How do we do that? Keep reading to find out the secrets to how Taboola deploys and manages the thousands of servers that bring you recommendations every day.
Our deployment process pillars
At Taboola, we have two main process pillars we use in deployment to be efficient and ensure everything we release is high-quality. The pillars are divided into two main phases: pre-deployment and post-deployment.
What we do pre-deployment
We test every project, change, and code update pretty heavily at Taboola. We use a combination of automated, canary, AB, and side-by-side testing to ensure we only promote the highest quality code forward.
Automated testing
We use over 80,000 unit and end-to-end tests before each deployment. That’s 73,000 unit tests executed automatically before each deployment and more than 6,000 end-to-end tests developers execute before each merge to master.
Almost every change we make, or every line of new code we add, must be unit tested in Taboola. Our CI/CD platform runs most of these tests automatically when changes are pushed to any feature branch, but it’s not the only testing we do. Automated tests are a good first line of defense, but additional safeguards are needed.
Canary testing
Wouldn’t it be great to test a new code version on a small fraction of users or traffic, so you don’t disrupt anything else in production? And if this small test only took a few hours to run, making it easy to do? That’s what canary testing is all about (named after the mining tradition of using canary birds to detect carbon monoxide in underground mine shafts.)
Taboola’s infrastructure is ideal for canary testing since it allows us to:
- Deploy new code versions on a few servers that get only a small fraction of traffic (usually 1% of all traffic.)
- Rollback the new code easily if there are any issues, or once the time is done.
- Generate automatic comparison reports that identify latency, resource and bandwidth usage, errors, etc.
We enable canary testing at Taboola with a single click, making it an easy, efficient, and effective testing method for our developers.
A/B testing
To discover insights beyond the performance-related metrics revealed by canary testing and automated testing, Taboola uses A/B tests. After all, new code versions may perform well technically but don’t meet business requirements or objectives.
A/B testing uses higher traffic volumes and longer time frames to obtain the data needed to be statistically representative of business-level performance. For example, an AB test may use 10% of overall traffic and run for a full week or two instead of 1% of traffic and a few hours like canary testing.
It allows Taboola to measure both system-level performance and business-level performance at the same time. And that gives us a better understanding of how the change would affect business metrics like revenues, clicks, and so on.
Even though canary and A/B testing are similar, we don’t always do A/B testing because it takes longer (a few weeks versus a few hours.) We tend to do more canary tests than A/B tests, but it’s easy for us to do both when needed.
Side-by-side testing
Sometimes there are instances where automated, canary, and A/B testing will miss a coding error. For example, you might refactor a method to change its behavior but not its implementation and unintentionally introduce different outputs than was previously expected.
The previous testing types I mentioned may not catch the bug unless the new method throws more exceptions than usual. A/B testing might catch it if the bug impacts a business metric like revenue, but running one for a small refactoring change isn’t appropriate.
To catch these types of refactoring errors, we use side-by-side testing. It’s a type of testing with a short feedback loop and a high confidence level that can be done quickly.
It works like this:
- Duplicate the piece of code that needs to be refactored, whether it’s a method or an entire class.
- In the places where you invoked the old method, invoke both methods, the old and the new.
- Compare the results of the two methods, which should be the same since the behavior shouldn’t have been changed.
- Log every discrepancy between the two results.
- Deploy this feature branch to a few servers for a few hours, so enough traffic passes through it, and it can be properly analyzed.
- Look for discrepancies in the log files. If there are none, you’re good to go. If there are, fix them and repeat steps 1-6 until you find no discrepancies.
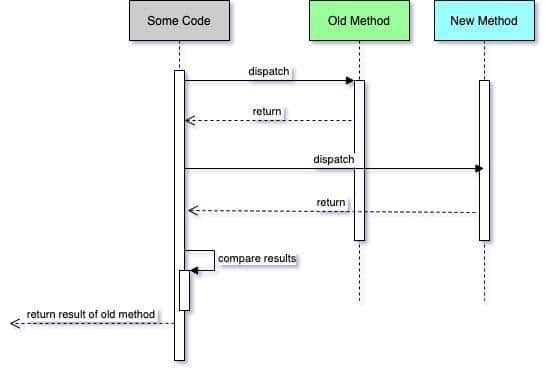
Side-by-side testing is a powerful tool but only works if:
- You’re refactoring a method
AND
- The refactored method is a query and not a command.
It won’t work if you’re changing or adding behaviors or refactoring commands.
What we do after deploying
A Taboola developer’s work is not done after pre-deployment testing and rolling out the change in production. Post-deployment, we do a few more tests and checks to ensure new changes aren’t causing new issues.
Feature flags
For whatever reason, if a new change is causing all sorts of problems in production, developers need a way to disable it quickly or roll back the code to a previous version.
Doing a full code rollback is time-consuming and costly since it affects thousands of servers and all traffic. In a large-scale operation as we have at Taboola, every second counts, so a full rollback isn’t always the best option. We use it only in very serious cases and really, only as a last resort.
The other option is to use feature flags to turn off any new changes in production code. We wrap the code changes in feature flags and keep track of which ones apply to the new code. That way, if something goes wrong, we can quickly turn off that feature flag alone without touching the rest of the production code.
(And before you ask, feature flags are a cumulative thing in code, so managing them in a large codebase as we have at Taboola is a big task and a topic for another post.)
Data verification
Another task we do after merging our code to master is tracking and verifying that our code didn’t cause any regressions in production. We don’t verify every change since we do so many every day, but we try to plan for the projects we know should be verified and what tools we’ll use to do that.
We store most of our raw data in BigQuery, Google’s cloud database, so we run queries there to verify the content we serve after deployment. But that’s not the only tool we use. We also use:
- Grafana to track unlimited metrics (CPU and memory load, total exceptions, number of requests, etc.) on various aspects of our systems to verify how our changes have affected different aspects of our systems.
- Tableau to generate reports on our business performance (number of page views, clicks, revenue, user engagement, active users, etc.)
- ELK to aggregate all server logs so we can search them to verify behaviors or investigate problems.
Final thoughts
Keeping large systems, as we have in Taboola, alive and healthy while deploying dozens of changes daily is challenging. The size of our infrastructure environment and developer teams means we need to work collaboratively, test frequently, and monitor our changes even after deployment.
Taboola developers have a strong sense of ownership of their work, so they don’t just merge their code and forget about it. They use and participate in the various testing layers we have before deployment to ensure their code doesn’t break anything.
They also actively monitor their changes and quickly act when alerted to a problem. Our post-deployment processes ensure developers know how to efficiently fix a problem, so it doesn’t significantly impact the rest of the environment or ecosystem.
And that’s how we keep the Taboola servers up and running efficiently while still deploying all the changes and enhancements our customers love.
There are more than 350 developers at Taboola, and each day dozens of changes are deployed to thousands of servers in seven different data centers around the world. Yet, our systems serve nearly 500,000,000 unique users every day and rarely experience downtime or a significant bug — all without any backend QA teams.