowed us to successfully address the remaining consumer requirements:
- Single target topic
- Event record structure
Converters config
Following our (unique) data serialization choices, we needed to configure the suitable Kafka Connect converters for both the record key and value.
1. Key converter:
Since the record key was transformed from structure into a simple string value (using the ExtractField transformation), it should now be serialized as string. Therefore, we set the StringConverter as the key converter.
2. Value converter:
Since we decided to serialize the record value in Avro format, we set the AvroConverter as the value converter. However, because we are producing events with multiple schemas (one schema per table) under the same topic, it didn’t make sense to use the schema registry’s default subject name strategy: TopicNameStrategy. This would have resulted in all of the different schemas being registered under one subject named table_updates-value in the schema registry.
To address this, we changed the subject name strategy to TopicRecordNameStrategy. This strategy registers each schema under a separate subject in the form of topic_name.schema_name. This allows us to keep the different schemas separate, and it also allows us to manage multiple versions of each schema.
For instance:
- The subject table_updates-tbla.first_tbl.Envelope stores the schema of tbla.first_tbl table events (and all of its versions).
- The subject table_updates-tbla.second_tbl.Envelope – stores the schema of tbla.second_tbl table events (and all of its versions), and so forth.
Kafka Connect producer config
By default, connectors inherit their Kafka client configuration properties from the Kafka Connect worker configuration.
To achieve our desired request rate and efficient batching, we found it necessary to override the following producer-specific properties within the connector configuration:
- The producer.override.compression.type property specifies the compression algorithm applied to the produced record batches. We changed its value from the default ‘none’ (no compression) to ‘lz4’ because, based on our experience, LZ4 offered the fastest performance.
We also increased the value of producer.override.batch.size from 16KB to 10MB to allow for larger batches. This led to better compression ratios and ultimately increased the overall throughput. - To reduce the overall number of requests made to the Kafka cluster, we increased the value of producer.override.linger.ms to 250. This means that the connector will wait up to 250 milliseconds for additional event records to accumulate before sending them together as a batch, rather than dispatching each record as it arrives.
Debezium internal config:
To prevent Debezium itself from becoming a bottleneck within our streaming pipeline and to fully optimize its performance, we fine-tuned the following internal configuration properties:
- We reduced the poll.interval.ms property from its default of 500 milliseconds to 200 milliseconds. This allows the connector to poll MySQL for change events more frequently.
- Furthermore, we set significantly high values for the max.batch.size (default: 2048) and max.queue.size (default: 8192) properties. This ensures that the connector can keep up with the MySQL database, even during periods of exceptionally high workloads.
Putting it all together
Here’s a complete example of such customized Debezium MySQL connector:
Conclusion
Setting up this new infrastructure, along with the customizations we implemented, enabled us to fulfill all the requirements, resulting in a smooth migration from our in-house solution. Moreover, it established the groundwork for implementing CDC-based data pipelines in various other use cases, extending beyond real-time cache updates.
Migrating to an open-source-based solution posed quite a few challenges along the way, involving a learning curve regarding Debezium’s internals and the Kafka Connect framework. Nevertheless, the overall successful outcome made the journey completely worthwhile.
Final Thoughts
We’ve been using this solution for over a year now, seamlessly integrating it into multiple streaming data pipelines developed to address various use cases. It has consistently proven to be high-performing, reliable, well-maintained, and versatile.
Furthermore, all of the mentioned open-source components (Debezium, Kafka Connect, Confluent Schema Registry) have vibrant and supportive communities. Personally, I’ve been particularly impressed by the support from the Debezium community. I encourage you all to join their Zulip chat and check out the insightful discussions there.
On a separate note, we’ve actively contributed to Debezium by proposing new features and providing a few bug fixes (which may even be a topic for another blog post).
We believe that Debezium is a valuable tool for data engineers and architects, and we are excited to see how it continues to evolve in the future.
Notable References