
Using Samplex to Scale Up your Spark Jobs
When I encountered Taboola’s data a few years back it struck me that everything I’ve heard and learned about Big Data wasn’t really Big Data.
Understanding Scale
Taboola’s big data environment is on a massive production scale, with petabytes of data flowing through data pipes. And with thousands of different workloads running constantly over this data, Taboola generates enormous amounts of raw data each day, ~100TB, not including all further aggregations created for the sake of reports and analysis. Such data is constantly used in various applications throughout the company, in applications such as Deep Learning, business intelligence (BI) analysis, and reports. 
When working with big raw data, we often seek to optimize downstream jobs and prevent unnecessary crunching of the entire dataset. This is achieved by creating subsets of the raw data typically needed for different jobs or common queries. A classic example is applying the same filter over data for different downstream pipelines.
Multiple Reads Wastes Resources
Over time, we at the Data Platform Group identified a growing number of Spark jobs that produced different subsets of our full dataset for later use in downstream queries. Each of these queries required substantial resources to query the full dataset, filter it, and save it back to HDFS. It seemed like a waste of resources… if only we could read the full dataset once and produce all these subsets in a single Spark job.
The naive and straightforward approach is to produce different subsets of the data by reading the source data frame and then save the data multiple times with multiple predefined filters, as in the following example:
Spark is lazy, each write action would trigger the entire DAG (a workflow on Spark’s scheduling layer) for that action, so it will require Spark to scan the whole data several times with a corresponding number of write actions. We could rather try caching the input data. Unfortunately, we are dealing with huge amounts of data that is too big to fit in memory, even with dozens of executor nodes.
In addition, each subset we produce might benefit from predicate pushdowns and other storage optimizations to avoid reading the entire data. But with many different filters, and over very complex schema, we can’t really store the full data optimized for every read path, without keeping different projections of the full dataset.
Read Once Write Many
We decided to accept the challenge and find a solution that would involve a single Spark action, with no caching (and without reading the data multiple times). Our solution, which is described hereinafter, saved us an abundance of resources, and we even open-sourced it.
We realized that we needed to return to basics and take ourselves out of our Spark SQL comfort zone. We used Spark core functionality to go over each Parquet row, apply a series of different predicates to decide which subset(s) of data it should be written to, and write to multiple output locations the rows that met the predicates’ conditions.
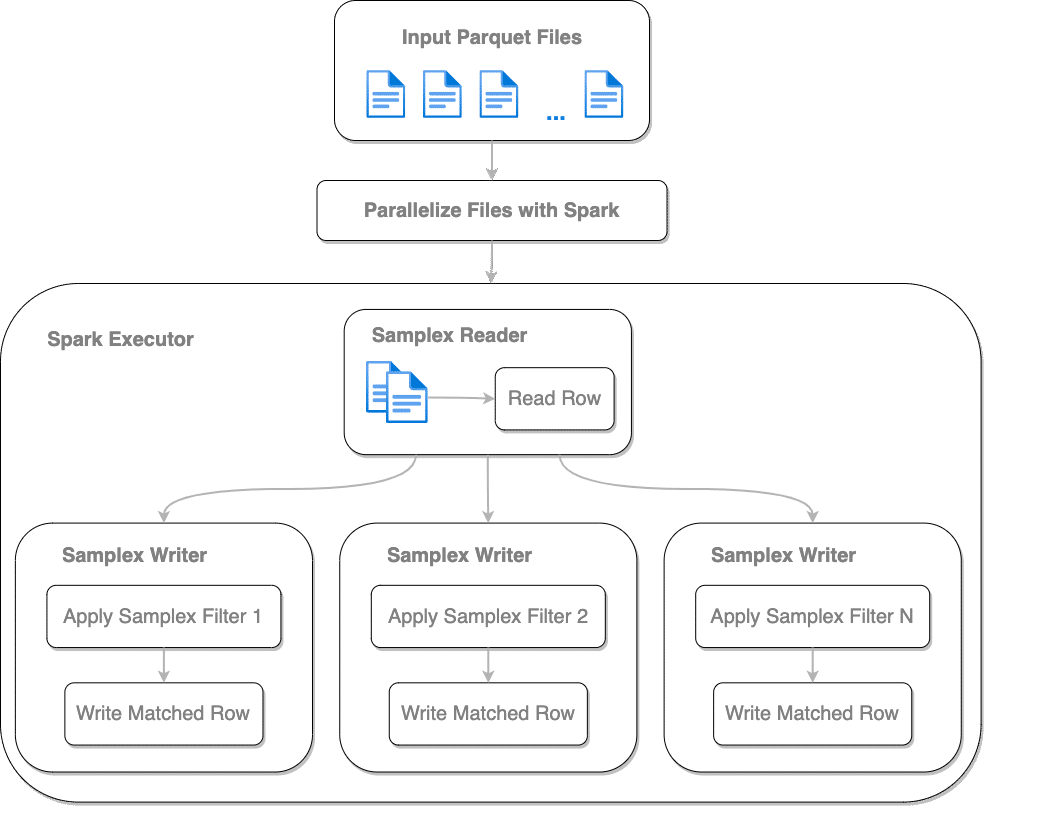
Samplex Usage
The Samplex application programming interface (API) implements two interfaces for every output dataset. The first is `SamplexJob`, which defines the destination path for the output written to, and a `SamplexFilter` that defines the predicate used.
SamplexJob – in which you should provide destination path, Record, and Schema filters.
SamplexFilter – which will tell to the samplex which record should write to output
SchemaFilter (optional) – in which the user should define the fields to keep or remove based of Block/Allow lists. When you have your SamplexJobs ready just create a SamplexExecuter and provide your jobs.
Please look at the full examples at GitHub.
While testing Samplex, we encountered a bug (as described in PARQUET-1441), in order to solve it we used the latest version of the parquet-avro library and used maven-shade-plugin to relocate it under Samplex open-source.
Things to Note
Using Samplex, there are few considerations that one should be aware of:
- Parallelism – With Samplex, each parquet part is fully processed within a certain task, and data cannot be split and repartitioned to achieve higher parallelism. Basically, Samplex is capped in parallelism by the number of input files. This means that if a parquet part contains multiple row groups, they cannot be processed in different spark partitions as they might be with SparkSQL.
- Number of output files – The output of Samplex is also determined by the parallelism used. If a certain output subset is very small, it cannot be coalesced to fewer parquet parts, i.e., all outputs are written with the same parallelism.
- Predicate Push Down – Samplex cannot benefit from any predicate pushdown mechanism, as this is counter to the idea of Samplex where each output uses a different filter. Applying predicate pushdown would require intersecting the predicates for all subsets of data.
- Tuning – Additional configuration that may help to boost performance is to add more cores per task (spark.task.cpus) as writing of outputs performed in parallel in the same task.
Some of the concerns above will be resolved as Samplex development continues. Note that all developers can contribute to future Samplex versions, whether it’s by identifying and resolving bugs, suggesting new features or improvements or simply by brainstorming.
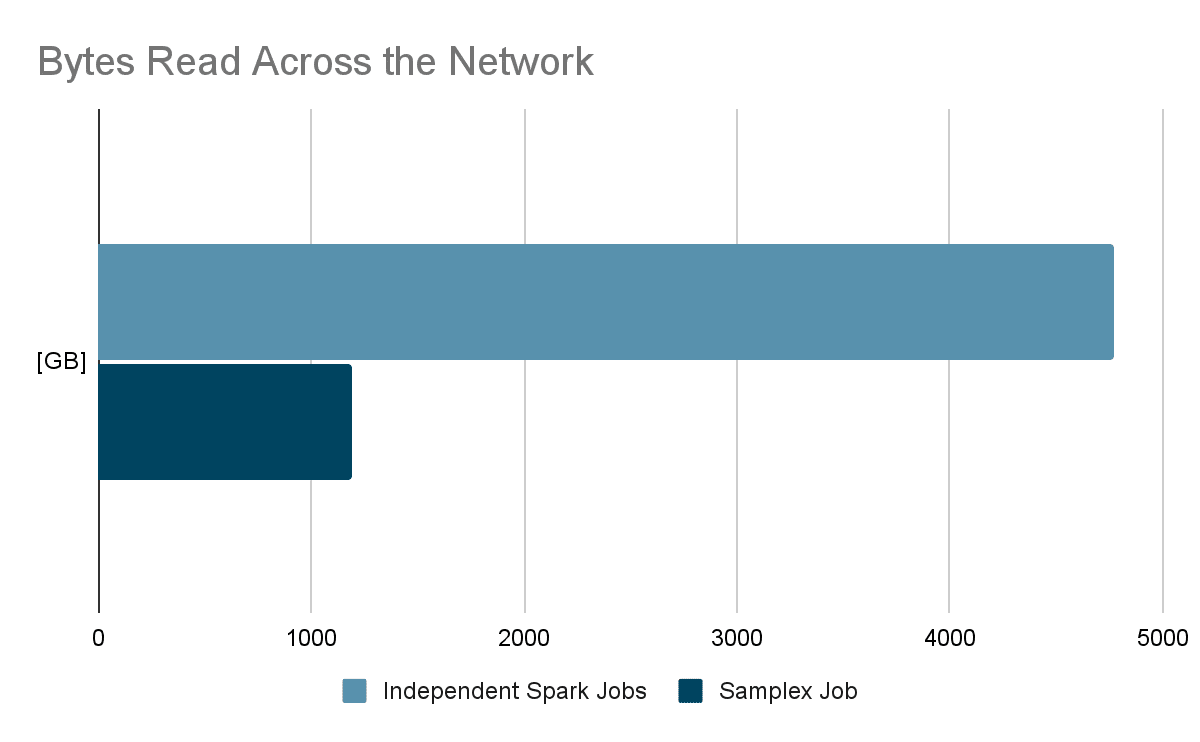
Results
Our benchmark of Samplex vs naive usages of Spark SQL to produce sampled data, included 4 sampling filters over 1.1TB of parquet data. In both cases, we allocated 800 CPUs for Spark. Moreover, to avoid any bias of data locality, Spark executors were not running over HDFS cluster machines.
During our proof of concept (POC), we found a significant improvement in execution times with the same resources as used before, with over 50% reduction in overall duration and even greater reduction in total bytes read. The overhead of adding another filter for Samplex is much smaller when compared to adding another independent Spark job. Furthermore, by using threads for writing the output we were able to exploit our resources more effectively.
Our benchmark was conducted as follows:
- Producing four different subsets
- Number of Input Files: 4500
- Total Input Size 1192.0GB
- Number of Records: 337,693,147
- Number of Columns: more than 1600 (with deeply nested schema)
- File Format: PARQUET
- File Compression: SNAPPY
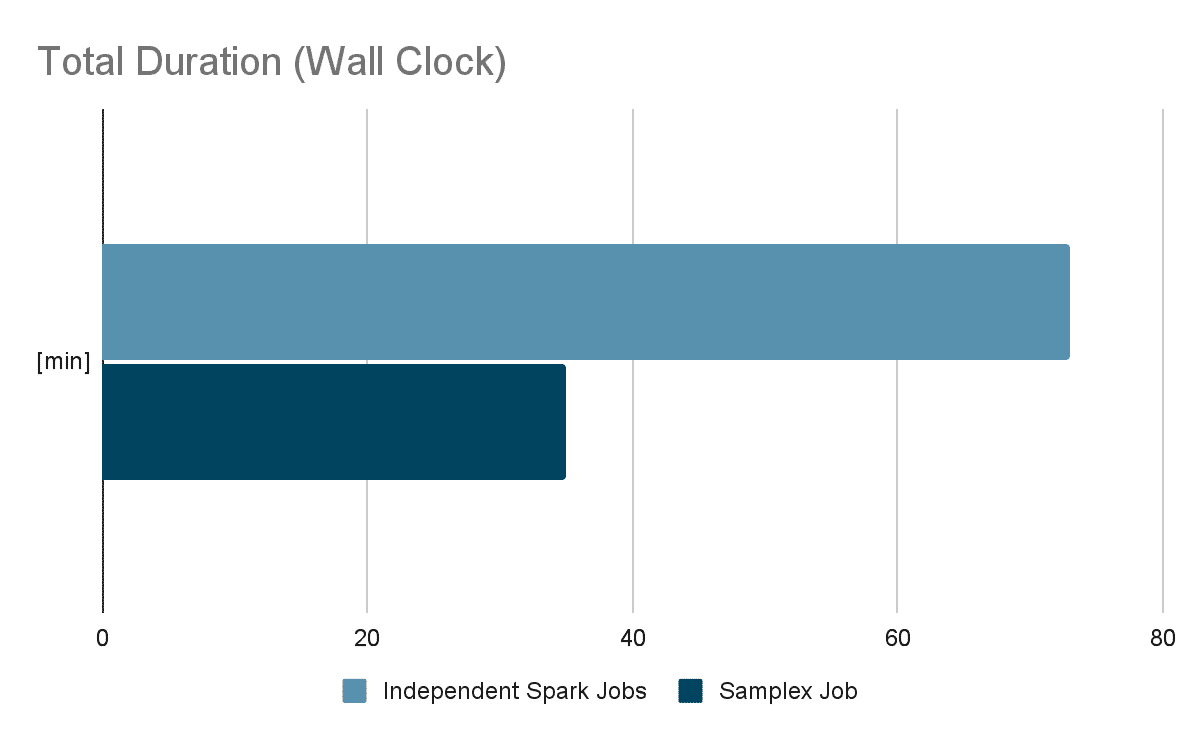
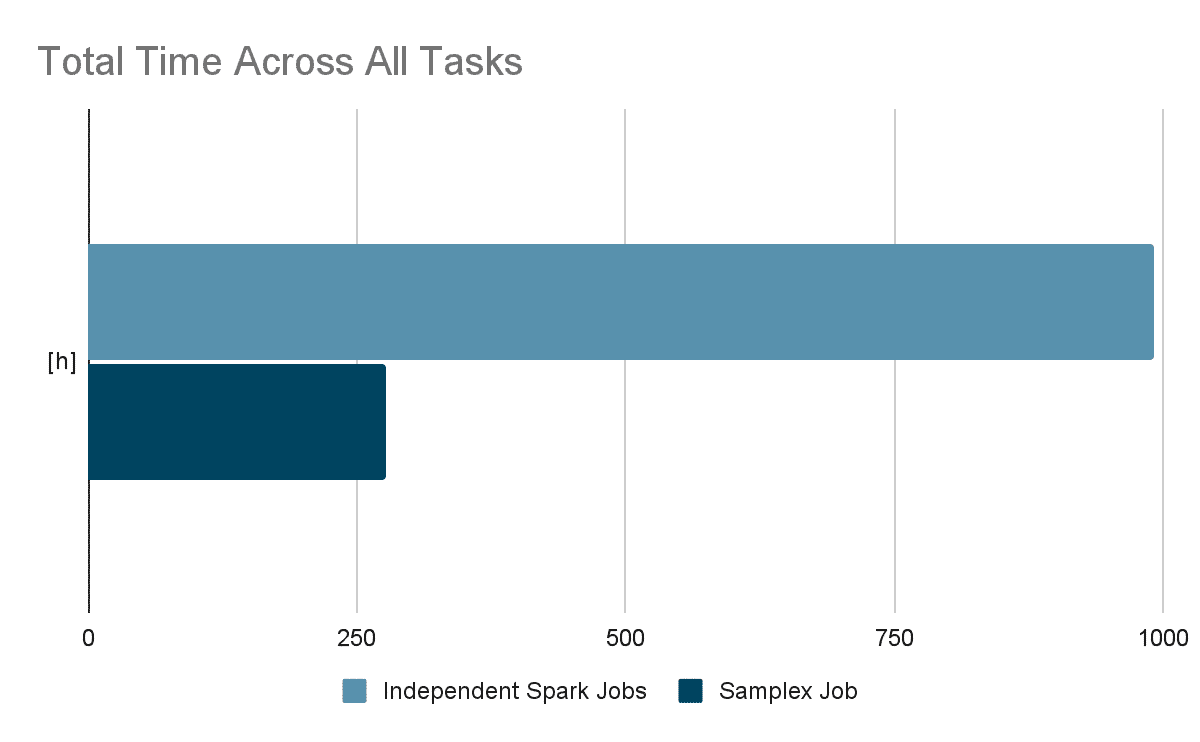
Conclusion
We love Spark, it is one of our core technologies at the Data Platform Group and a key technology in our stack since it’s early releases. It has never failed us. But with our scale, we often need to think outside the box, and find creative solutions to leverage the technology at hand and do things more efficiently. With over 700 compute nodes (~30000 cores) in our Spark clusters, we strive to maximize the efficiency of available resources. As new initiatives in R&D require more computing power, we always prefer to scale up, rather than blindly scale out before pursuing other alternatives.


